今天是 xAI 的大日子,伊隆・马斯克早早就宣布了会在今天发布 Grok 4 大模型,吸引了 AI 社区的广泛关注。尽管如此,也有人对 Grok 近期的「失控」表现抱有怀疑态度,他们或许更愿意看看直播中的笑话。
然而,谷歌并未因此而失去关注,反而接连对 Gemma 系列模型进行了更新。首先,谷歌发布了一系列用于健康 AI 开发的多模态模型 MedGemma,其中包含 4B 和 27B 两个大小的几个不同模型:MedGemma 4B Multimodal、MedGemma 27B Text 和 MedGemma 27B Multimodal。这些模型能够根据医疗图像和文本描述辅助诊断并提供医疗建议,整体表现相当优异。
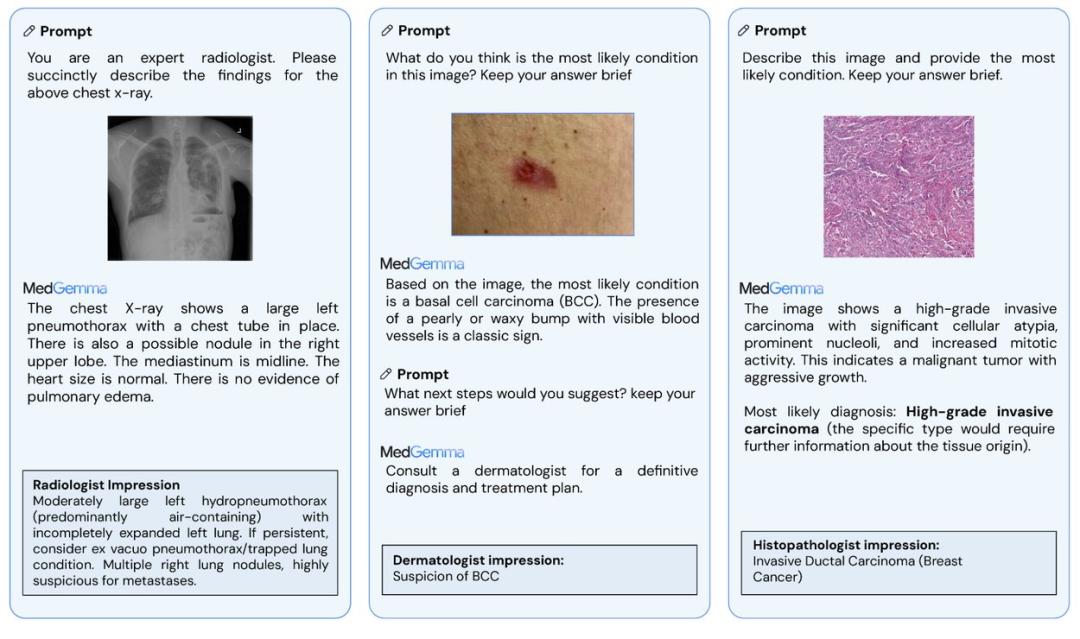
Hugging Face:https://huggingface.co/collections/google/medgemma-release-680aade845f90bec6a3f60c4

从名字也能看出,这个 Gemma 系列模型与 T5(The Text-to-Text Transfer Transformer)模型关系密切。T5 模型采用编码器-解码器(encoder-decoder)架构,不同于目前主流的仅解码器(decoder-only)架构。尽管仅解码器架构是当前 LLM 的主流,但编码器-解码器架构凭借高推理效率、设计灵活性以及更丰富的编码器表征,在某些实际任务中表现非常出色,如摘要、翻译、问答等。
正是出于这些优势,谷歌一直致力于编码器-解码器架构的研究,T5Gemma 便是其最新成果。具体来说,T5Gemma 使用了「适应(adaptation)」技术,将已经完成预训练的仅解码器模型转换为编码器-解码器架构。T5Gemma 基于 Gemma 2 框架,包含经过适应的 Gemma 2 2B 和 9B 模型,以及一组全新训练的 T5 尺寸模型(Small、Base、Large 和 XL),并提供了多种预训练和指令微调模型的变体版本。此外,T5Gemma 还提供了多种大小的编码器与解码器配置,以及使用 PrefixLM 或 UL2 这两个不同目标训练的模型。总的算下来,谷歌这一次发布了 32 个不同的 T5Gemma 模型。

Hugging Face:https://huggingface.co/collections/google/t5gemma-686ba262fe290b881d21ec86
Kaggle:https://www.kaggle.com/models/google/t5gemma
虽然 T5Gemma 的热度远不及 Grok 4,但依然获得了广泛好评。有人认为它是「LLM 时代编码器-解码器模型的强势回归」。但也有人对如此多的模型版本感到无奈,认为选择起来有些困难。



从仅解码器到编码器-解码器
对于 T5Gemma,谷歌研究的问题是:能否基于经过预训练的仅解码器模型构建顶级编码器-解码器模型?谷歌为此探索了上述的适应技术,其核心思想是使用已预训练的仅解码器模型的权重来初始化编码器-解码器模型的参数,然后通过基于 UL2 或 PrefixLM 的预训练进一步调整这些参数。

这种方法高度灵活,并且支持组合不同大小的模型。例如,可以将大型编码器与小型解码器(例如,9B 编码器与 2B 解码器)配对,创建一个「不平衡」模型。这使得在具体任务中可以更好地权衡质量与效率,如在摘要任务中,输入的深度理解比生成输出的复杂性更为重要。
实际上,谷歌已经在今年 4 月份发布了关于适应技术的论文。

论文标题:Encoder-Decoder Gemma: Improving the Quality-Efficiency Trade-Off via Adaptation
论文地址:https://arxiv.org/pdf/2504.06225
T5Gemma 的表现如何?
在谷歌的实验中,T5Gemma 模型的性能与仅解码器的 Gemma 模型相当,甚至更胜一筹。在多个基准测试(例如用于衡量所学习到的表征质量的 SuperGLUE)中,T5Gemma 几乎主导了质量-推理效率的帕累托边界。

在给定的推理计算水平下,编码器-解码器模型始终能提供更佳的性能,并且在一系列基准测试中引领质量-效率边界。这种性能优势不仅限于理论层面,还能转化为实际的质量和速度。在测量 GSM8K(数学推理任务)上的实际延迟时,T5Gemma 取得了显著的优势。例如,T5Gemma 9B-9B 的准确度高于 Gemma 2 9B,但延迟时间相似。更惊人的是,T5Gemma 9B-2B 的准确度显著高于 2B-2B 模型,但其延迟时间几乎与规模小得多的 Gemma 2 2B 模型相同。
编码器-解码器模型能否获得与仅解码器模型类似的能力?
谷歌的答案是:可以!T5Gemma 在指令微调前后都表现出色。经过预训练后,T5Gemma 在需要推理的复杂任务上取得了显著进步。例如,T5Gemma 9B-9B 在 GSM8K 上的得分比 Gemma 2 9B 模型高出 9 分以上,在 DROP(阅读理解任务)上的得分比 Gemma 2 9B 模型高出 4 分。这表明,通过适应初始化的编码器-解码器架构有潜力创建更强大、性能更佳的基础模型。

经过微调的 T5Gemma 模型在多个推理密集型基准测试上相比仅解码器的 Gemma 2 取得了显著的提升。这些预训练带来的基础性改进为指令微调后的更显著提升奠定了基础。例如,如果对比 Gemma 2 IT 与 T5Gemma IT,可以看到性能差距全面显著扩大。T5Gemma 2B-2B IT 的 MMLU 得分比 Gemma 2 2B 提高了近 12 分,其 GSM8K 得分也从 58.0% 提升至 70.7%。这表明,经过适应后的架构不仅可能提供更好的起点,还能够更有效地响应指令微调,最终构建出一个功能更强大、更实用的最终模型。

经过微调 + RLHF 后的模型的详细结果表明,后训练可以显著提升编码器-解码器架构的性能。你认为 T5Gemma 能带来编码器-解码器模型的复兴吗?
https://developers.googleblog.com/en/t5gemma/
https://x.com/googleaidevs/status/1942977474339496208
https://research.google/blog/medgemma-our-most-capable-open-models-for-health-ai-development/