34条核心洞察:破解新一代代码大模型强化学习的训练瓶颈
MicroCoder研究团队 供稿
前沿技术实验室 |
代码生成模型的迭代速度远超预期,然而一个关键问题正浮出水面:沿用传统数学推理的训练范式,如今在新一代强基模型上已逐渐失效。
训练动态的代际差异日益显著。主流强化学习方法与数据集,在面对如DeepSeek-Coder-V2、CodeQwen等新一代模型时,其性能提升曲线趋于平缓,甚至出现反向波动。
为此,微软亚洲研究院联手剑桥大学、普林斯顿大学的研究团队,系统性提出了MicroCoder项目框架。它并非单一的算法改进,而是从算法、数据、评估框架、训练经验四个维度协同发力,旨在重塑代码模型的强化学习训练生态。项目不仅公布了核心技术,更开源了从超过30组实验提炼的34条关键训练洞察。

强化学习曾被视为代码模型能力跃迁的终极路径。借鉴GRPO等在数学推理上的成功经验,社区普遍将其迁移至代码生成任务。初期效果显著,但近期却出现一个悖论:使用DeepCoder等主流数据集训练最新顶级模型,性能提升几乎停滞;而同一方法在上一代模型(如CodeLlama)上却依然有效。
研究发现,根源在于能力断层:当前顶尖代码模型的基础能力已超越主流训练集的题目难度,题目变得过于“简单”,无法提供有效的学习梯度。与此同时,新一代模型在训练中表现出持续增长的输出长度趋势,而旧模型输出则趋于稳定甚至缩短。两者训练动态已本质不同,旧范式自然失效。
MicroCoder直面此瓶颈,其四大组件构成完整解决方案:MicroCoder-GRPO算法(改进了GRPO以适应新动态)、MicroCoder-Dataset数据集(高难度真实竞赛题)、MicroCoder-Evaluator评估框架(高容错、高效率),以及基石般的34条训练经验库。
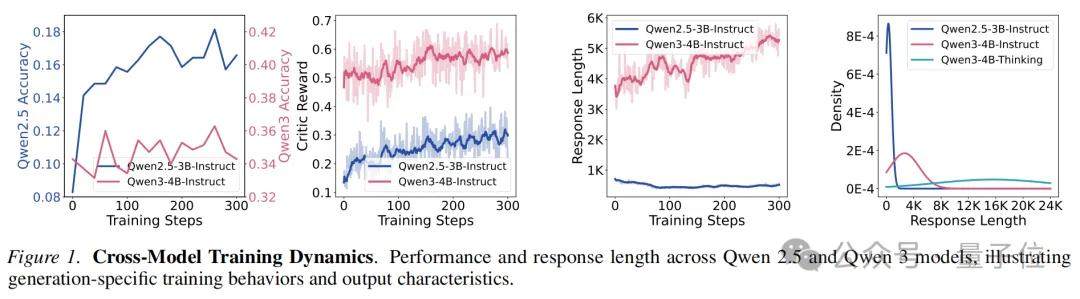
算法革新:三项关键修改应对新动态
MicroCoder-GRPO在标准GRPO基础上引入三项针对性修改。
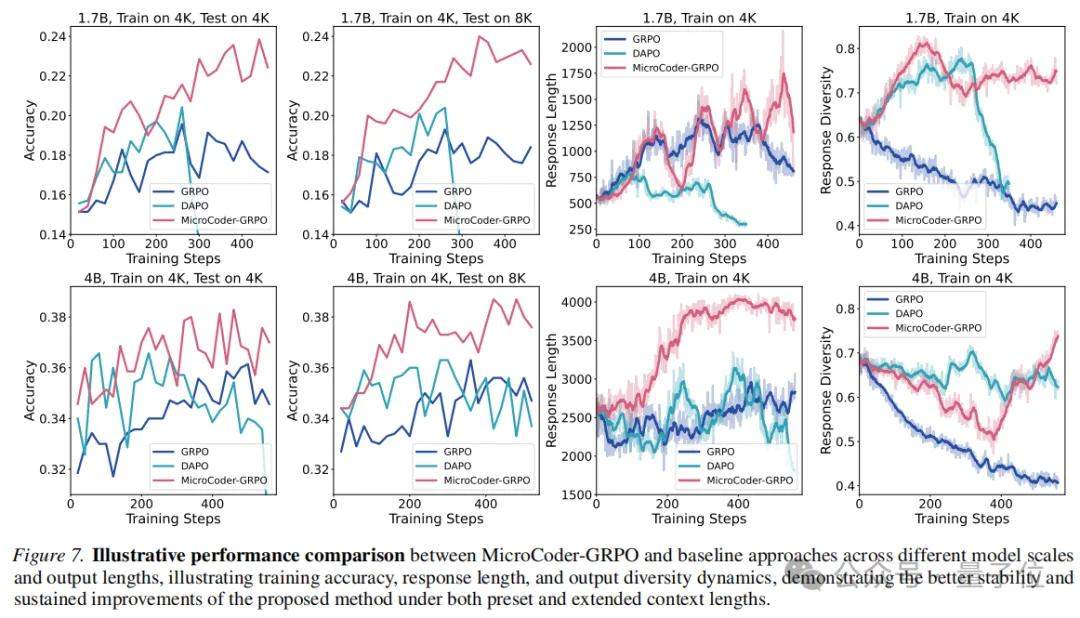
1. 条件截断掩码:传统“全部掩码”策略(对达到最大长度的输出全部置零)会抑制模型的长输出潜力,导致长度增长过快后性能坍缩。MicroCoder提出精细化条件:仅对同时满足“达最大长度、答案正确、无尾部重复、且按概率随机选择”的输出进行掩码。实验证明,此策略既解锁了长序列生成,又保持了训练稳定,收敛性能超越无掩码和全掩码方案。
2. 多样性驱动的动态温度:输出多样性是训练稳定的关键指标。研究发现,在固定温度下,多样性最终会收敛到相近水平;若初始多样性与收敛值差距过大,易导致训练失败。传统预设温度对新一代模型而言偏低。MicroCoder的方案是:测量模型初始输出的多样性趋势,据此动态确定训练温度,确保平稳收敛。此外,“先低温后高温”的分阶段策略优于固定温度,但需避免温度渐变,即使是短暂过渡也可能破坏多样性。
3. 去除KL散度,调高裁剪比率:直接沿用数学推理中DAPO的KL散度约束,会持续压制输出多样性并限制长度增长,导致性能“先升后降”。MicroCoder将KL散度权重设为0,并采用更高的裁剪比率。去除KL约束后,模型获得了持续的性能提升曲线。
三项修改协同作用下,MicroCoder-GRPO在最新代码测试集(如LiveCodeBench)上显著超越DAPO基线,且在延长测试上下文时优势更为明显。
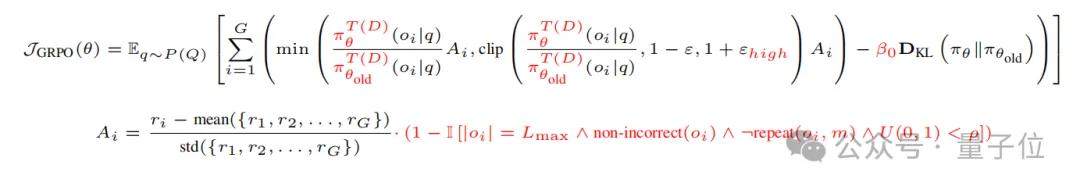
数据重构:构建高难度真实竞赛题库
算法需匹配数据。MicroCoder-Dataset的构建遵循四阶段流程:收集(从Codeforces、LeetCode等多平台获取真实竞赛题)、处理(统一语言、去噪、格式标准化,并由LLM生成/筛选测试用例)、筛选(实施软硬约束及核心的“自适应难度过滤”)、验证(人工抽查确保质量)。
其核心创新在于五维难度评估矩阵:由LLM对每题进行三次独立打分(基于Bloom分类法、McCabe复杂度等理论),评估维度侧重推理与编程能力本身,而非语义理解。随后以模型实际通过率为基准校准分数,在LiveCodeBench上划分易、中、难区间。过滤后,简单题占比降至25%以下,困难题占比超50%。
最终数据集包含超过13,000道经严格筛选的真实竞赛题,全部源自实际平台而非LLM生成,与主流测试集无重合。
效果验证:在相同训练步数下,使用MicroCoder-Dataset取得的性能增益是DeepCoder的3倍。以DAPO训练最新模型为例,在LeetCode测试集上整体提升约6.0个百分点,且难度越高,增益越显著。
评估演进:高容错验证链减少训练噪声
评估准确性直接决定强化学习信号质量。LiveCodeBench原版评估器采用严格精确匹配,易将格式正确但略有差异的答案(如列表与元组、浮点精度偏差)判为错误,产生噪声干扰训练。
MicroCoder-Evaluator设计了一套由6-7种方法组成的回退验证链:依次尝试自动类型转换(列表、元组、字符串、集合等)、浮点近似比较、多行分割与空白规范化等。单方法失败后自动切换,全程高容错。
对比显示,MicroCoder-Evaluator将评估准确率提升约25%,更精准识别正确解法变体。训练曲线表明,使用它的模型在早期获得更可靠反馈,最终测试准确率更高、收敛更快。此外,通过优化并行策略,每个训练步骤的执行速度提升约40%。
经验开源:34条洞察覆盖七大维度
MicroCoder项目通过大量受控实验,系统记录了现代代码模型强化学习的完整经验,覆盖七大核心维度:
- 代码评估器:评估准确性尤其在早期阶段影响巨大。高容错评估提供可靠反馈,防止次优收敛。原版严格匹配策略会产生误判噪声。
- 温度动态:模型对温度的鲁棒性随训练增强。不同温度下输出多样性最终收敛到相近水平。初始多样性低于预期易致训练失败。
- 训练数据:数据难度决定泛化能力。仅在简单集上表现好不代表测试集好。更难的问题促使更长解题路径,输出长度增长更快最终更长。
- 上下文长度与扩展:更长的最大输出关联更高的最终准确率、更快的输出增长和更高的多样性。早期阶段的短输出限制会产生“不可逆”影响,后续增大上下文也无法完全恢复性能。
- 截断掩码策略:掩码比例平衡训练速度与峰值性能。高比例更快达初始峰值,低比例延长上升期并达更高峰值。30%条件掩码在长度增长上接近全掩码,同时显著优于其稳定性。
- 批大小与在线训练:小批大小行为接近在线训练,加快多样性收敛但影响稳定;大批大小接近离线训练,稳定性更强。最优选择位于两者平衡点。
- KL散度与裁剪比率:标准KL散度持续影响多样性并限制长度增长,导致“性能先涨后跌”。去除KL散度是支持长期持续提升的关键条件。
完整的34条洞察已在项目主页的MicroCoder-Insights博客中详尽列出,是目前该领域最完整的训练经验库之一。
分析:代际断层的启示与开源价值
MicroCoder的工作揭示了一个深层趋势:代码大模型的强化学习训练,已不能简单套用数学推理任务的成熟经验。模型能力的代际跃迁导致了训练动态的质变,这要求算法、数据与评估范式必须同步升级。
其方法论价值超出代码生成本身。例如,“条件截断掩码”与“多样性驱动温度”为解决强化学习中“稳定性与探索性”的经典矛盾提供了新思路。而超过三十组实验沉淀的34条经验,为社区提供了可复现、可验证的宝贵知识,极大降低了后续研究的试错成本。
这一项目标志着代码模型后训练研究从“经验迁移”走向“范式重构”的新阶段。
研究团队

MicroCoder第一作者李宗谦,剑桥大学自然语言处理博士生,剑桥信托学者,曾于微软亚洲研究院完成系列工作。其在神经信息处理系统大会(NeurIPS)、计算语言学协会年会(ACL)等顶级会议发表多篇一作论文,对大语言模型的前沿训练技术有持续深入的贡献。
项目资源
项目主页:https://github.com/ZongqianLi/MicroCoder
算法论文:https://arxiv.org/abs/2603.07777
数据集论文:https://arxiv.org/abs/2603.07779
训练经验博客:https://github.com/ZongqianLi/MicroCoder/blob/main/MicroCoder-Insights.md