开发能够像人类一样进行推理的灵活机器学习模型的关键可能不是向他们提供大量的训练数据。相反,一项新的研究表明,它可能归结为 如何 他们受过训练。这些发现可能是朝着更好、更不容易出错的人工智能模型迈出的一大步,并可能有助于阐明人工智能系统和人类如何学习的秘密。
人类是混音大师。当人们了解一组成分之间的关系时,例如食品成分,我们可以将它们组合成各种美味的食谱。通过语言,我们可以破译以前从未遇到过的句子,并撰写复杂的原创反应,因为我们掌握了单词的潜在含义和语法规则。从技术上讲,这两个例子是“组合性”或“系统概括”的证据——通常被视为人类认知的关键原则。“我认为这是智力最重要的定义,”约翰霍普金斯大学(Johns Hopkins University)的认知科学家保罗·斯摩棱斯基(Paul Smolensky)说。“你可以从了解部分到处理整体。”
真正的组合性可能是人类思维的核心,但机器学习开发人员几十年来一直在努力证明人工智能系统可以实现它。一个 35岁的论点 已故哲学家和认知科学家杰里·福多(Jerry Fodor)和泽农·皮利辛(Zenon Pylyshyn)认为,该原理对于标准神经网络来说可能是遥不可及的。今天的生成式 AI 模型可以模仿组合性,对书面提示产生类似人类的响应。然而,即使是最先进的模型,包括 OpenAI 的 GPT-3 和 GPT-4, 仍然不足 这种能力的一些基准。例如,如果你问 ChatGPT 一个问题,它最初可能会提供正确的答案。但是,如果您继续向它发送后续查询,它可能无法保持主题或开始自相矛盾。这表明,尽管模型可以从训练数据中反刍信息,但它们并没有真正掌握它们产生的句子背后的含义和意图。
“这项研究开辟了重要的领域,”斯摩棱斯基说,他没有参与这项研究。“它完成了我们一直想完成但以前没有成功的事情。”
该语言由无意义的单词(如“dax”、“lug”、“kiki”、“fep”和“blicket”)组成,这些单词“翻译”成一组彩色的点。这些发明的单词中有些是符号术语,直接表示某种颜色的点,而另一些则表示改变点输出顺序或数量的功能。例如,dax 表示一个简单的红点,但 fep 是一个函数,当与 dax 或任何其他符号词配对时,将其对应的点输出乘以 3。因此,“dax fep”将转化为三个红点。然而,人工智能训练没有包含这些信息:研究人员只是向模型提供了一些与相应的点配对的无意义句子的例子。
从那里开始,研究作者促使模型产生自己的一系列点来响应新短语,并根据人工智能是否正确遵循了语言的隐含规则对人工智能进行评分。很快,神经网络就能够按照无意义语言的逻辑做出连贯的响应,即使被引入新的单词配置也是如此。这表明它可以“理解”语言的虚构规则,并将它们应用于它没有接受过训练的短语。
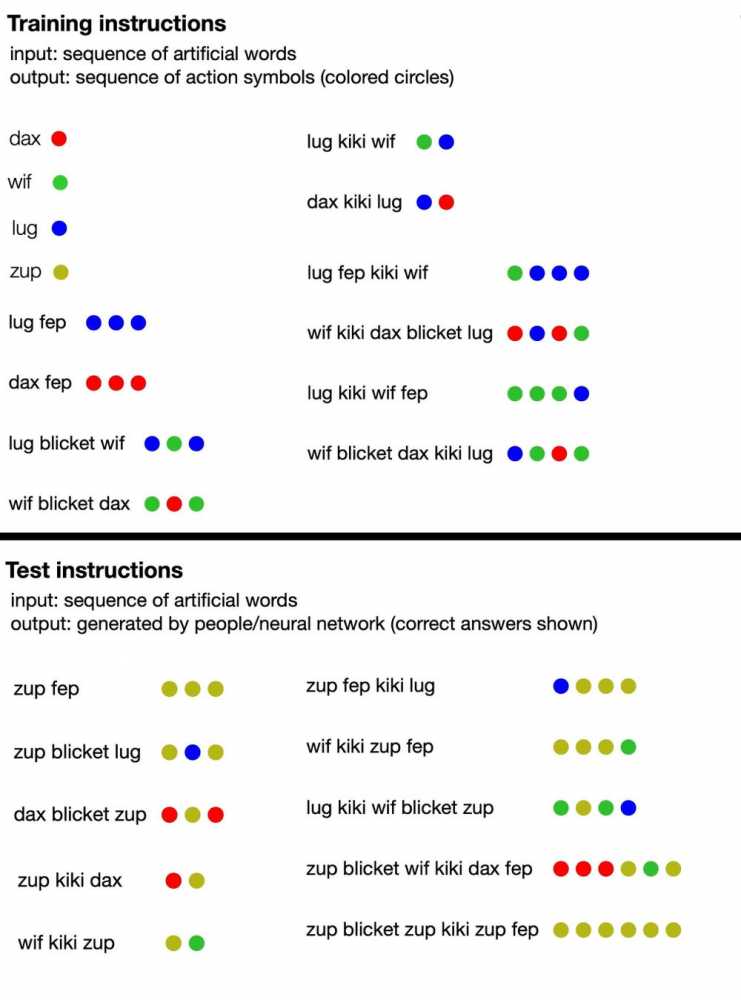
此外,研究人员还对 25 名人类参与者测试了他们训练的 AI 模型对虚构语言的理解。他们发现,在最好的情况下,他们优化的神经网络响应100%准确,而人类答案在81%的时间内是正确的。(当该团队向 GPT-4 提供语言的训练提示,然后向它询问测试问题时,大型语言模型的准确率仅为 58%。经过额外的培训,研究人员的标准变压器模型星它很好地模仿了人类的推理,以至于犯了同样的错误:例如,人类参与者经常错误地假设特定单词和点之间存在一对一的关系,即使许多短语没有遵循这种模式。当模型被输入这种行为的例子时,它很快就开始复制它,并以与人类相同的频率犯错误。
鉴于其体积小,该模型的性能尤为出色。“这不是一个在整个互联网上训练的大型语言模型;这是一个为这些任务训练的相对较小的变压器,“麻省理工学院的计算机科学家Armando Solar-Lezama说,他没有参与这项新研究。“有趣的是,尽管如此,它仍然能够表现出这种概括。这一发现意味着,与其将更多的训练数据推入机器学习模型中,不如为人工智能算法提供相当于重点语言学或代数类的算法。
Solar-Lezama表示,从理论上讲,这种训练方法可以为更好的AI提供另一种途径。“一旦你在整个互联网上喂养了一个模型,就没有第二个互联网可以喂养它来进一步改进。因此,我认为迫使模型更好地推理的策略,即使在合成任务中,也可能会对未来产生影响,“他说,但需要注意的是,扩大新的训练协议可能会面临挑战。同时,Solar-Lezama认为,这种对较小模型的研究有助于我们更好地理解神经网络的“黑匣子”,并可以揭示大型人工智能系统的所谓涌现能力。
斯摩棱斯基补充说,这项研究以及未来的类似工作也可能促进人类对自己思想的理解。这可以帮助我们设计系统,最大限度地减少我们物种容易出错的倾向。
然而,目前,这些好处仍然是假设的,并且有几个很大的局限性。“尽管取得了成功,但他们的算法并不能解决所有提出的挑战,”卡内基梅隆大学的计算机科学家Ruslan Salakhutdinov说,他没有参与这项研究。“它不会自动处理未经实践的泛化形式。换句话说,训练协议帮助模型在一种类型的任务中表现出色:用假语言学习模式。但是,给定一个全新的任务,它无法应用相同的技能。这在基准测试中很明显,该模型无法管理更长的序列,也无法掌握以前未引入的“单词”。
至关重要的是,每位专家 《科学美国人》 Spoke With指出,能够有限泛化的神经网络与通用人工智能的圣杯有很大不同,后者在大多数任务中,计算机模型都超过了人类的能力。你可以争辩说,“这是朝着这个方向迈出的非常、非常、非常小的一步,”Solar-Lezama说。“但我们并不是在谈论人工智能本身获得能力。
从与人工智能聊天机器人的有限互动中,可以呈现出一种超能力的错觉,以及大量流传的炒作,许多人可能夸大了神经网络的力量。“有些人可能会感到惊讶,像 GPT-4 这样的系统很难开箱即用地完成这些语言泛化任务,”Solar-Lezama 说。这项新研究的结果虽然令人兴奋,但可能会无意中作为现实的检验。“跟踪这些系统能够做什么非常重要,”他说,“但也要跟踪它们不能做什么。
本文由AI快讯网译自:AIMagazine