AI浪潮席卷全球,各国科技巨头纷纷在通用大模型领域展开激烈角逐。在此背景下,国内科技公司在基础大模型研发上的进展尤为引人关注。近日,腾讯在其自研的AI大模型领域揭开了新篇章。
腾讯自主研发的通用大模型“混元2.0”(Tencent HY2.0)已正式面向公众开放。与此同时,备受瞩目的DeepSeek V3.2模型也在逐步融入腾讯的生态体系。目前,这两款强大的模型已率先在腾讯的AI原生应用如“元宝”及“马”等产品中落地,为用户提供更加智能化的服务体验。而腾讯云方面,也同步开放了相关模型的API接口及平台级服务,加速AI能力的普惠化进程。
此次发布的腾讯混元2.0,采用了业界领先的MoE(Mixture of Experts)架构,其参数总量高达406B,激活参数则为32B,展现了其强大的模型规模。更令人瞩目的是,它支持长达256K的超长上下文窗口,这一特性极大地拓展了模型在处理长文本、复杂对话等场景下的能力边界。在推理能力和运行效率方面,混元2.0的表现已处于行业领先水平。

与前代版本(Hunyuan-T1-20250822)相比,混元2.0在预训练数据和强化学习策略上均进行了显著升级。在数学、科学、代码生成以及指令遵循等一系列复杂推理场景下,其整体性能在国内处于第一梯队。同时,模型的泛化能力也得到了大幅提升,能够更好地适应多样化和新颖的任务需求。
特别是在数学和科学知识推理方面,混元2.0通过引入高质量数据进行大规模回滚(Large Rollout)强化学习,显著增强了其逻辑推理和问题解决能力。在国际数学奥林匹克(IMO-AnswerBench)和哈佛-MIT数学竞赛(HMMT2025)等权威测试中,均取得了优异的成绩。借助于高质量预训练数据的赋能,模型在“人类最后的考试”(Humanity’s Last Exam, HLE)等考验知识深度的任务,以及ARC AGI的泛化能力评测中,也实现了长足的进步。
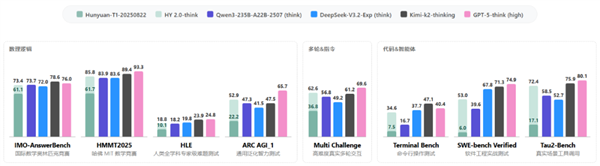
在指令遵循和长文本多轮对话能力上,混元2.0通过重要性采样校正(importance sampling correction)有效缓解了训练与推理阶段可能出现的指令不一致问题,实现了高效且稳定的长窗口强化学习。此外,模型充分利用了多样化的可验证任务沙箱(verifiable task sandboxes)以及基于评分标准(scoring criteria)的强化学习方法,显著提升了在Multi Challenge等复杂指令遵循和多轮对话任务中的表现。
在代码生成和智能体(Agent)能力方面,腾讯构建了可扩展的可验证环境(scalable verifiable environment)以及高质量的合成数据,大幅提升了模型在Agentic Coding和复杂工具调用场景下的实战能力。在面向实际应用场景的智能体任务评测中,如SWE-bench Verified和Tau2-Bench等,混元2.0实现了质的飞跃。




