< img id=”wx_img” src=” width=”400″ height=”400″>
<!--摘要样弍-->
<blockquote>前沿观察组 发自 科技园区
Tech Insight | Research
【行业前瞻】在全球半导体存储周期见底的大背景下,一场纯算法的发布会竟能引发硬件巨头股价剧烈波动,这本身就是一个值得深思的信号。
当学术会议ICLR的焦点不再仅仅是模型架构的演进,而是直接触动了产业链的定价逻辑时,我们或许正站在一个新的拐点。
两家存储芯片巨头股价大跌,没有财报暴雷,没有供应链断裂,只是谷歌展示了一篇即将在 ICLR 2026 正式亮相的论文。
这并非市场过度反应。从算力成本模型来看,KV Cache 占据显存的比例已经超过了 70%,任何能够压缩显存占用的技术突破,本质上都是对硬件投资回报率的直接重塑。
谷歌研究院推出TurboQuant压缩算法,把 AI 推理过程中最吃内存的 KV cache压缩至少 6 倍,精度零损失。
市场的解读简单粗暴,长上下文 AI 推理以后不需要那么多内存了,利空内存。
但更深层的逻辑是,这意味着推理的边际成本可能大幅下降,大模型服务有望从“资源密集型”转向“应用密集型”,进而改变整个 AI 生态的价值分配。

网友纷纷表示,这不就是美剧《硅谷》里的 Pied Paper?
这是一个关于技术奇点的隐喻。在商业世界里,压缩比率的突破往往意味着垄断壁垒的崩塌,或者新巨头的崛起。
Pied Piper 是 2014 年开播的 HBO 经典美剧《硅谷》里的虚构创业公司,核心技术就是一种“近乎无损的极限压缩算法”。
2026 年,类似的算法在现实世界居然成真了。
**客观分析:** 这种从 fiction 到 reality 的跨越,往往伴随着基础设施的代际更迭。TurboQuant 不仅仅是算法的胜利,更是对现有内存架构利用率的极限挑战。
要理解 TurboQuant 为什么重要,先得理解它解决的是什么问题。
AI 大模型推理时处理过的信息会临时存在KV Cache,方便后续快速调用,不用每次从头算起。
问题是随着上下文窗口越来越长,内存消耗急剧膨胀。KV cache 正在成为 AI 推理的核心瓶颈之一。
在此背景下,传统的 HBM(高带宽内存)成本高昂,TurboQuant 若能降低显存需求,等于变相提升了单位算力的性价比,这对企业级部署具有战略意义。
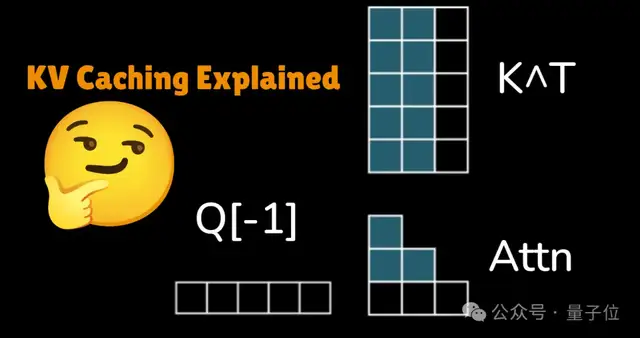
传统的解决思路是向量量化,把高精度数据压成低精度表示。
但尴尬的是,大部分量化方法本身也需要存储额外的“量化常数”,每个数字要多占 1 到 2 个 bit。
TurboQuant 用两个改动把这个额外开销干到了零。
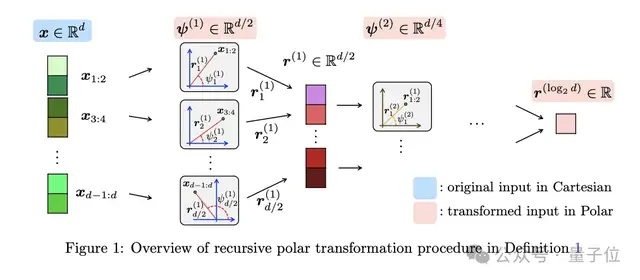
PolarQuant(极坐标量化):
不用传统的 X、Y、Z 坐标描述数据,转而用极坐标“距离 + 角度”。
谷歌团队发现,转换后角度的分布非常集中且可预测,根本不需要额外存储归一化常数。
就像把“往东走 3 个路口,往北走 4 个路口”压缩成”朝 37 度方向走 5 个路口”。
信息量不变,描述更紧凑,还省掉了坐标系本身的开销。
QJL(量化 JL 变换):
把高维数据投影后压缩成 +1 或 -1 的符号位,完全不需要额外内存。TurboQuant 用它来消除 PolarQuant 压缩后残留的微小误差。

两者组合后 PolarQuant 先用大部分 bit 容量捕捉数据的主要信息,QJL 再用 1 个 bit 做残差修正。
最终实现 3-bit 量化,无需任何训练或微调,精度零损失。
这里的**无需训练**尤为关键。这意味着该算法具备极强的通用性,不需要厂商针对特定模型进行漫长的适配周期,降低了落地门槛。
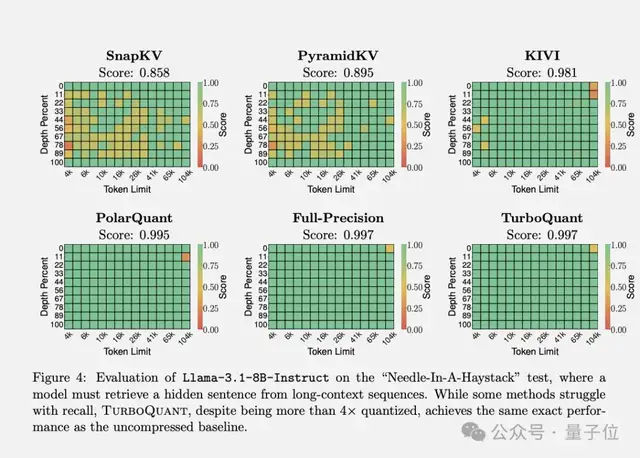
谷歌团队在 Gemma 和 Mistral 等开源模型上,跑了主流长上下文基准测试,覆盖问答、代码生成、摘要等多种任务。
在“大海捞针”任务上,TurboQuant 在所有测试中拿下完美分数,同时 KV cache 内存占用缩小了至少 6 倍。
PolarQuant 单独使用,精度也几乎无损。
速度提升同样显著。在英伟达 H100 GPU 上,4-bit TurboQuant 计算注意力分数的速度,比 32-bit 未量化版本快了 8 倍。
不只是省内存,还更快了。
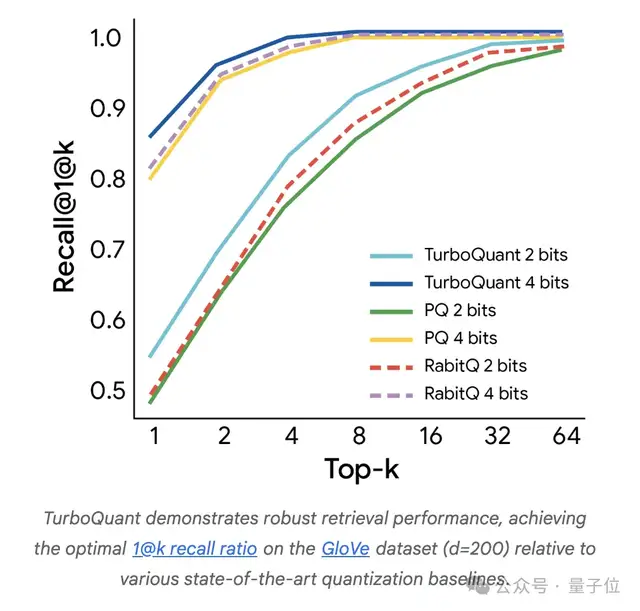
在向量搜索领域,TurboQuant 同样超越了现有最优量化方法的召回率,而且不需要针对具体数据集做调优,也不依赖低效的大码本。
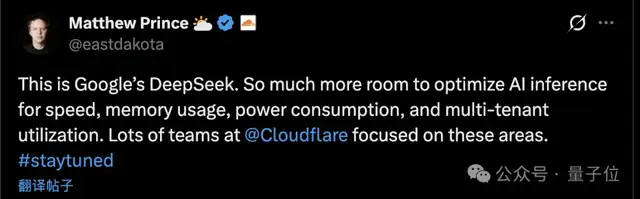
Cloudflare CEO 评价“这是谷歌的 DeepSeek 时刻”。
他认为 DeepSeek 证明了用更少的资源也能训出顶尖模型。
TurboQuant 的方向类似,用更少的内存,也能跑同样质量的推理。
谷歌表示,TurboQuant 除了可以用在 Gemini 等大模型上,同时还能大幅提升语义搜索的效率,让谷歌级别的万亿级向量索引查询更快、成本更低。
不过 TurboQuant 目前还只是一个实验室成果,尚未大规模部署。
更关键的是,它只解决了推理阶段的内存问题。而 AI 训练环节完全不受影响。
【深度分析】:
TurboQuant 的发布,实际上揭示了 AI 下半场的战争逻辑正在悄然切换。过去两年是“训练为王”,各大厂比拼算力集群的规模;未来两年随着推理需求的爆发,将是“效率决胜”。
如果该算法能顺利工程化,将直接改变存储芯片的需求曲线。DRAM 厂商的短期增长预期可能承压,但长期来看,推理次数的指数级增长可能会由“量”来弥补“价”的下滑,这或许是一个从存量优化到增量爆发的转折。
对于开发者社区而言,这意味着跑满长上下文模型的门槛将大幅降低,更多小型化的高效模型可能涌现,不再盲目追求参数巨量,而是追求架构的极致精简。
论文地址:
<!--版权声明-->
</div>




