如果不是谷歌的TurboQuant算法引发了这场风波,或许我们仍未意识到,自己已经默默忍受AI对硬件资源的“饕餮”如此之久。
3月24日,谷歌研究院(Google Research)高调发布了一项名为TurboQuant的极端压缩技术。据称,该算法能显著降低大语言模型推理时所需的显存消耗。

谷歌在介绍中直指其核心突破:该技术能将大模型推理时的KV缓存(KV cache)内存占用压缩至平均3.5比特,实现约6倍的压缩率,且几乎不影响模型精度。
简而言之,这项技术宣称可大幅降低运行AI大模型的硬件门槛。以往需要600GB显存的任务,应用TurboQuant后可能仅需100GB。这对于被高昂算力成本困扰的AI行业而言,无疑像是一剂“强心针”。
消息一出,资本市场迅速反应。次日,几家头部存储芯片制造商的股价应声下跌。美光科技(Micron)股价下跌3.4%,市值蒸发约151.66亿美元;西部数据(Western Digital)与闪迪(SanDisk)也分别出现不同程度下跌。市场担心,若AI对内存的依赖因算法突破而降低,存储硬件的长期需求增长故事将面临挑战。
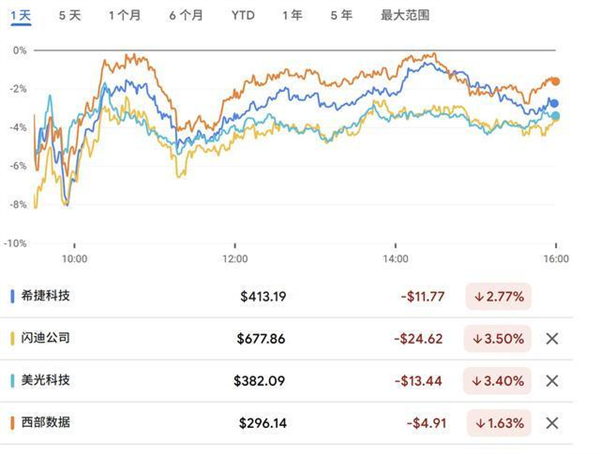
图表来源:新浪财经
AI界随即沸腾,各方开始热烈讨论TurboQuant的技术原理及其可能带来的产业变革。甚至Cloudflare的CEO也发文,将其类比为“谷歌的DeepSeek时刻”,意指这可能是一次改变游戏规则的技术发布。

许多普通消费者也为此感到兴奋,期待硬件成本下降能带来更实惠的电子产品。然而,这场技术狂欢并未持续太久。

剧情在3月27日晚发生戏剧性逆转。苏黎世联邦理工学院博士后研究员高健扬在多个平台公开指控,支撑TurboQuant宣传的学术论文存在严重学术不端行为。

高博士指出,TurboQuant的核心算法与其团队早先提出的RaBitQ高度相似,均基于“随机旋转加JL变换”方法。关键证据在于,谷歌论文的第二作者曾在2025年1月通过邮件向高博士求助,询问如何正确运行RaBitQ的开源代码。这引发了关于原创性与学术诚信的严重质疑。

更严重的问题在于性能对比的公平性。指控显示,谷歌团队在论文中为突显TurboQuant的优势,采用了不公正的 benchmarking(基准测试)方法:他们使用强大的A100 GPU测试自家算法,却用关闭了多线程的CPU来运行对比算法RaBitQ。此外,他们未使用高博士团队高度优化的C++开源代码,而是自行翻译了一个非优化的Python版本进行测试,这进一步扭曲了性能对比结果。


这些关键的软硬件环境差异在最终论文中均未提及。这篇存在争议的论文后被ICLR 2026会议接收,并经由谷歌研究院的官方渠道进行大规模宣传,最终引发了存储市场的震荡。
随着学术争议的曝光,市场情绪开始回调。在相关回应出现的当天,美光科技股价小幅回升。这场由一篇论文引发的百亿美元市值波动,暴露了市场在AI热潮中的脆弱性与信息不对称。

客观来看,此次事件折射出几个深层次问题:
首先,是技术炒作与产业现实之间的脱节。一项尚未经过严格同行评议和产业验证的实验室算法,仅因出自巨头之手,便能通过社交媒体迅速放大,影响百亿级资本市场。这提醒我们,在面对颠覆性技术宣称时,仍需保持审慎,辨别其技术成熟度与商业化距离。
其次,事件背后反映了普遍的“AI成本焦虑”。AI大模型,尤其是长上下文模型,对内存带宽和容量的需求近乎贪婪,直接推高了云端算力成本和终端硬件价格。正如“杰文斯悖论”所提示的,效率提升可能刺激更大规模的需求。因此,市场对于任何能降低AI“胃口”的技术都抱有极大期待,这种情绪有时会压倒对技术细节的理性核查。

再者,当前AI的社会效益与成本分摊存在错位。一方面,AI的实际生产力提升仍集中在特定行业与场景,距离普惠大众尚有距离;另一方面,其引发的硬件需求已传导至消费电子领域,间接由全社会承担成本。这种矛盾加剧了公众对“降本”技术的渴望。
最后,该事件也凸显了学术伦理与产业宣传之间的边界问题。学术界追求严谨、公开与传承,而企业宣传则倾向于突出优势、塑造影响力。当一篇存在学术争议的论文被用作大规模市场宣传的基石时,其产生的误导效应可能远超学术范畴。
这场“TurboQuant乌龙”或许终将平息,但它留给行业的思考是长远的:在AI狂飙突进的时代,我们更需要建立理性的评估体系、健康的学术交流环境,以及对技术宣称去伪存真的能力。毕竟,真正的技术进步,从来不是靠一场喧嚣的资本震动来定义,而是取决于它能否经得起时间的检验,并最终造福于产业与社会。
图表来源“锌刻度”李觐麟
图表来源:Anthropic





