当前大模型技术的发展,正经历从“上下文窗口竞赛”向“外部记忆体系”构建的关键转折。单纯依赖扩大 Context Window 并不能彻底解决长程依赖与知识持久化的问题,如何让 AI 具备类似人类的海马体功能,实现信息的精准存储、检索与推理,已成为行业公认的下一次突破点。
在这一背景下,传统的 RAG(检索增强生成)架构逐渐显露出瓶颈。近期,一项来自中国年轻团队的开源项目引起了技术社区的广泛关注,其提出的图路由架构为 AI 记忆引擎提供了新的解题思路。
唯一原生支持指代消解,Benchmark 现象级领先
Claude Code 源码泄漏的余波,还在 AI 圈持续发酵。
说起来还挺反常,Claude 几乎 Contribute 了所有 RAG 记忆项目,结果泄露的代码却显示——它自己压根没在用主流的 RAG 技术??
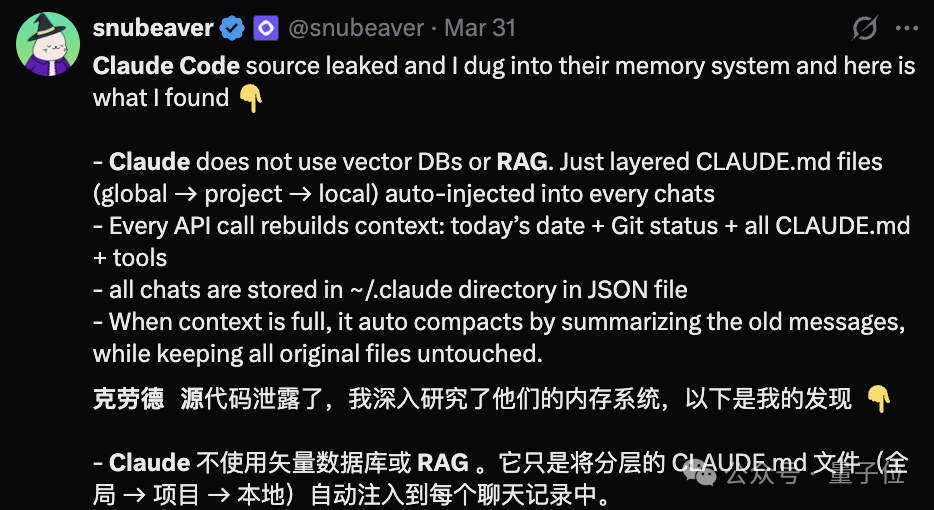
这就很矛盾了,Anthropic 在官方文档和技术博客里,一直明确提到支持 RAG 检索。

而它“弃用”传统 RAG 的玩法,其实恰恰也说明了一个问题:现有的 RAG 解决方案,性能并没有达标。
从 2023 年起,混合检索就成了记忆引擎的标配逻辑,向量 + 关键词、加权排序……这些套路不断迭代。
但随着 AI 记忆场景越来越复杂,传统 RAG 的瓶颈也彻底暴露,明明叫记忆引擎,却还在干着搜索引擎的活儿,只会匹配相似文本,做不到真正的理解,更谈不上联想推理。
那怎么办?答案很简单——
推倒,重来。
回头看 AI 记忆的演化路径,脉络其实非常清晰:
第一代是直接硬塞全量上下文,就像通读日记;第二代依靠向量 + 关键词匹配,类似查字典,可是只能找到相似内容,抓不住真实关联;
现在,第三代记忆模式已经来了。
能够自主联想、推理、跨结构建立关联的认知模型。

让 AI 能够实现推理与联想,大家都知道跨粒度记忆的有效组织是关键。
简单点说就是让 AI 能同时处理细颗粒的事实和粗颗粒的上下文,还能在它们之间自由跳转(切换关联)。
但这个问题正是 2023 到 2026 年间,整个记忆引擎行业难以突破的核心瓶颈。
不过最近,我们观察到一个平均年龄 19 岁的中国年轻团队,心流元素,给出了可行解法——
M-FLOW,凭借自研的图路由 Bundle Search 架构,实现了 benchmark 的现象级领先。
对比 Mem0、Graphiti、Cognee 等主流方法,M-FLOW 在多轮对话、长期记忆、多跳推理三大核心场景下,性能优势显著。
- 对齐 Mem0 的官网 benchmark 测试(LoCoMo),领先 Mem0 36%;
- 对齐 Graphiti 的官网 benchmark 测试(LongMemEval),领先 Graphiti 16%;
- 在长期事件演变测试(EvolvingEvents)中,领先 Cognee 7%,领先 Graphiti 20%。
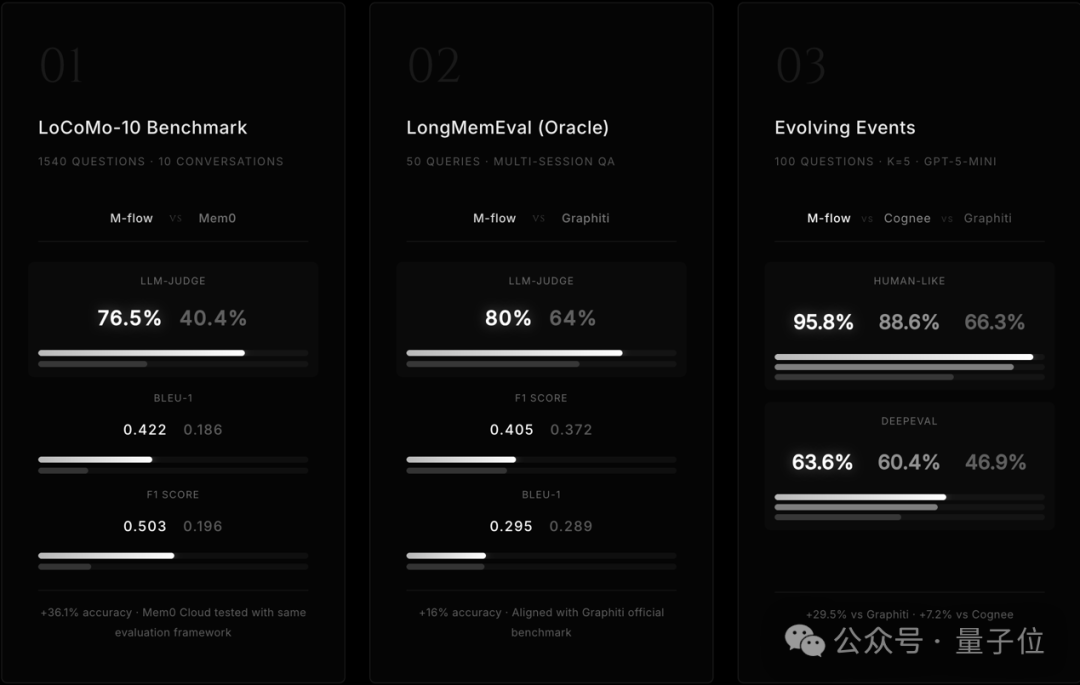
△测试未做任何筛选,采用行业通用 Benchmark
深度测评之后,可以更清晰地看到在覆盖写入、检索、预处理、知识组织等环节等 29 项能力维度中,M-FLOW 在绝大多数关键维度上都实现了完整支持。(下图可上下滑动完整查看)
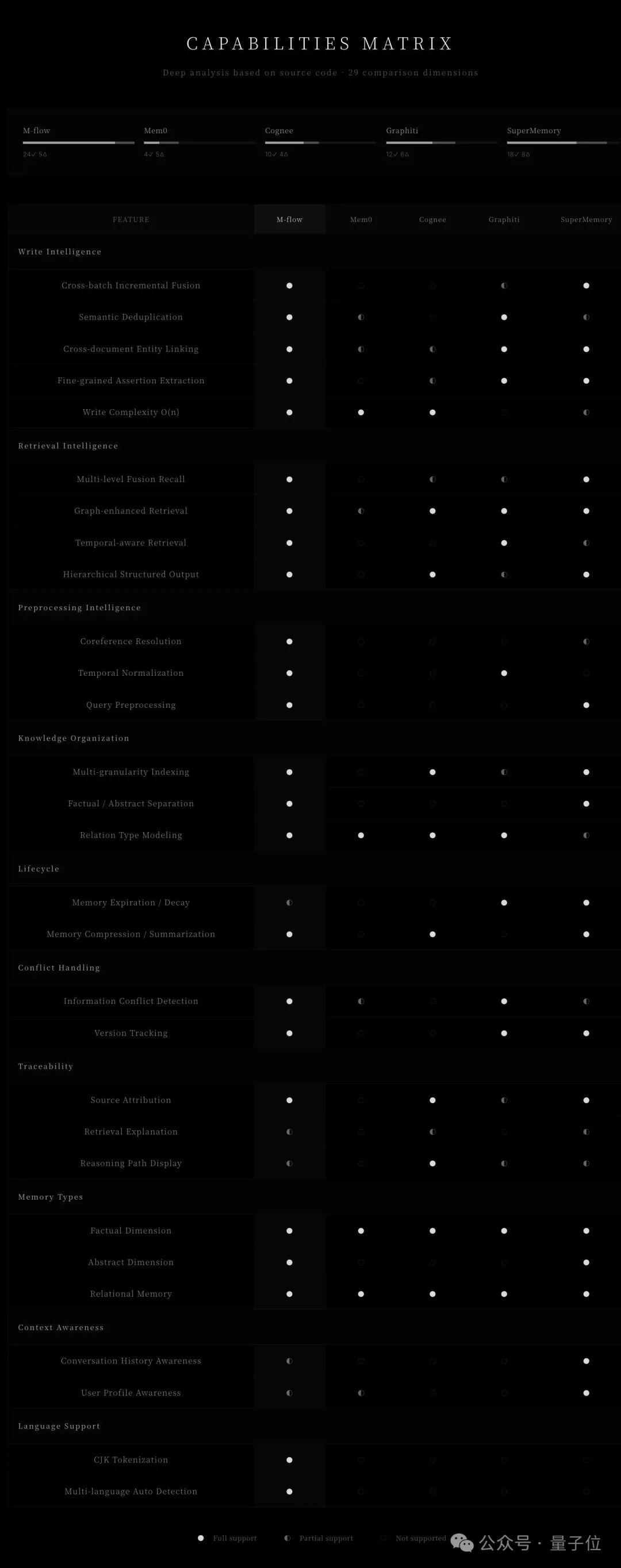
尤其在图增强检索、指代消解、多粒度索引等决定记忆质量的核心能力上表现突出。
这份成绩的背后,其实可以看到的是 M-FLOW 架构带来的系统性优势:
- 检索环节不依赖 LLM,能够实现毫秒级响应;
- 在超大记忆量场景下,依然能保持接近常规 Benchmark 的稳定表现;
- 业内首个支持指代消解的记忆引擎,让 AI 对信息的理解更贴合人类思维(指代消解是指能区分事件中的“他”和“它”)。

而且基本没什么使用门槛,部署流程非常简单,在具备 Docker 环境时只需要一行代码就能完成接入。
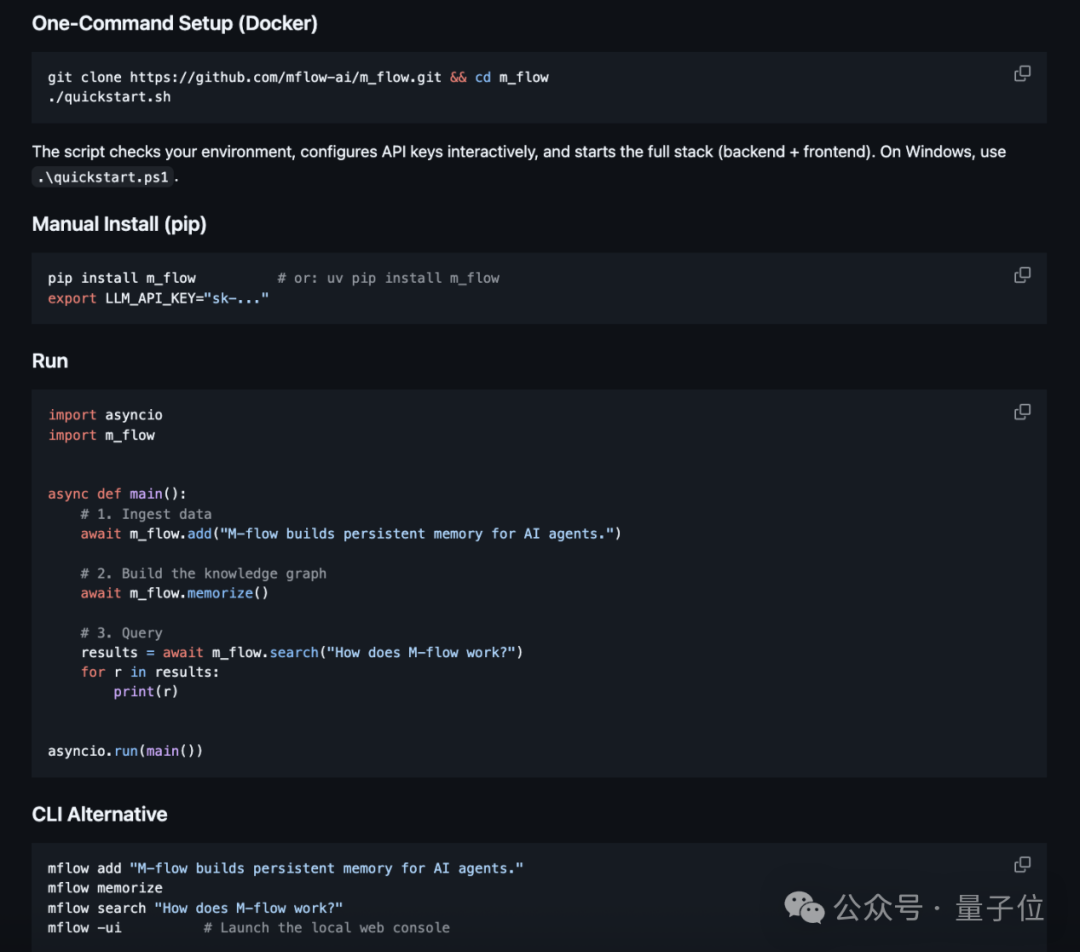
当然了,虽然上手简单,但在部署之前,咱也先来说说大家好奇的问题:
M-FLOW 是怎么做到的?
答案其实还是开头的那句话:推倒,重来。
与当前行业里大量同质化的记忆方案不同,M-FLOW 并不是用 LLM 辅助检索来抬高 Benchmark 分数,也不是简单叠加功能。
准确说,它是从根本上重构了 AI 记忆的组织与使用体系。
事实上,所有 RAG 系统都会面临的一个问题是,给定用户查询,如何精准定位存储的相关知识?
主流方案的逻辑很直接,就是将文档切块、向量化后存入向量库,检索时按余弦相似度排序。
这种方式本质上只回答“哪段文本和查询语义最接近”这一个层级的问题,对简单事实查找的效果还不错,但在复杂场景中会完全失效,因为:
- 答案跨文档分布:文档切块间缺乏结构性连接,无法将分散在不同文档中的关联信息整合;
- 查询与存储粒度不匹配:宏观问题检索到琐碎片段,微观问题匹配到笼统摘要;
- 同实体异语境割裂:两份文档讨论同一实体但语境不同时,向量空间中距离遥远,无法建立关联。
究其原因,是因为平坦向量检索丢弃了知识的内在结构。
它能判断文本与查询的相似度,却完全不清楚这段文本在整个知识体系中的拓扑位置。
在这一点上,M-FLOW 以图路由检索替代传统平坦检索,核心逻辑围绕分层知识拓扑展开,其核心洞察是:
不止找到“匹配的文本”,更要定位匹配点所属的完整知识结构,再对整个结构进行评分。
M-FLOW 将所有摄入的知识组织为一个四层有向图,形成一个倒锥(inverted cone):
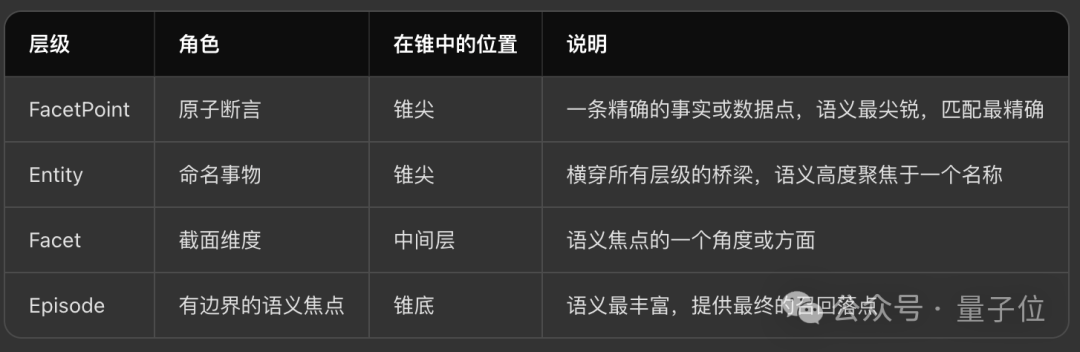
这个结构的方向性是反直觉的:在传统的知识图谱或分类树中,越往下越具体。
但在 M-FLOW 中,搜索的“入口在锥尖”(细粒度的 Entity 和 FacetPoint 是最容易被向量搜索精确命中的),而搜索的“目标在锥底”(Episode 是最终返回给用户的知识单元)。
信息流从尖锐的匹配点向下汇聚到宽广的语义落点。
这打破了“从上到下浏览”的传统检索范式。
用户不是在层级中逐层缩小范围,而是系统在最尖锐的点上捕获信号,然后沿图结构向下传播到它所归属的完整语义单元。
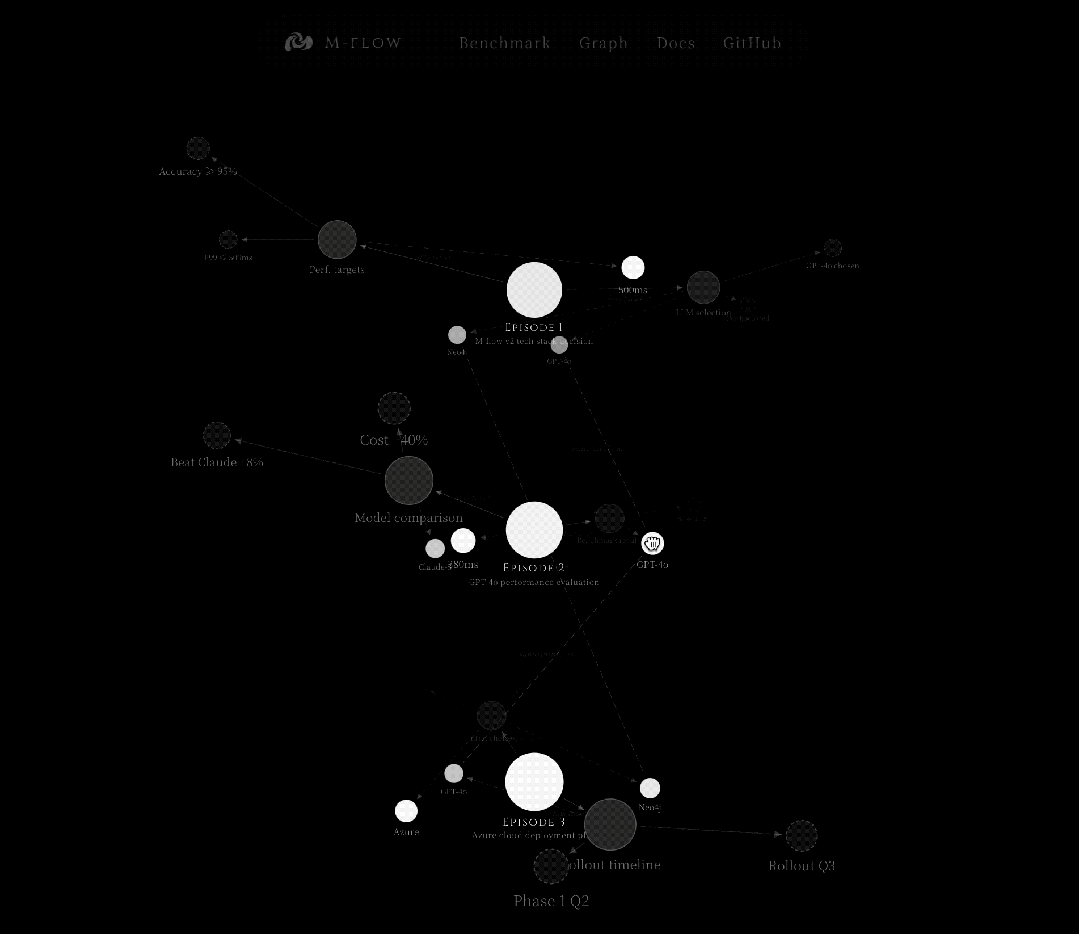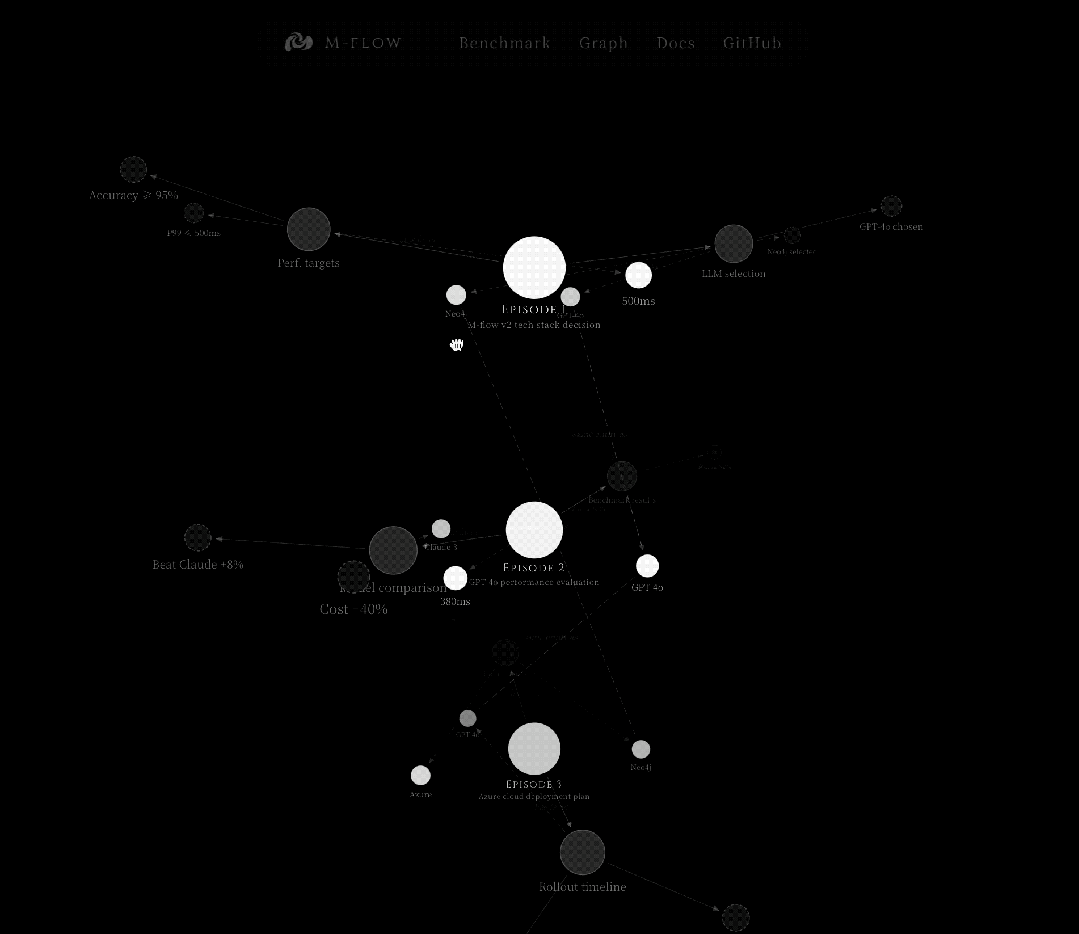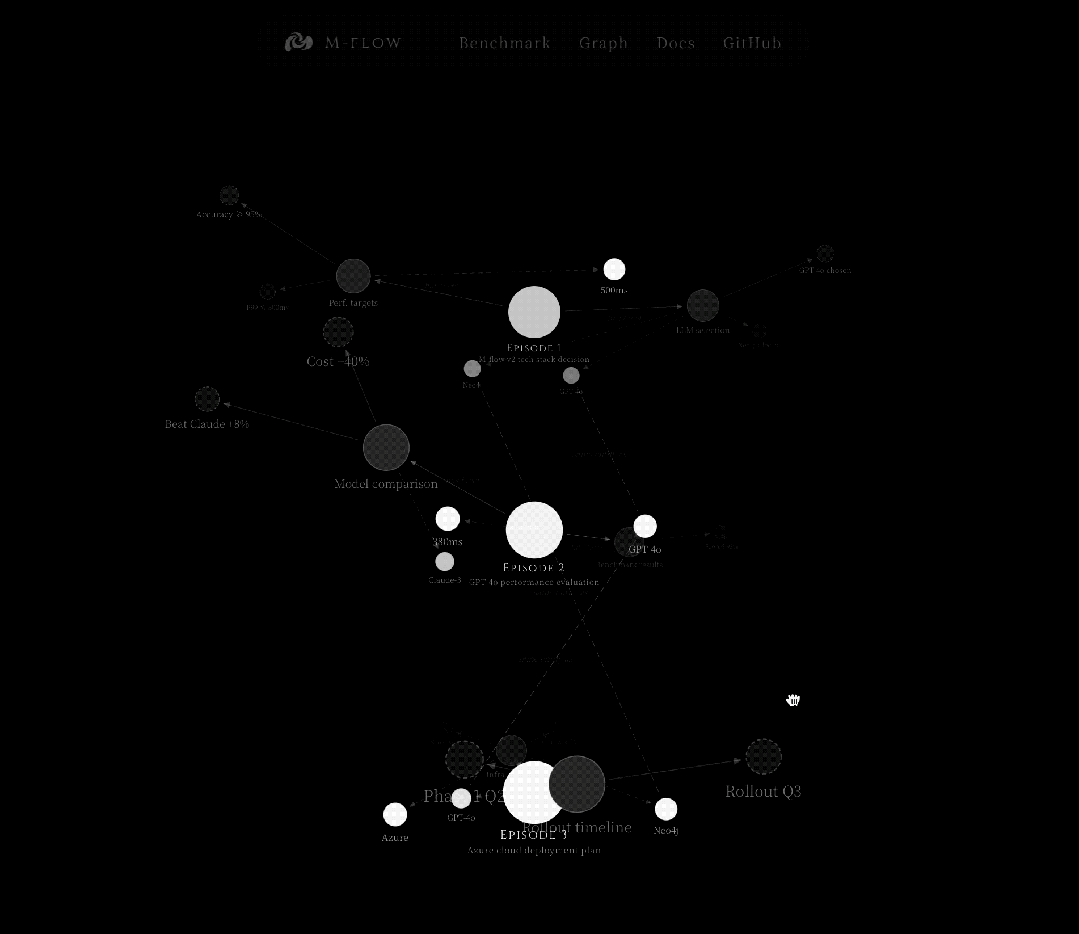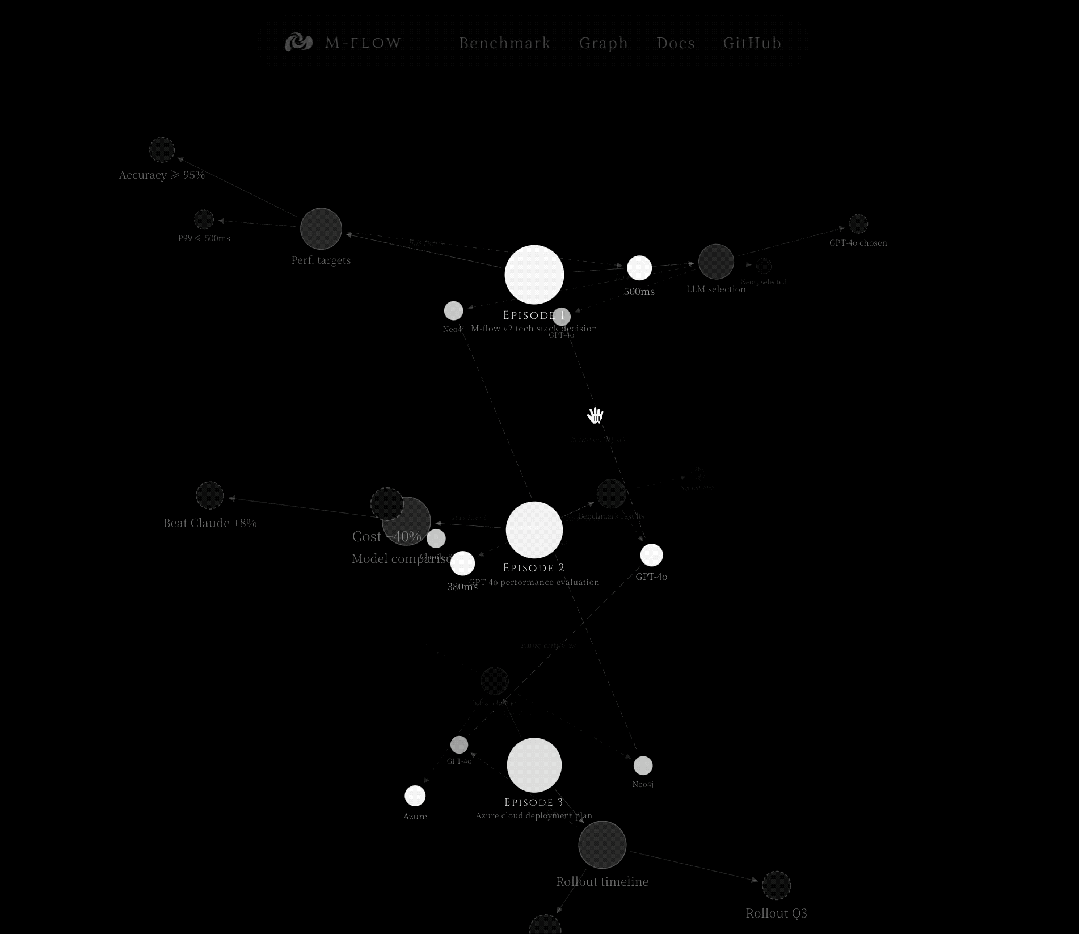
这是一个从细到粗的过程,先在最尖锐的点上捕获信号精准瞄准,然后沿图结构向下传播到它所归属的完整语义单元。
当查询到达时,系统不是简单地找到最近的节点。
它通过评估图中所有可能到达每个 Episode 的路径,找到最优的 Episode。
查询被向量化后,同时在七个向量集合中搜索,从锥尖到锥底覆盖每一层。每个集合返回最多 100 个候选。
最容易被精确命中的是锥尖处的节点,一个 Entity 名称、一个 FacetPoint 的断言。
这些细粒度锚点的语义极度聚焦,向量距离小。
锥底的 Episode 摘要也可能被命中,但因为语义更宽泛,匹配通常不如锥尖精确。
这些锚点被用作进入知识图谱的入口节点。
系统提取它们周围的子图,边、邻居、连接关系,然后扩展一跳邻居。
这将一组孤立的向量命中点转化为一个连通的拓扑结构。
这是核心步骤,也是图路由 Bundle Search 的本质——
在锥尖捕获信号,沿图边向锥底传播,在 Episode 处汇聚评分。
对于子图中的每个 Episode,系统评估从锚点到达它的所有可能路径:

每条路径的代价由三部分构成:
- 起始代价,锚点的向量距离(信号的尖锐程度);
- 边代价,沿途每条边的向量距离(连接关系与查询的相关度)加跳跃惩罚;
- 未命中惩罚,边没有被向量搜索命中时的默认高代价。
Episode 的最终得分是所有路径中的最小代价。
传统知识图谱中,边(图谱中节点之间的连线)只是作为类型标签,比如’works_at’、’located_in’,不参与语义检索。
查询一个图时,你要么遍历边,要么忽略边,因为边本身不携带可被搜索的语义。
而 M-FLOW 中,每条边都附带自然语言描述文本,这些文本会被向量化、同样参与搜索。
这意味着边不再是被动连接器,而是主动的语义过滤器。

在代价传播阶段,系统不仅知道两个节点之间存在连接,还知道这条连接关系本身与当前查询有多相关。
这样一来,即便一条边的两个节点都被搜索命中,只要这条边本身的语义和查询无关,就会被判定为高代价,从而直接切断这条不合理的关联路径。
为什么取最小值呢?团队主要考虑到一个检索哲学——一条强的证据链就足以证明相关性。
一个 Episode 可能关联 10 个 Facet,但 9 个与查询都无关。
传统方式会平均所有路径代价,这就会让无关路径拉高分数;
而 M-FLOW 只看那条最好的路径。
只要有一个 Facet 通过低代价路径连接到查询,这个 Episode 就应该被检索到。
这也对应了人类记忆的工作方式,比如你想起一件事,通常是因为某一个线索足够强烈,而不是因为所有线索都指向它。
这是最反直觉的设计,当查询直接匹配了 Episode 摘要时,系统反而对这条路径施加额外惩罚。
惩罚最直接命中的原因是,它们和很多查询看起来相关。
一个关于项目管理的 Episode 摘要,可能和任何提到项目或管理的查询都有不错的向量距离。
但这种匹配是宽泛的、缺乏焦点的,这其实也反映了众多 RAG 系统检索噪声的根本原因。
M-FLOW 系统的设计偏好,是优先选择从锥尖(FacetPoint、Entity)出发的精确路径。
即使多走几跳,也优先选择它,直接的 Episode 命中只在没有更好替代路径时才胜出。
这样就确保了检索结果的精确性——不是什么都沾点边的宽泛摘要,而是有具体证据链支撑的 Episode。
要说这套机制为什么有效,根本优势还是在于图拓扑编码了向量本身无法捕获的知识组织结构。
多粒度均可找到锚点。比如问“数据库迁移发生了什么?”这类宏观问题时,系统会直接匹配到 Episode 摘要。
虽然会受到直接命中惩罚,但因为没有更精确的锥尖路径,这条结果依然会胜出。
而像”P99 目标是否低于 500ms?”这类精确问题,则会强匹配一个 FacetPoint,从锥尖经过两跳到达 Episode,极小的起始距离让整体代价非常低。
系统不需要人为选择粒度,倒锥拓扑会自动在最合适的层级找到锚点。
跨文档实体桥接。当“张博士在 MIT 工作”出现在文档 A,”MIT 发表了量子计算突破”出现在文档 B 时,两个 Episode 会共享同一个 Entity 节点:MIT。
用户查询 MIT 时,锥尖命中该实体,代价会同时向下传播到两个 Episode,从而从两个独立文档中拿到关联结果,不需要 LLM 做额外推理,图结构本身就完成了桥接。

结构噪声过滤。在传统平坦检索中,很多语义相似但主题无关的文本片段会排在前面。
而在 Bundle Search 中,任何片段都必须沿着边追溯到某个 Episode。
如果沿途的边和查询语义无关,路径代价会迅速升高,让不相关结果自然下沉。
图结构本身,就是一层强大的语义噪声过滤器。
代价传播即推理。图中的每一条路径,本质上都是一条推理链——
查询匹配这个事实→事实属于这个维度→维度属于这个事件。
路径代价量化了这条推理链的紧密程度,系统在 2–3 跳内就能完成轻量级多跳推理,检索阶段不需要调用 LLM。
并不是每一层向量集合对每个查询都同样可靠。
系统会为每个集合计算两个指标,绝对匹配强度与区分度,然后把集合分为“节点类”和“边类”,按置信度动态分配权重。
比如某一次查询中,Entity 集合的置信度明显高于 Facet 集合,系统就会自动提高 Entity 路径的影响力。
它不是用固定权重,而是根据本次搜索中哪个粒度的命中更可信,实时调整检索策略。
还有一个额外的调节机制是,当某个 Facet 与查询向量距离极小、高度吻合时,系统会显著降低这条路径上的边代价和跳跃代价。
逻辑很直观,如果一个 Facet 已经几乎完美匹配查询,那么它到 Episode 的连接基本就是可靠的,不需要再通过边语义反复验证。
除此之外,系统还包含查询预处理、并行多模式调度、结果裁剪等机制……
所以总结来看,M-FLOW 的检索并不是向量搜索 + 图数据库的简单叠加,图本身就是检索机制。
在国内,外置记忆远没有国外的关注度高,然而 M-FLOW 团队不做同质化堆砌,实现了国产在该领域的从无到有,并且性能领先世界、还坚持开源开放……
其实很多初次接触记忆引擎的人都会有一个直观困惑,人类的回忆难道不是寻找相关信息吗?为什么 AI 的记忆,却总是在找文本形态相似的信息?
这个最普遍的问题,恰恰是 AI 记忆解决方案的核心症结。
从初代全量上下文硬塞式记忆,到第二代向量 + 关键词的检索式记忆,AI 始终停留在文本形态匹配,离真正的理解与联想相去甚远。
而 M-FLOW 用图结构重构了 AI 记忆的底层逻辑,解决了记忆图谱的粒度与联系问题,让 AI 记忆完成了从形态相似匹配到联想与推理的跨越。
而且值得一提的是,这个项目是由一支平均年龄 19 岁、从常青藤辍学的团队独立开发的。
在 AI 圈里,天才少年的故事总是备受瞩目。在这次技术突破之后,我们也想知道:
这群年轻人,未来又可以走多远呢……
项目地址:https://github.com/FlowElement-ai/m_flow
产品网站地址:https://m-flow.ai
公司地址:https://flowelement.ai
从技术演进的角度来看,M-FLOW 的出现标志着 AI 记忆层正在从“存储导向”向“推理导向”转变。传统向量数据库解决了“存”和“粗略找”的问题,但无法解决“理解关联”的问题。图结构的引入,使得记忆不再是孤立的片段,而是具备了逻辑拓扑的知识网络。
对于开发者而言,这类开源项目的价值不仅在于性能的提升,更在于提供了一种可验证的架构范式。当记忆引擎能够原生支持指代消解与多跳推理时,Agent 的自主化能力将获得实质性的飞跃。未来,随着更多类似架构的涌现,我们或许将见证 AI 从“对话者”真正进化为具备长期记忆与逻辑推理能力的“协作者”。




