个人知识库与大模型的结合,正成为开发者效率革命的新前沿。随着郑弘远(Karpathy)分享其基于文件系统的轻量级知识管理工作流,社区对于“如何让 AI 更懂私有数据”的讨论迅速升温。
传统向量数据库方案虽成熟,但在配置复杂度与成本上仍存门槛。基于图结构的知识图谱方案,因其更好的可解释性与关系推理能力,逐渐成为新的技术选型热点。此次出现的 Graphify 工具,正是在这一背景下,对现有工作流进行的工程化落地尝试。
以下为详细报道。
零配置开箱即用,一个命令生成完整知识图谱
闻乐 发自 凹非寺
AI 领域的迭代速度,时常让人产生时光压缩的幻觉。
Karpathy 分享的个人知识库方案刚刚爆火出圈,短短 48 小时内,开源社区便交付了一套功能完备的自动化解决方案。
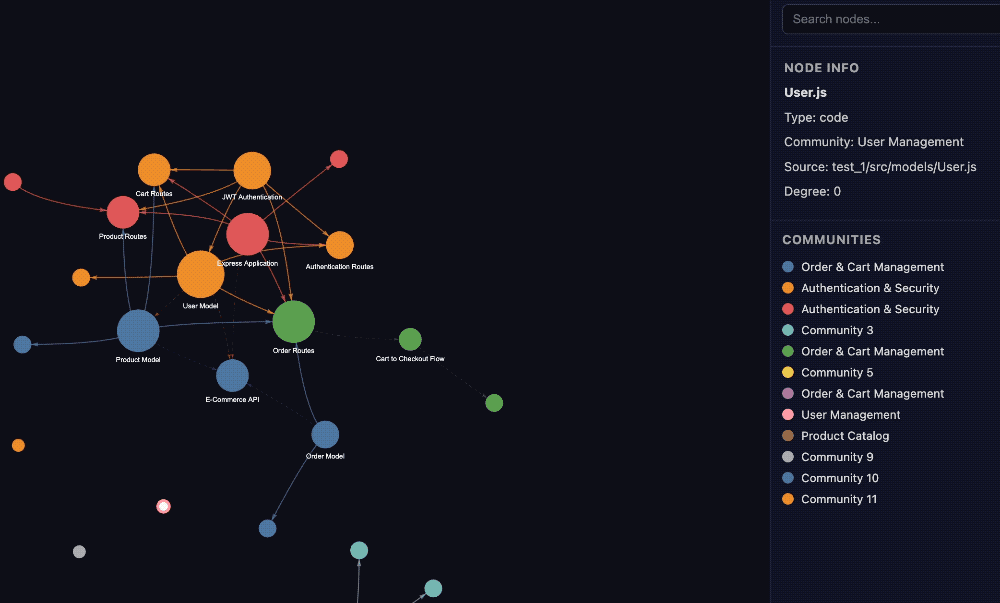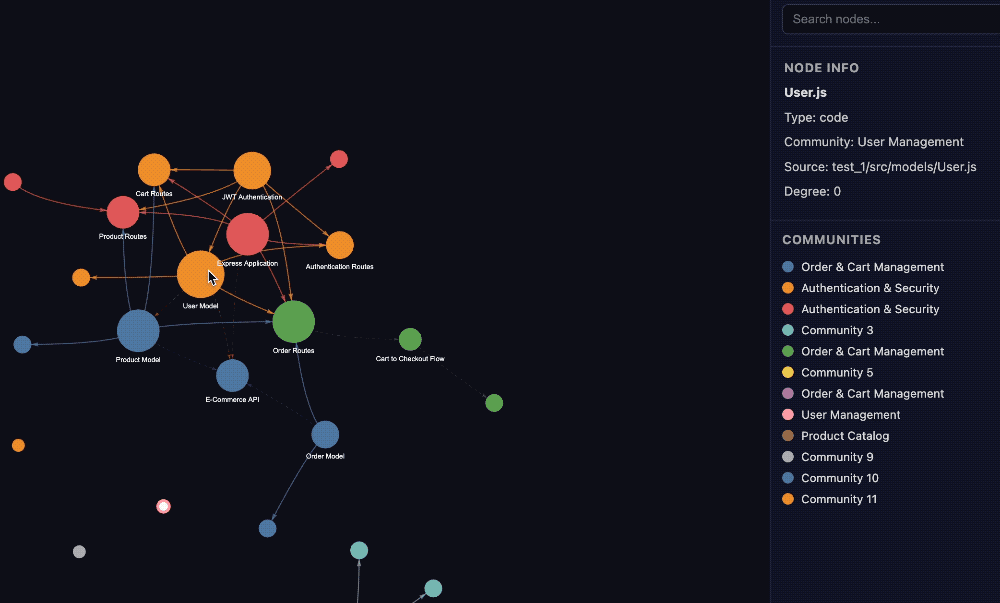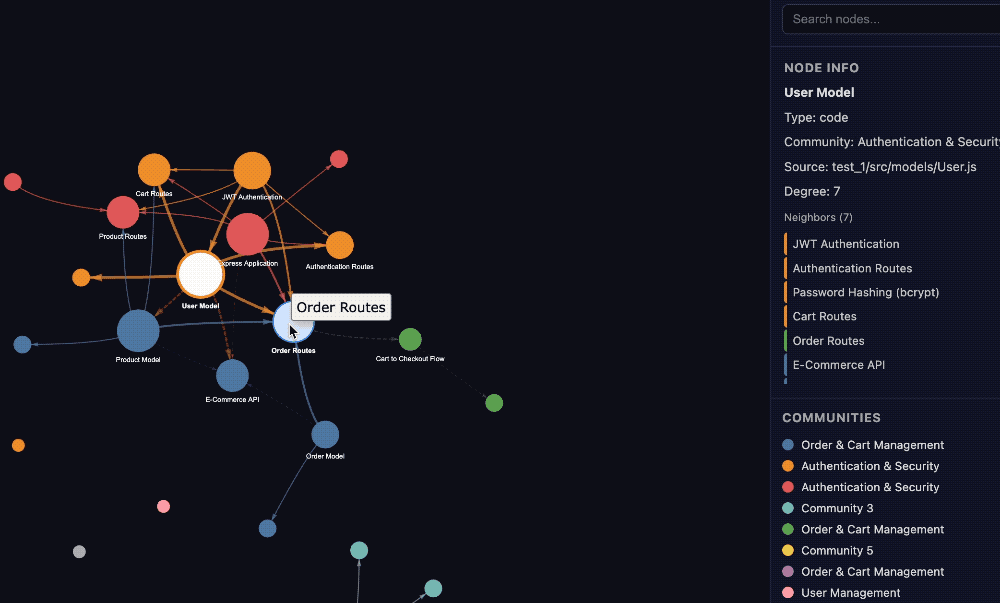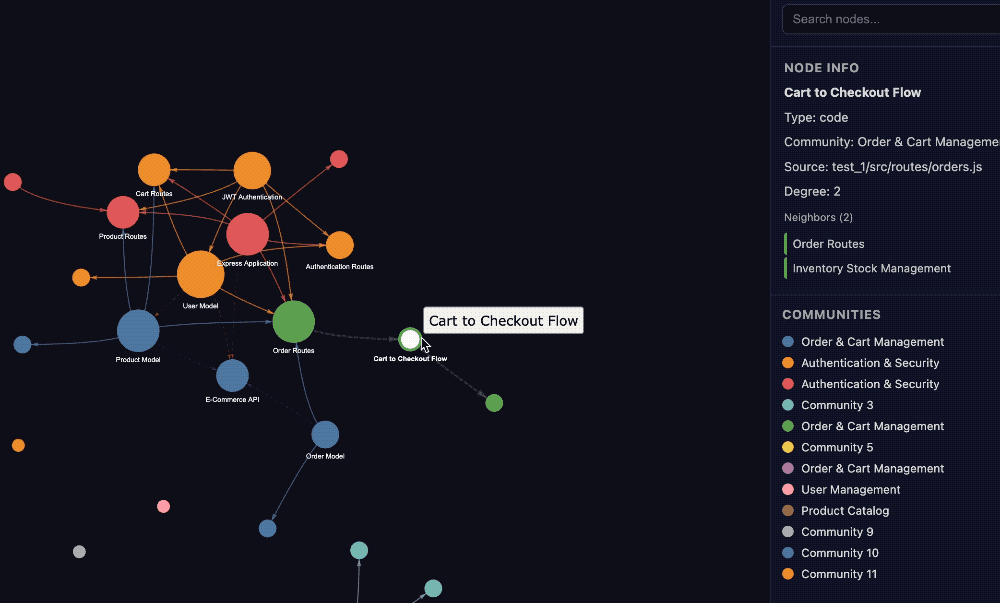
Graphify,一款主打零配置、全模态、本地运行且大幅节省 Token 的知识图谱工具,目前在 GitHub 上已收获超过 2000 星。
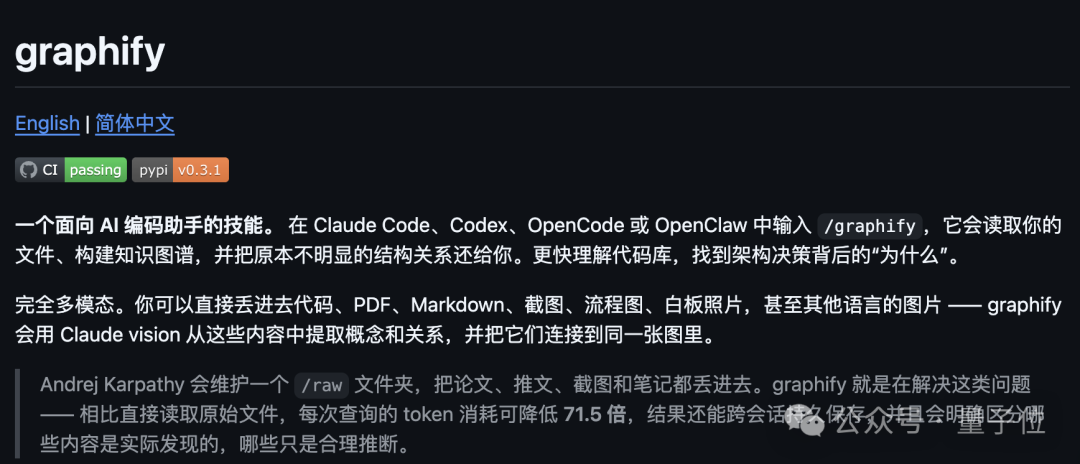
回顾卡神那套引发热议的知识库方案,其核心在于构建一套无需复杂向量数据库的轻量化工作流。
通过 raw 目录存储论文、代码、截图等原始资料,利用 LLM 自动生成带有交叉引用的 Wiki 文档,并配合定期维护,逐步搭建起一个可持續生长、愈用愈精的知识体系。
思路固然精妙,但在实际落地环节,仍存在不少优化空间。
例如,raw 文件夹需要人工手动整理归类,新资料的添加需全程跟进配合;
反复读取原始文件会导致较高的 Token 消耗,就连卡帕西本人也坦言:大部分 Token 已不再用于跑代码;
此外,整套方法目前仍停留在手动工作流阶段,缺乏专门工具封装,用户需一步步引导 AI 执行,操作链路相对繁琐。
痛点所在,即是创新之所。卡神知识库方案发布 48 小时后,开源社区便交出了这份完全体答卷。
Graphify 对这套工作流进行了全方位的工具化升级。
首先是全模态自动图谱化,从源头剔除了手动整理的繁琐。
Graphify 内置了统一的多模态处理管线,能够针对不同文件类型实现针对性的自动化解析。
针对代码文件,通过 tree-sitter 进行本地 AST 解析直接提取结构信息;针对 PDF、Markdown 等文档,自动拆分文本与语义单元;针对截图、流程图、白板照片等视觉内容,则调用 Claude Vision 完成概念提取与关系识别。
这一切无需人工预处理、无需分类、无需筛选,只需丢进文件夹即可统一入谱。
相比之下,卡神的 raw 文件夹仍需要用户手动规整资料、手动触发处理,而 Graphify 则从文件扫描到图谱生成全程自动化,真正实现了万物皆可图谱化。
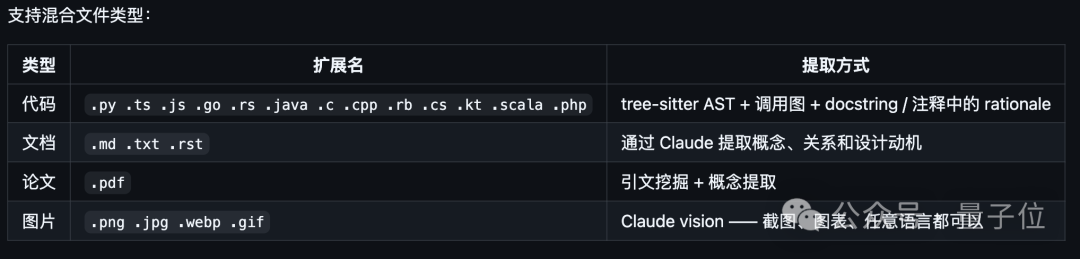
在此基础上,它还依靠本地 AST 解析与并行 LLM 子代理语义提取的双阶段流程,实现了71.5 倍 Token 消耗优化。
第一阶段对代码文件做确定性 AST 提取,全程在本地完成,不调用 LLM、不产生任何 Token 消耗;
第二阶段仅对文档、论文、图片等非代码内容,通过并行 LLM 子代理做一次语义抽取,同时搭配 SHA256 缓存机制,重复运行时只处理变更过的文件,从根本上避免了重复计算与无效开销,把 Token 真正用在推理上。
在包含卡帕西的仓库文件、5 篇论文、4 张图片共 52 个文件的混合语料场景下,使用 Graphify 后每次查询的 Token 消耗,相比直接读取原始文件降低了 71.5 倍。

更友好的一点是,它全程无需向量数据库、无需嵌入计算、也不用复杂配置,做到了开箱即用。
它的聚类基于图拓扑完成,依靠 Leiden 社区发现算法按边密度划分社区,无需依赖 embeddings,自然也省去了向量数据库的部署与维护成本。
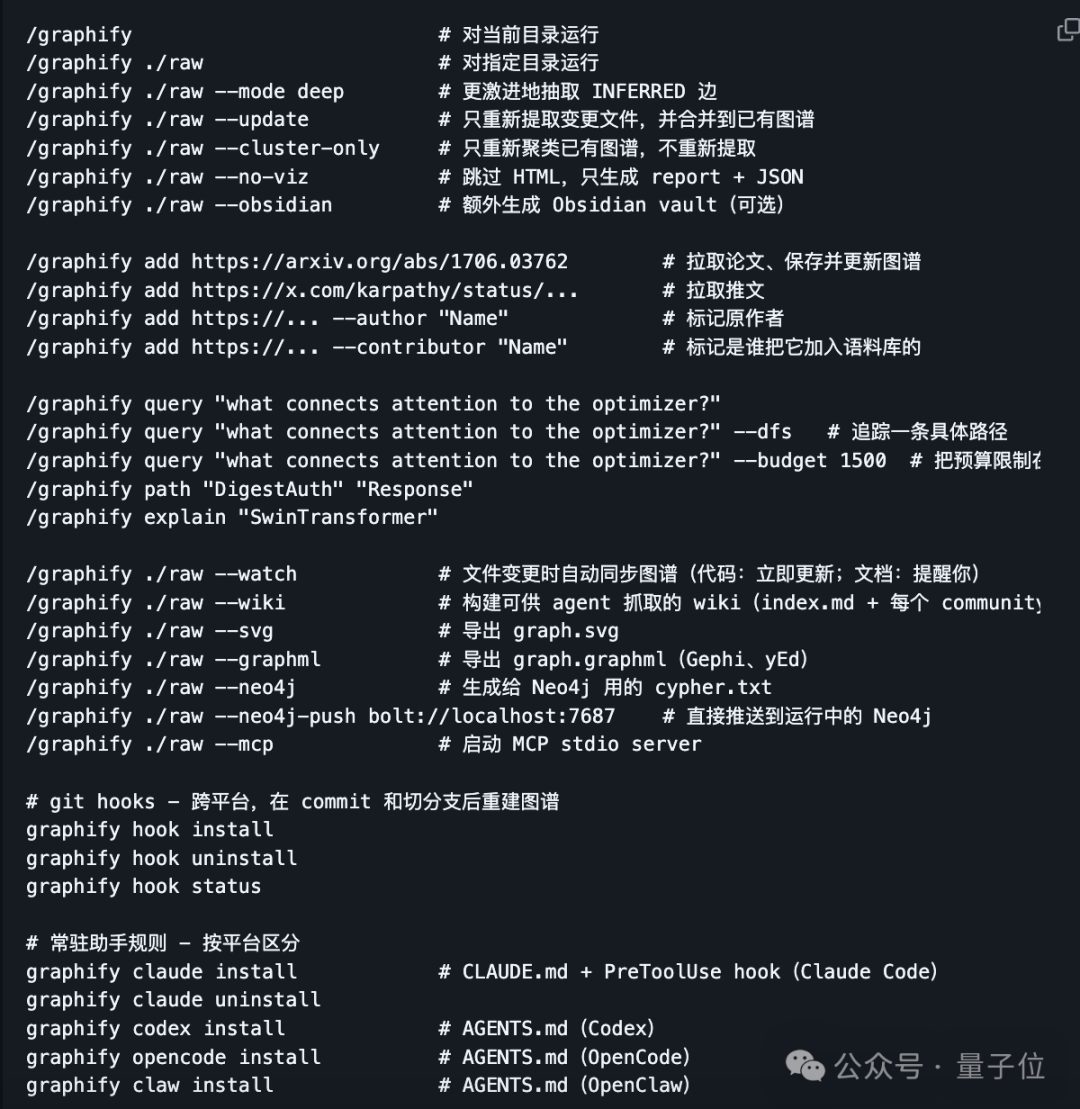
只需要在目标文件夹执行/graphify . 这一条命令,指向任意文件夹就能一键生成完整知识图谱,附带交互式 HTML、分析报告与可持久化数据文件,极大降低了上手门槛。
同时,Graphify 还为每一条内容关联都加上了清晰的类型标注,区分原文提取、模型推断与歧义关系,并附带置信度,让知识来源透明可查、结果更可信。
说完了优点,再看看如何安装部署。
首先,Graphify 实现了全平台适配,Claude Code、Codex、OpenClaw……都能无缝接入使用。
仅需 Python 3.10 及以上环境,一行命令即可完成全部部署(PyPI 包当前暂时叫 graphifyy):
pip install graphifyy && graphify install

graphify install —platform claw

- Codex 用户:想用上 Graphify 说的并行 LLM 子代理提取,必须先在配置文件~/.codex/config.toml的[features]里打开multi_agent = true,不然跑不起来并行模式。
- OpenClaw 用户:这个平台对多代理并行的支持还很初级,没完善,所以只能用顺序挨个提取,没法并行,速度和效率会差一些。
安装完成后,进入你想要图谱化的目录,用/graphify . 命令一键生成即可。
执行完命令,当前目录里就会出现 graph.html 文件,在浏览器中打开就能看到可交互的知识图谱。

它还支持—watch 文件监听模式,代码文件改动后会立即触发 AST 重新解析,实时更新图谱;文档、图片变更则会主动提醒用户执行增量更新。
同时还能安装 Git 钩子,在代码 commit 提交、分支切换后自动重建图谱,无需额外开启后台进程。
配合/graphify —update 增量更新命令,新资料加入时无需重建整个图谱,只更新相关节点和关联,让知识库真正实现随资料新增持续生长、越用越完善。
Graphify 的作者Safi Shamsi现为伦敦 Valent 公司的一名 AI 研究员。
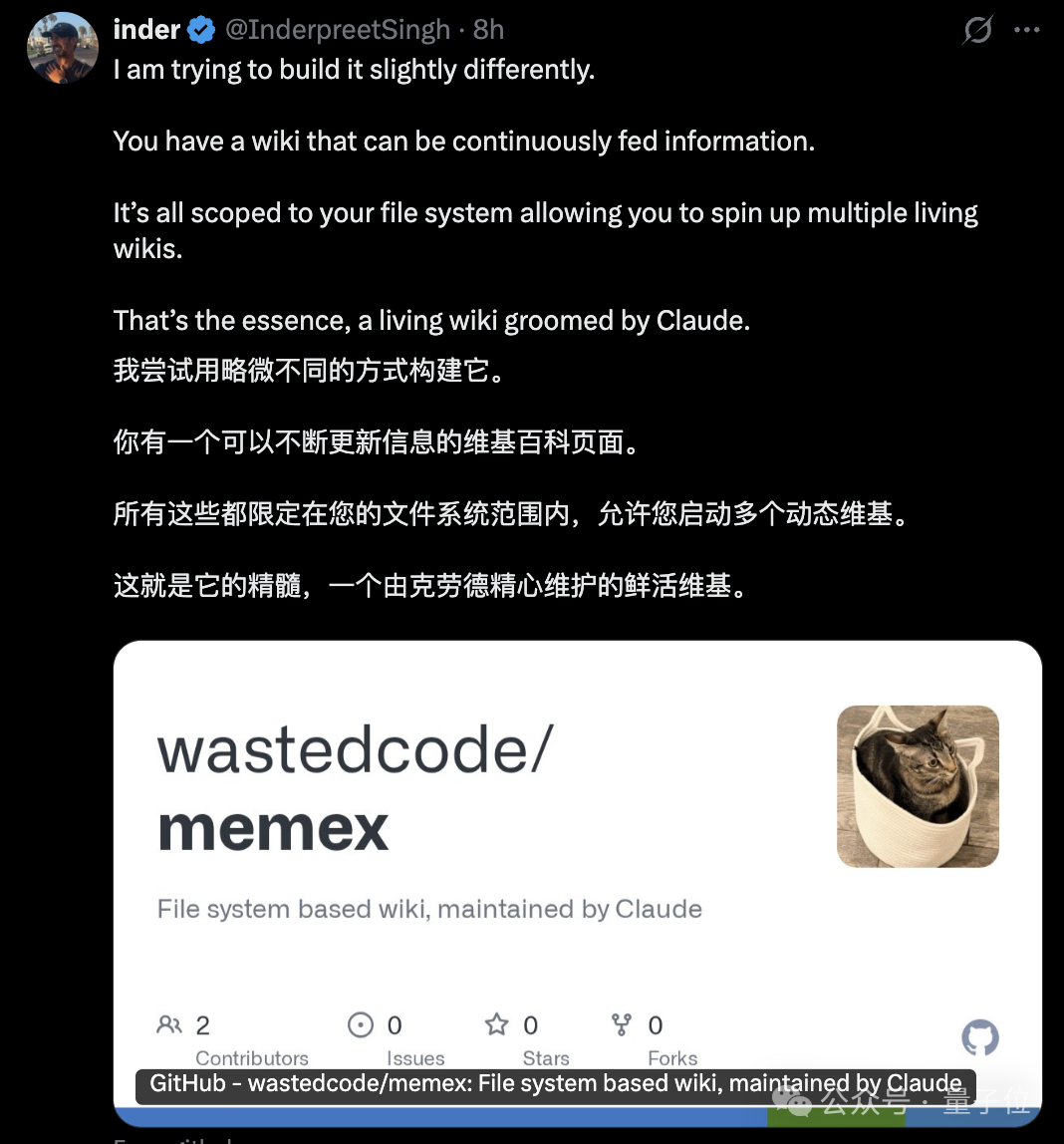
其实卡神的知识库出来之后,很多人都开始跟风复刻,还有人做了一款基于个人文件的“活维基”工具。
AI 圈现在以小时为单位的迭代玩法,只能说疯狂,太疯狂。
— 完 —
从技术演进的角度来看,Graphify 的出现标志着个人知识管理工具正从“存储导向”向“理解导向”转变。不再依赖庞大的向量索引,而是通过图结构捕捉知识间的语义关联,这在处理代码库与多模态混合数据时显得尤为高效。
然而,此类工具的大规模普及仍面临挑战。一方面,对特定商用模型 API(如 Claude Vision)的依赖可能增加长期使用成本;另一方面,本地解析与云端推理的边界如何平衡隐私与性能,也是用户考量的重点。尽管如此,这种轻量级、自动化且低成本的尝试,无疑为开发者构建第二大脑提供了新的思路。
随着开源社区的持续贡献,未来或许会出现更多支持本地模型运行、完全离线化的分支版本,进一步推动个人知识图谱技术的民主化。