在大模型竞赛进入深水区之际,算力消耗量正逐渐成为衡量科技公司内部 AI 渗透率的关键指标。巨头们不再仅仅满足于模型参数的堆叠,而是转向了实际应用场景中的 Token 吞吐量比拼。这种从“训练主导”向“推理主导”的转变,正在重塑工程师的工作流程与考核体系。
作为硅谷最具代表性的科技巨头之一,Meta 最近在内部推行的一系列 AI 化改革,为我们观察这一趋势提供了极佳的样本。在这场涉及数万人的算力狂欢背后,既有着对生产效率的极致追求,也隐藏着资源空转的隐忧。
榜一大哥平均每天用掉 93.6 亿 Token
资深观察员 发自 硅谷前线
深度科技分析
Meta 内部正在上演一场前所未有的“烧 Token”竞赛,这场由首席 AI 官推动的算力消耗战,已经将资源投入卷出了新高度。
在这一战略驱动下,全公司每日消耗的 Token 数量高达两万亿,这一数字相当于将整个维基百科的内容遍历了 40 多遍。
位居内部榜单榜首的超级用户,单月消耗量更是达到了 2810 亿 Token,折算下来平均每天要用掉 93.6 亿个 Token。

此前,扎克伯格下达了用 AI 彻底重写代码库的硬指标,试图以此让 AI 全面接管底层的代码修改工作。
于是,8.5 万名员工为了抢夺”Token Legend”等虚荣头衔展开了追逐经济,直接将算力消耗规模变成了衡量职场地位的新勋章。
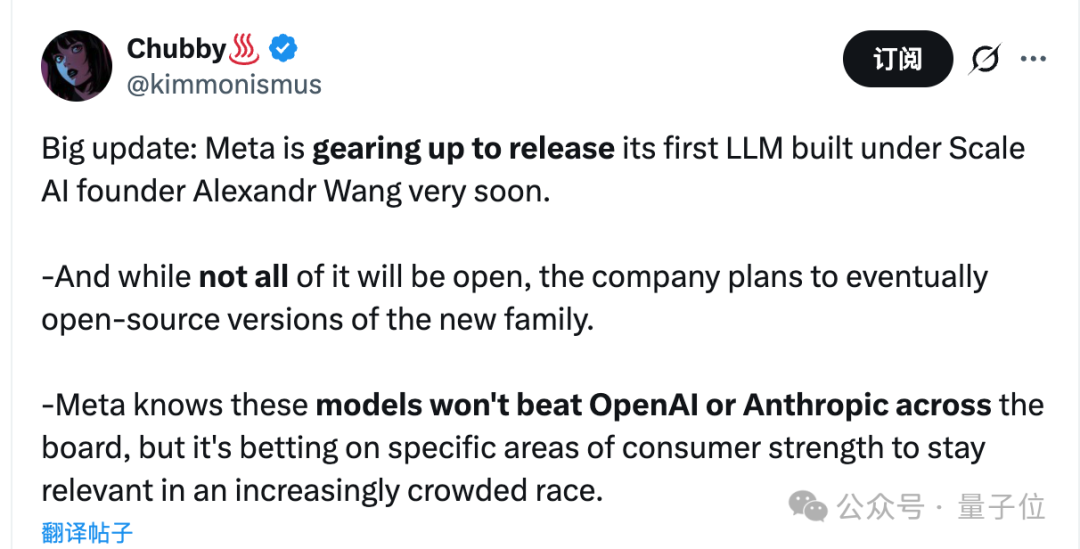
不过,亚历山大王这每天两万亿也没白烧,Meta 第一个由他主导的模型,即将以“半开源”的形式揭晓。
Meta 的”Token 竞技”
在 Meta 内部,有个叫 Claudeonomics 的排行榜,实时记录着 8.5 万名员工的 Token 消耗量,员工们为了抢夺 Token Legend 或 Session Immortal 这种勋章而展开疯狂的刷榜内卷。
在这场”Token 竞技”当中,亚历山大王作为新任 AI 掌门人展现出了极强的统治力。
在他的强力推动下,Meta 全公司实现了日均 2 万亿 Token 的恐怖吞吐量,将算力吞噬的规模推向了前所未有的高度。
在这种被称为 Tokenmaxxing 的狂热氛围下,消耗更多 Token 被视为更具生产力的象征。
员工们逐渐默认 Token 吞吐量才是衡量职场价值的硬指标,甚至将这种极其烧钱的消耗记录,直接当成了身份的象征。
为了稳固排行榜上的排位,甚至有工程师开始指挥 AI Agent 在后台进行长达数小时的冗余研究,甚至是空跑。
比如有投资界人士表示,自己有很多朋友在 Meta,他们表示 Meta 员工为了消耗 Token,专门构建了会循环运行的机器人。
他批评这种做法愚蠢至极,和用代码行数衡量产出的做法毫无二致。

更滑稽的是,即便这种单纯的空转对公司业务并没有实际产出,但只要能刷出更加华丽的消耗数据,就能在这场全员参与的竞争中博得关注。
扎克伯格强推 AI
这整场风暴的导火索,其实是扎克伯格在内部备忘录里提的一个要求。
他要求工程团队把现有的所有代码库全部重写一遍,要彻底清理掉那些 AI 读不懂的陈年旧账,好让 AI 能毫无障碍地接管底层的代码修改工作。
为了应付这个看似不可能完成的代码重构任务,工程师们开始大规模动用 MyClaw 和 Manus 这类全自动工具。
哪怕只是处理一些日常最不起眼的脚本,大家也要让 AI 工具全面介入,试图用这种饱和式的自动办公来对抗繁重的重构压力。
面对这种几乎快要把算力烧穿的资源挥霍,首席技术官 Andrew Bosworth 不但没打算灭火,反而表现得相当慷慨。
他在公开场合明确支持这种不设限的资源投入,觉得只要能用钱砸出生产力的跨越,这笔买卖在公司层面看怎么都是稳赚不赔的。
黄仁勋之前也公开发表过类似的观点,他觉得一个拿着 50 万美元年薪的顶级工程师,如果每年不烧掉个 25 万美元左右的 Token,那简直就是“严重的职业失职”。
现在看来,Meta 的这帮人是真把老黄的话听进心里去了,而且还在用一种近乎疯狂的方式变本加厉地贯彻到底。
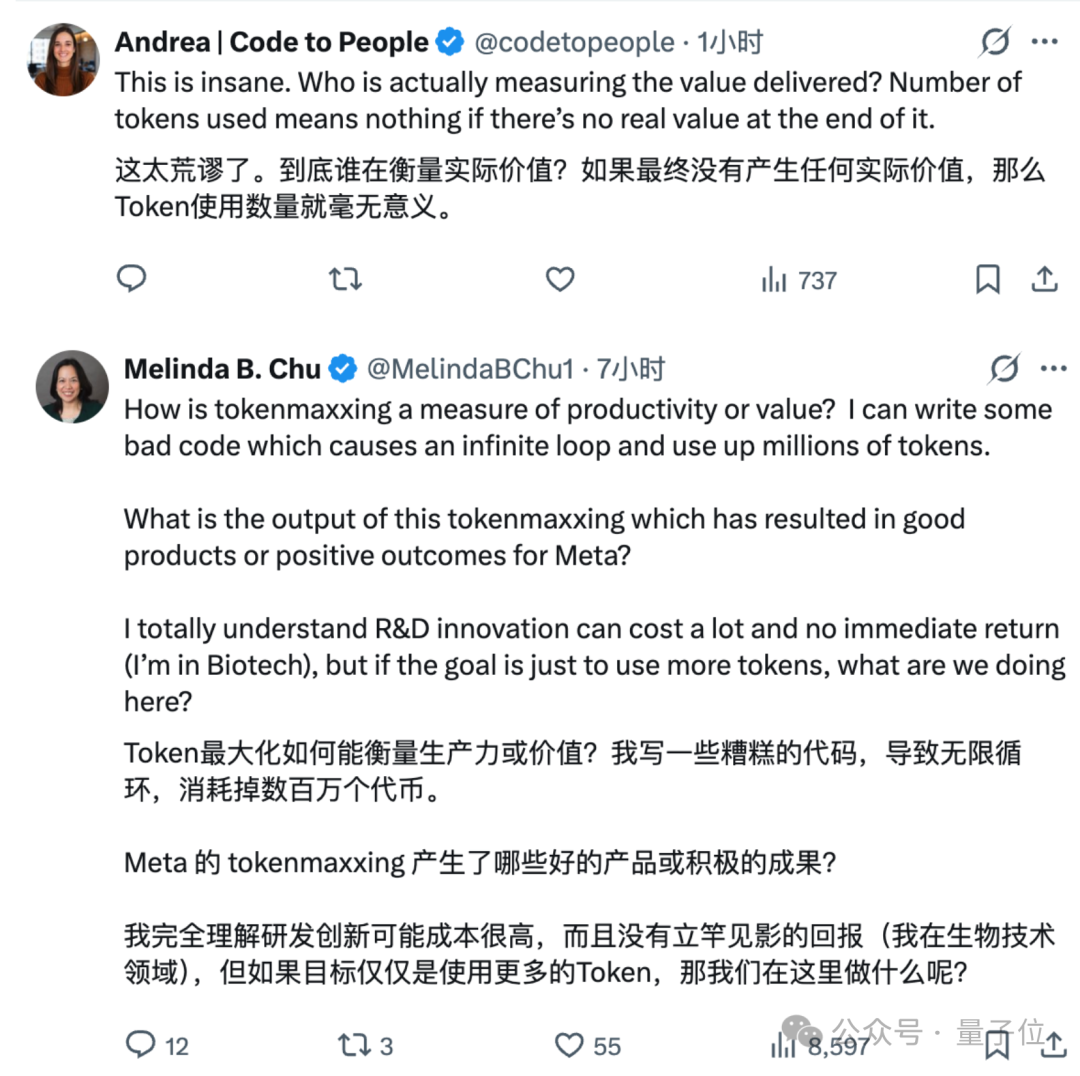
不过,许多网友并不认可这样的观点,他们表示,如果没有产生实际价值,那么 Token 数量毫无意义。
网友们的批评不无道理,不过 Meta 这边,倒也说不上毫无产出——由亚历山大王带队研发的新模型,就要上线了。
Meta 又不闭源了?
在此之前,业内广泛流传着 Meta 可能彻底放弃开源路径的消息。
当时不少行业分析指出,Meta 为了保护核心技术资产,可能会转向全面闭源模式。
这种市场预期的出现,反映了外界对 Meta 在激进的 AI 竞赛中能否继续维持开放策略的质疑。
不过,由亚历山大王主导开发的第一个新模型家族,最终决定重新回到开源路线。
根据目前确定的方案,Meta 决定将这些新模型的版本通过开源许可证提供给外界。
在向开发者社区开放模型调用权限的同时,Meta 对涉及最核心的技术细节依然保持私密。
不过这次,Meta 对自己的新模型也算是有了一些自知之明——
他们知道这些模型不会在所有方面都胜过 OpenAI 或 Anthropic,所以选择了押注于消费者优势的特定领域,以在竞争日益激烈的市场中保持竞争力。
具体来说,Meta 计划将这些新模型的各种能力深度嵌入 WhatsApp 和 Instagram 的业务流程。
通过这种饱和式的社交渗透,Meta 试图在日常沟通和内容创作领域构建起一套属于自己的 AI 体验。
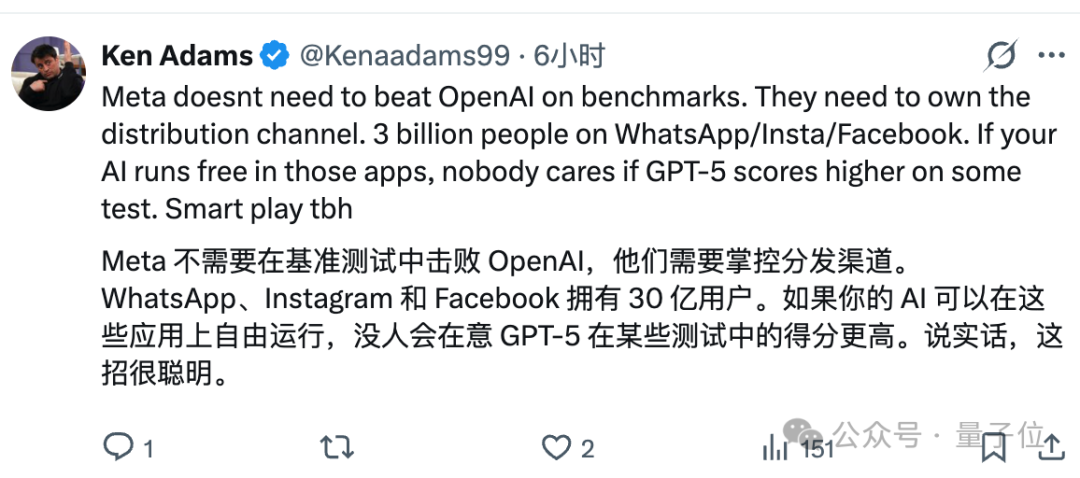
有网友认为,凭借 Meta 拥有的三大超级社交应用,这种“掌控分发渠道”的策略,是一种非常明智的选择。
你觉得呢?
从行业视角来看,Meta 的这种“以量换质”策略或许正处于一个临界点。一方面,海量的内部使用数据确实能为模型迭代提供宝贵的反馈闭环,这是闭源模型难以企及的优势;另一方面,若缺乏有效的效能评估机制,单纯的 Token 消耗竞赛极易演变为财务黑洞。
未来,随着 AI 工程化能力的成熟,如何平衡算力投入与实际业务产出,将是所有科技公司必须面对的共同考题。Meta 的此次尝试,无论成败,都将为整个 AI 基础设施层的发展提供重要的参考坐标。