在大模型技术狂飙突进的当下,静态权重似乎正逐渐成为限制模型适应性的瓶颈。传统的“预训练 – 微调”范式,在面对动态变化的任务场景时,往往显得不够灵活。如何让模型在推理阶段也能具备“即时学习”的能力,而不必付出巨大的重训成本,是全球顶尖实验室竞相角逐的高地。
近日,字节 Seed 与北京大学联合团队带来了一项最新突破,让大模型实现了“原地改参数”。
作者 | 字节 Seed & 北京大学研究团队
论文 | ICLR 2026 Oral
这项研究的核心在于,既不需要更改模型结构,也不需要重新训练,还能保持高速推理。

具体背景是这样的。智能体时代已然来临,模型面对的任务复杂度日益攀升,上下文窗口也越来越长。
如何让大模型在干活的同时边学习,不断适应新的信息流,而不是在超长上下文中逐渐“遗忘”或崩溃,已成为学术界与工业界关注的焦点。
此前的测试时训练(Test-Time Training, TTT)技术虽然允许模型在推理时更新部分参数,但在实际落地中仍面临三重阻碍:
首先,架构兼容性差。现有的 TTT 方案往往需要引入全新的网络层,甚至替换核心的注意力机制,这意味着必须从头开始进行预训练,成本高昂。
其次,计算效率低。传统 TTT 多采用逐 Token 的顺序更新方式,无法充分发挥 GPU/TPU 的并行计算优势,导致推理延迟增加。
最后,优化目标不匹配。现有方法多采用重建目标(reconstruction),仅让模型记住当前词,这与语言模型核心的“预测下一个 Token”任务并不一致。
针对上述痛点,字节 Seed 和北京大学的研究团队提出了一种名为In-Place TTT(原地测试时训练)的创新方案。
其核心思路十分巧妙:不新增层,也不改架构,直接将 Transformer 中固有的 MLP 模块,转化为大模型的“临时小脑”。
这使得 TTT 能够作为一个即插即用的模块,无缝集成到现有的预训练大模型中。
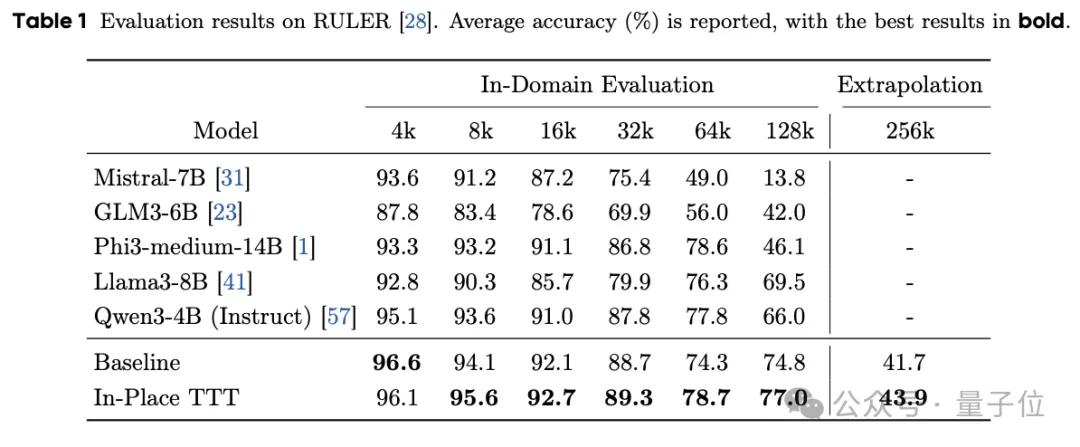
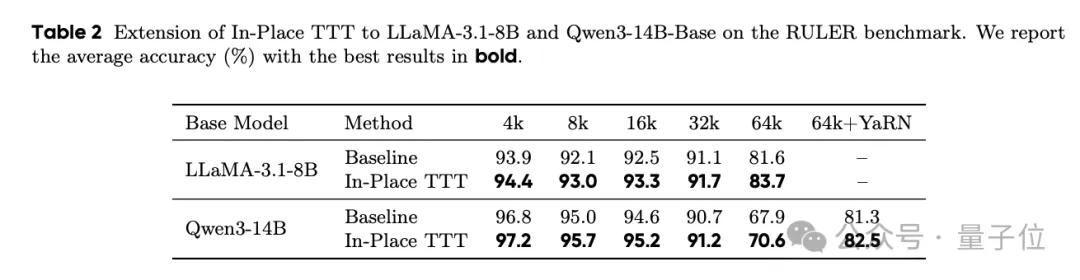
实验数据显示,Qwen3-4B、Llama3.1-8B、Qwen3-14B 等主流模型在装备 In-Place TTT 后,性能均有显著提升,尤其在长文本任务上表现突出。
目前,这篇论文已正式被 ICLR 2026 录用为 Oral 论文。
接下来,我们深入解析这项技术的实现细节。
In-Place TTT 的核心目标,是在不折腾模型架构的前提下,让大模型在推理过程中能够悄悄更新自身参数,以适配当前的上下文信息。
为了实现即插即用,研究团队主要完成了三项关键创新。
第一,复用现有模块。在 In-Place TTT 中,研究人员巧妙地复用了 Transformer 中无处不在的 MLP(多层感知机)。
他们将 MLP 的最后一个投影矩阵 Wdown 作为快速权重(fast weights),在推理时进行原地更新。
这一设计无需引入新的专用层来处理快速权重,已经训好的大模型可以直接拿来使用,不必重新训练。

第二,优化目标对齐。原有的 TTT 只让模型“记住当前 Token”,这与语言模型的优化目标存在偏差。
为此,In-Place TTT 设计了专门针对自回归语言模型的优化目标:
通过引入一维卷积(Conv1D)和投影矩阵,使 TTT 的目标值包含了未来 Token 的信息,从而显式地与“预测下一个 Token”的任务对齐。
研究人员分析证明,这种做法能促使快速权重压缩对未来预测有用的信息,从而有效提升模型的上下文学习能力。
第三,并行计算优化。In-Place TTT 是对 MLP 进行改造,保留了原有的注意力层,这使得该方法可以实现分块更新,不再需要逐 Token 处理。
结合上下文并行技术,In-Place 能实现更高的吞吐量和计算效率,支持更长的上下文。

实验结果表明,In-Place TTT 能大幅提升现有模型(如 Qwen3-4B)在 128K 甚至 256K 长上下文任务中的表现。
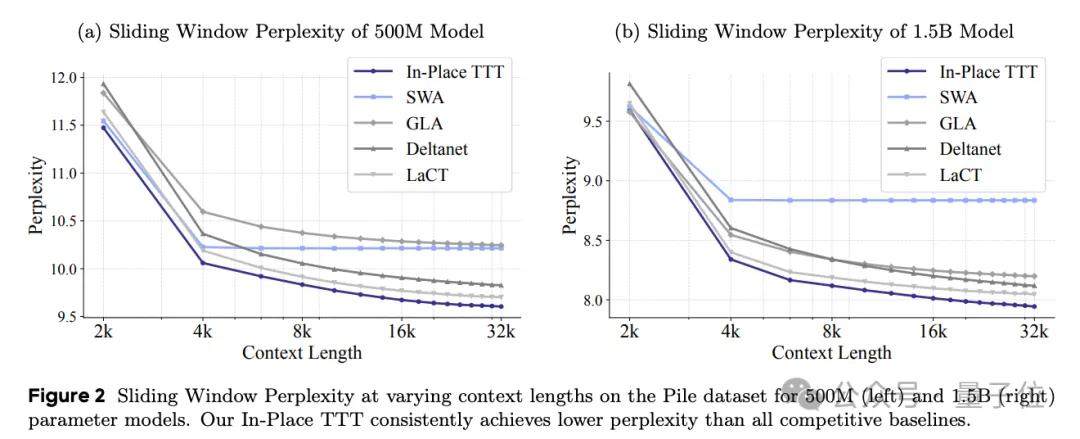
在从头训练的对比实验中,该方法也优于其他现有的 TTT 方案。
据悉,这篇论文的一作是冯古豪和罗胜杰。
冯古豪目前就读于北京大学,同时也是字节 Seed 的实习生。
罗胜杰同样毕业于北大,师从王立威教授和本文通讯作者贺笛教授。
本文的另一位通讯作者是字节 Seed 的 Wenhao Huang。
值得注意的是,虽然测试时训练展现了巨大的潜力,但其带来的计算开销与稳定性问题仍是落地前需要跨越的鸿沟。字节种子团队此次的探索,为如何在现有架构上低成本实现动态适应提供了新思路。
未来,随着硬件算力的进一步下沉,这类“边推理边进化”的模型或许将成为智能体时代的标配,尤其是在需要处理复杂、动态信息的边缘侧场景中,其价值将更加凸显。





