在大模型参数规模日益庞大的背景下,架构效率成为新的竞争焦点。本文整合了公开研究资料及目前对新型架构的主流推测,探讨推理时计算扩展的可能性。
当前,人工智能领域正经历从“暴力堆叠参数”向“优化架构效率”的微妙转变。随着 Scaling Law 边际效应的讨论逐渐升温,如何在有限算力下实现更深层的逻辑推理,成为学术界与产业界共同关注的命题。
近期,关于 Anthropic 内部架构的传闻引发热议。有开发者通过逆向工程与公开论文整合,尝试复现传说中的高效架构,并将相关代码开源。
技术观察 | 深度解析
这一项目被称为 OpenMythos,其核心在于整合了现有的公开研究成果,以及对 Claude 潜在架构的主流技术推测。
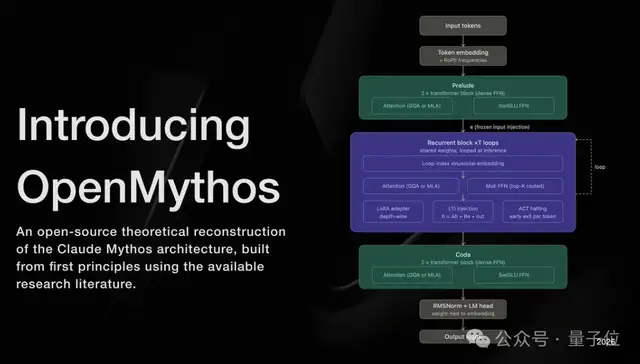
从技术实现来看,OpenMythos 构建了一个带有混合专家(MoE)路由机制的循环深度 Transformer(Recurrent-Depth Transformer,RDT)。该架构通过跨专家的权重共享和条件计算,实现了迭代深度的推理能力。
已有多项独立研究证实,此类架构在参数量减半的情况下,仍有望获得与传统深层模型相当的性能表现。
主导这一整合工作的开发者是 Kye Gomez,这位 22 岁的开发者同时也是 Swarms 智能体框架的创始人。

他设计的 RDT 架构主要包含三个核心技术特征:
- 同一组权重最多可反复循环调用 16 次
- 每次循环激活不同的专家路径
- 推理全过程在潜在空间(Latent Space)内完成
这三者的结合,旨在证明让模型对一个问题“思考更多遍”,比单纯堆砌参数量更为高效。
在过去两年中,行业的主流范式是堆叠上百层不同的 Transformer 层,每一层学习不同的特征,导致参数量急剧膨胀。而 RDT 架构仅需少量层数,通过最多 16 次的循环复用,每一遍都基于前一轮的计算结果继续深化。
针对“同一权重跑 16 遍是否浪费算力”的质疑,架构设计者给出了否定的回答。关键在于每次循环激活的是不同的“专家”子集。
循环块内部采用了混合专家层,MoE 路由器在每次循环中动态激活不同的专家组合。在具体设计上,借鉴了 DeepSeekMoE 的思路:包含大量细粒度路由专家,以及少量始终在线的共享专家。
Gomez 将这一设计理念总结为:
MoE 提供领域知识的广度,循环提供推理的深度。
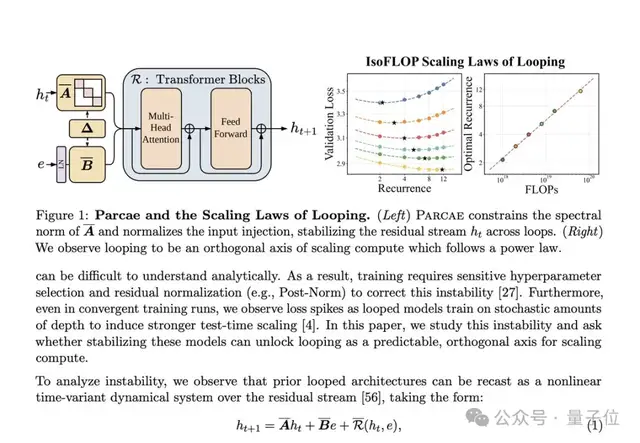
有了广度和深度,稳定性成为另一大挑战。必须保证循环过程不会导致梯度发散或逻辑崩塌。
来自 UCSD 和 Together AI 的新论文《Parcae: Scaling Laws For Stable Looped Language Models》提出了LTI 稳定循环注入机制,确保每一轮计算不发散。
实验数据显示,仅用 7.7 亿参数的 RDT 模型,即可追平 13 亿参数的标准 Transformer 模型效果。
这意味着参数量减少近一半,而性能保持一致。
架构的最后一块拼图是连续潜在空间推理。16 轮推理全部在 hidden state 向量中完成,不生成任何中间 token。直到最后一轮循环结束,才一次性输出答案。
这与思维链(Chain-of-Thought)截然不同。CoT 是“想一步,写一步”,中间过程完全暴露;而 RDT 是“想完 16 遍才说一句话”,推理过程完全内化。

此外,相关研究还引用了俄亥俄州立大学的论文,对循环 Transformer 架构进行了两项关键实验验证。

第一项:系统性泛化能力。
在训练时未见过的知识组合场景下,推理时循环 Transformer 仍能正确作答,而标准 Transformer 则直接失败。
这证明循环机制并非简单的重复计算,而是实现了真正的”更深层思考”。
第二项:深度外推能力。
训练时仅教授 20 跳推理链,测试时直接提升至 30 跳。
循环 Transformer 的应对策略是在推理时自动增加循环轮数,而标准模型则直接崩溃。
这些结果表明,当前大模型在预训练中已记忆大量事实,真正的瓶颈在于知识组合能力。它们难以将已知事实串联起来回答新颖问题,而循环架构似乎免费解锁了这种组合能力。
如果上述结论成立,未来 Scaling 的主流方向可能将从”训练更大的模型”转向“让现有模型在推理时多想几遍”。
有了这些研究支撑,Anthropic 的 Mythos 是否真的采用了这套架构,似乎已不再是唯一焦点。
对循环 Transformer 的猜想已经吸引了来自学术界的大量目光,更多理论和实验验证正在路上。
GitHub 项目地址:
从产业落地的角度审视,循环架构虽然理论上具备高效性,但在实际部署中仍面临推理延迟和工程化挑战。如何在动态循环次数与确定性延迟之间取得平衡,将是后续技术攻关的重点。此外,开源社区对专有架构的复现尝试,也反映了技术透明度与知识产权保护之间的张力。






