端侧AI翻译这件事,过去几年一直有个尴尬:要么模型太大跑不起来,要么跑起来了质量跟机翻没区别。但腾讯这次开源的Hy-MT1.5-1.8B-1.25bit,某种程度上把这两个问题一起解决了。1.25比特量化——注意,不是常见的4bit或2bit,而是比1.67bit还要激进——直接把模型从3.3GB压到440MB,推理速度反而快了10%。更关键的是,在FLORES-200等标准测试里,这个440MB的小模型居然跟商业翻译API、甚至Qwen3-32B这种百亿参数大模型打得有来有回。30个国际机器翻译冠军不是白拿的。
Tencent has officially open-sourced the compact AI translation model Hy-MT1.5-1.8B-1.25bit. The company claims that the model can run completely offline on smartphones while maintaining high performance. Currently, the model supports 33 languages and five dialects, including Chinese, English, German, French, Japanese, Tibetan, and Mongolian, covering 1056 translation directions, and has won a total of 30 championships in international machine translation competitions.
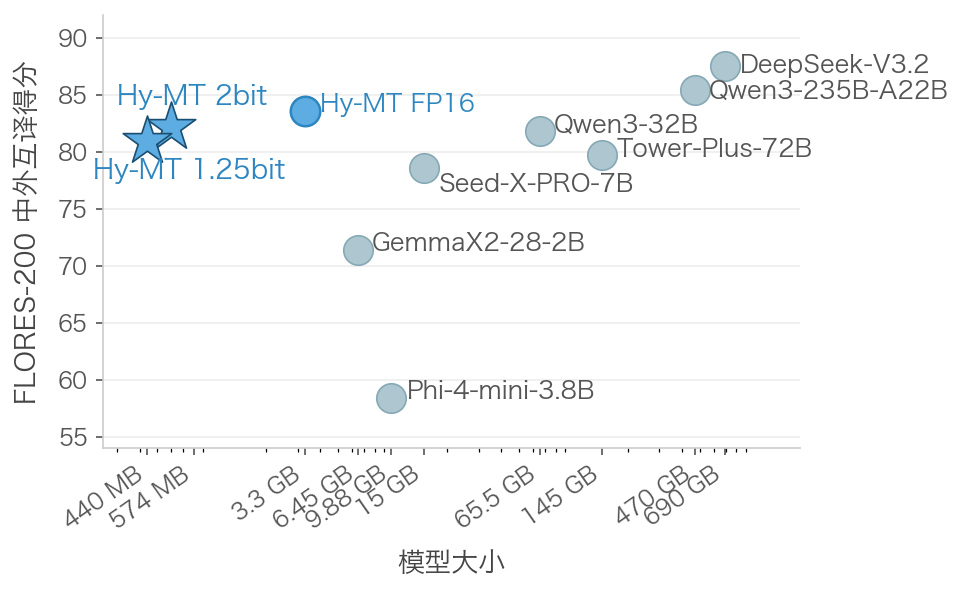
The core of the technical breakthrough lies in the “aggressive compression” scheme: through a quantization technology that uses only 1.25 bits per parameter, the model’s size is reduced from 3.3GB to 440MB, which is about 25% smaller than the previous 1.67-bit scheme, with a 10% increase in inference speed, and no loss in quality. In standard benchmark tests, the 440MB Hy-MT shows translation quality comparable to commercial translation services and large models such as Qwen3-32B, achieving a breakthrough of competing with hundred-gigabyte-scale models with a very small scale.
Currently, Tencent has provided an Android demonstration application (in APK format), supporting cross-screen offline translation of text within any mobile application. Industry observers point out that with Google’s launch of the localized model Gemma4, on-device AI has become the new front in technological competition. Through breakthroughs in quantization technology, Tencent Hy-MT has significantly reduced the computing power threshold for high-quality AI translation, providing a highly competitive open-source foundation for offline applications on intelligent terminals in complex privacy environments.
客观来看,这次1.25bit量化之所以能维持质量,核心在于训练后量化(PTQ)过程中对异常值分布的精细处理——传统量化容易在边界数值上崩盘,而Hy-MT用了一套非对称量化 + 混合精度切换的策略,把压缩损失控制在了几乎不可感知的范围。但话说回来,440MB对于手机端来说依然不算极致小,隔壁Gemma4的2B模型在4bit下也要1GB左右,而Hy-MT用更激进的位宽换来了更小的体积,不过代价可能是对特定硬件(如高通Hexagon DSP)的适配要求更高。未来如果能在1bit以下再做突破,端侧AI翻译才能真正做到“即下即用”的零门槛状态。