<img id=”wx_img” src=” width=”400″ height=”400″>
闻乐 发自 凹非寺
AI快讯网 |
虾在前,马当道,居然还有新物种能在Agent赛道突出重围。
OpenHuman连续霸榜GitHub Trending第一,狂揽9k+ Star,一天就涨千星。
和虾马不一样,Human不用你花心思养,还能反过来主动了解你。
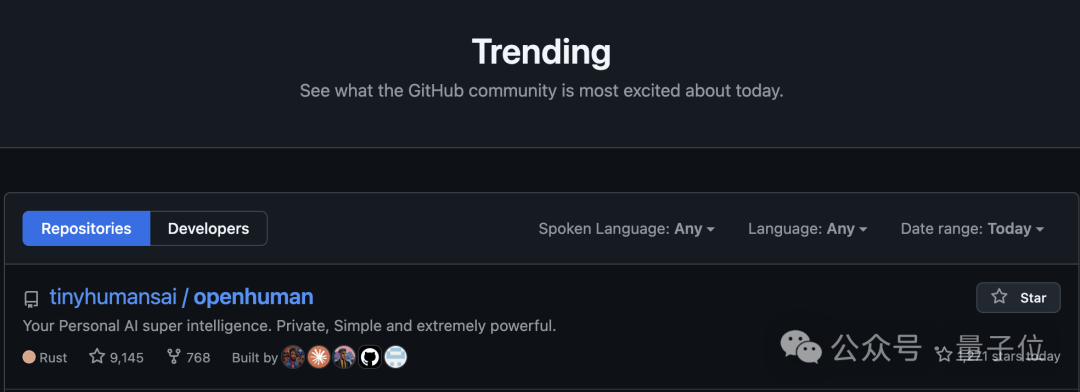
虾和马,本质还是你在教AI。你得配skill、写prompt、调工作流。
归根结底,你得先动,它们才动。
OpenHuman不需要你教,连上你的Gmail、GitHub、Slack、Notion、日历……118个服务一键接进来,每20分钟自动抓一遍新数据,压缩进一个卡帕西式的本地知识库。
一次同步跑完,直接对你工作生活的了如指掌。
没有训练期,没有磨合期,第一天上班就能干活。
谁懂啊,养虾养马已经养累了,终于来了个不用教的!
Karpathy之前公开了自己的一个工作流,叫LLM Wiki。
把所有笔记、文档、项目信息、待办事项,全部整理成结构化Markdown文件,扔进Obsidian里,让AI持续索引和理解。
这思路在技术圈火了一波,但问题是,这套操作全手工。
你得自己整理Markdown、自己分类、自己更新,一天不维护,知识库就馊了……
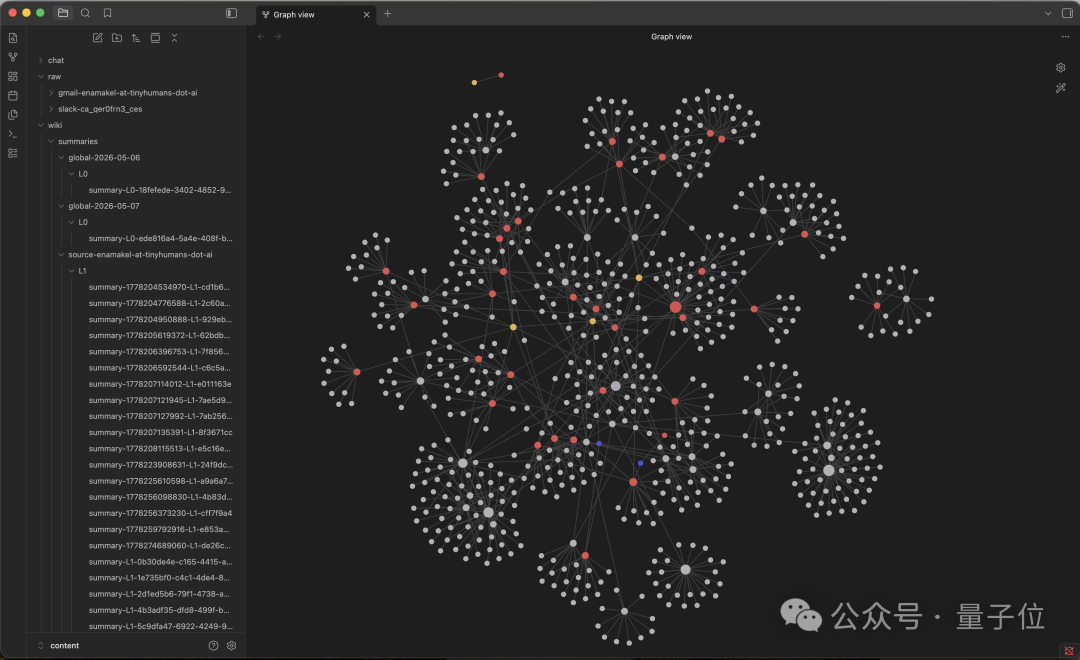
OpenHuman干的事,就是把卡帕西这套手工活,变成了全自动流水线。
总结成一个三步链路就是:连接→抓取→记忆树。
第一步,连。 目前OpenHuman支持118+第三方服务,Notion、GitHub、Slack、Stripe、Drive……覆盖了大多数人日常工作的核心工具。
每个连接都是一键授权,不需要你跑去每个平台手动生成API Key。
第二步,抓。 连接完之后,核心引擎每20分钟自动轮询所有已连接的账户。
新邮件、日程变更、代码提交、文档更新……全拉到本地。
你不用写任何prompt或轮询脚本,Agent自己知道什么时候该刷新。
第三步,记。 抓来的数据经过清洗和压缩,切成不超过3000个Token的Markdown片段,按主题、时间线、关联对象做评分和层级摘要,最终折叠成一棵记忆树。
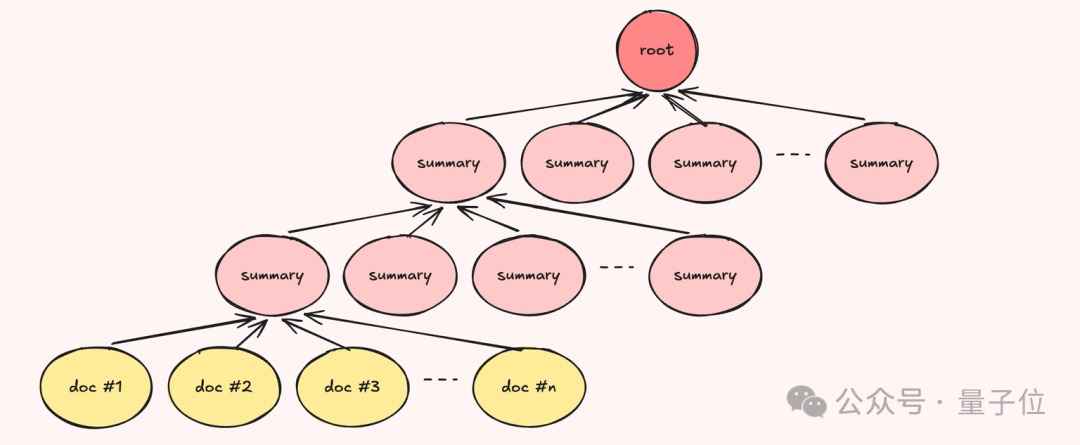
这棵树的本体是一个本地SQLite数据库。
但同一份数据,还会同步生成.md文件,落盘成一个兼容Obsidian的本地知识库,你可以直接用Obsidian打开、浏览、编辑Agent的“记忆”。
记忆树之外,还有个挺实用的设计,TokenJuice。
每次工具调用结果、网页抓取、邮件正文,在送到LLM之前,先过一遍压缩:
HTML转Markdown、长URL缩短、非ASCII字符清理、冗余信息去重。
这样一来,Token消耗能砍掉80%。

而且它用了三层规则叠加,内置默认规则、用户自定义规则、项目级规则,全以JSON文件存储,改了不用重新编译。
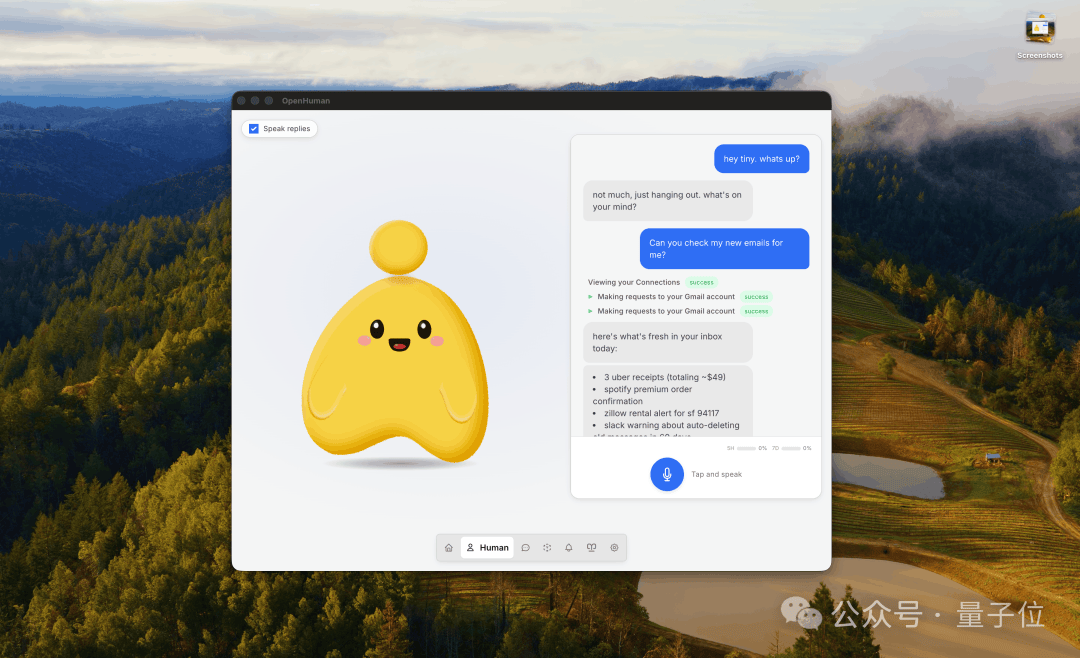
OpenHuman还有个Mascot功能,一个“会说话”的虚拟形象能作为独立参会者加入Google Meet会议。

你开会,它旁听记要点。你离开电脑,它在后台继续执行待办任务。
在潜意识循环机制下,即使你不主动跟它交互,它也会自己加载待办、读取近期记忆、自主决定还有什么可以干。
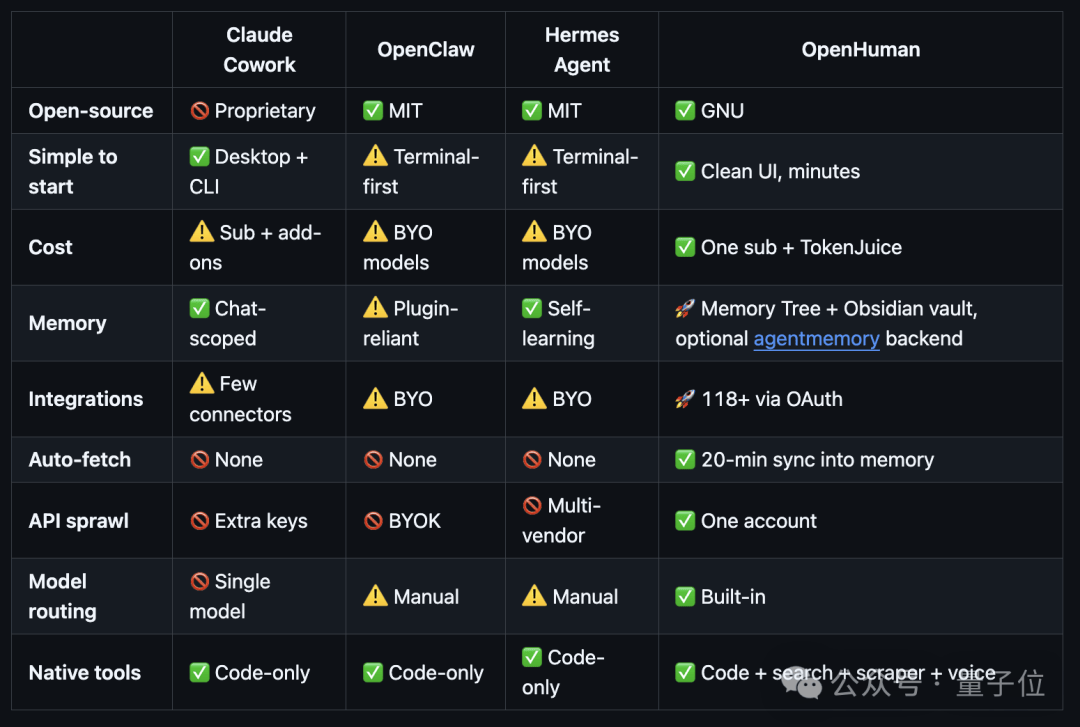
OpenHuman和Claude Cowork、OpenClaw、Hermes Agent主流Agent做了对比。
在上手门槛、成本、记忆能力、第三方集成、自动数据同步、模型调度等维度都具备一定优势。
虾马之后,OpenHuman还能火,可能还是因为它刚好踩中了三个让开发者很头大的问题。
API密钥一大堆、各类平台数据分散难整合、上下文臃肿导致AI越用越卡顿。
OpenHuman一个账号搞定所有,不用反复注册、不用到处配置密钥;
内置118+主流应用一键互联,自动拉取全平台数据同步进专属记忆树,全程后台静默运行、持续自主思考,最高还能节省80% token消耗与响应延迟。
而且,这三个痛点拆开是功能问题,合起来其实是还不够贴合用户真实使用习惯:
之前的Agent,心思都花在“能干”上了,但在“懂你”这方面,始终差了点意思。
虾解决工具多的问题,马解决能自学的问题,但懂你的,或许还得Human来(doge)。
项目地址: