重写:增加开头一段客观分析,比如对比其他模型,说明这个榜单的含金量。中间保持原信息,但语言更AI快讯网风格(比如用“刚刚”、“震惊”、“值得关注”等,但不要太夸张)。最后可以加一句展望。
注意:原文中有“图说:”等,可以保留。数据要准确。
最终输出纯HTML,去掉多余空格
刚刚,阿里千问又放了个大招。旗舰模型Qwen3.7-Max在Artificial Analysis最新全球大模型榜单上,以56.6分拿下全球第五、国产第一,性能直逼GPT-5.4、Claude-Opus4.7和Gemini3.1 Pro Preview。值得注意的是,这个榜单并非“自娱自乐”——Artificial Analysis是海外独立评测平台,采用多维度基准测试,含金量在业内公认很高,能挤进前五的国产模型此前几乎没有。
5月21日消息,三方机构Artificial Analysis公布了最新的全球大模型榜单,阿里新发布的旗舰模型Qwen3.7-Max得分56.6分,超过了Kimi-K2.6、DeepSeek-v4-Pro-Max、GLM5.1等所有国产模型,性能接近GPT、Claude、Gemini的最强模型,位列全球第五、国产第一。据了解,Qwen3.7-Max即将上线阿里云百炼对外提供API服务。
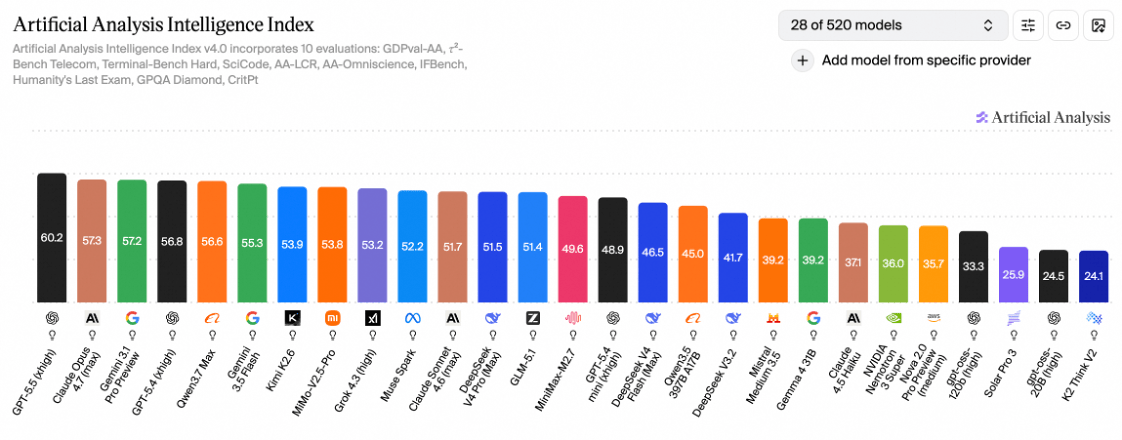
图说:Artificial Analysis官网截图显示,Qwen3.7-Max位列全球第五、国产第一
Artificial Analysis 是一个独立的 AI 大模型评测与分析平台,它对全球大模型进行多维度的基准测试和性能评估,形成系统性的大模型智能水平综合排名,因此该榜单也被业内公认为是最具影响力、含金量最高的大模型三方榜单之一。阿里千问大模型曾多次登上Artificial Analysis榜单前沿,1个月前发布的Qwen3.6-Max-Preview,就曾创下国产模型性能最佳。
如今,这一成绩再度被千问自身超越。在5月20日晚公布的最新一期Artificial Analysis 大模型总榜中,Qwen3.7-Max得分56.6,较上代旗舰模型进步4.8分,逼近GPT-5.4(xhigh)、Gemini3.1 Pro Preview、Claude-Opus4.7(max),在总榜的所有模型中排名第五,稳居国产模型第一。
据了解,Qwen3.7-Max为Agent智能体而创新设计,实现了编程、智能体、推理等核心能力的大幅突破。千问3.7可与Claude Code、OpenClaw、Hermes Agent、Qwen Code等各类Agent框架完美协同,通过自主编程和Agent工具调用,可独立完成35小时、超1000次工具调用的复杂长程任务,交付令人惊艳的生产级成果,可完美胜任企业级的复杂任务。
从榜单来看,国产大模型正在快速缩小与国际顶尖水平的差距,而Qwen3.7-Max在Agent和长程任务上的突破,也可能成为企业级落地的关键变量。值得一提的是,该模型即将通过阿里云百炼开放API,这意味着开发者将能直接调用这个“国产最强”的能力,后续实战表现值得持续跟踪。






