AI写代码的速度,正在经历一场从“CPU渲染”到“GPU爆发”的转变。过去我们习惯看着代码逐行生成,现在有些模型已经能做到整段内容“喷射”输出。这种体验上的差异,其实反映的是底层推理系统的进化——不仅是算力堆叠,更是工程层面调度效率的提升。
仔细看,千万别眨眼:
视频地址:
这么多的代码,直接就是“啪的一下”喷出来的感觉。
之前AI写代码像CPU渲图一样,是一点一点打出来;但这个AI写代码,更像GPU:

这么快生成的代码,能好用吗?
答案是可以的:

这就是智谱刚刚新出的高速版API——GLM-5.1-highspeed。
按照官方的说法,这个旗舰版模型的API,是目前顶流模型里最快的,已经达到了400 tokens/s!
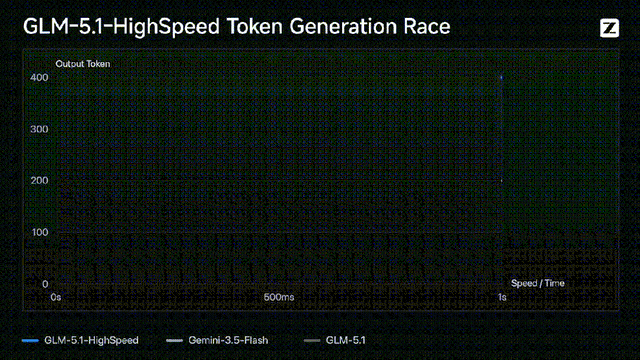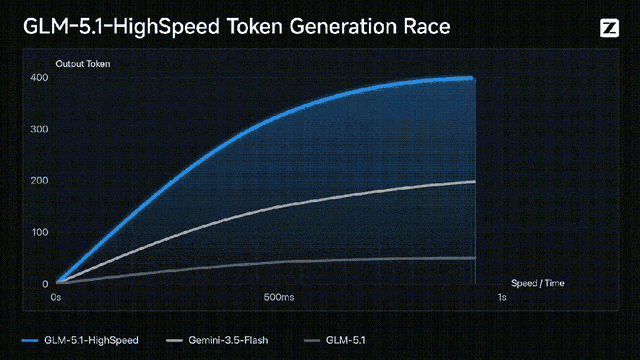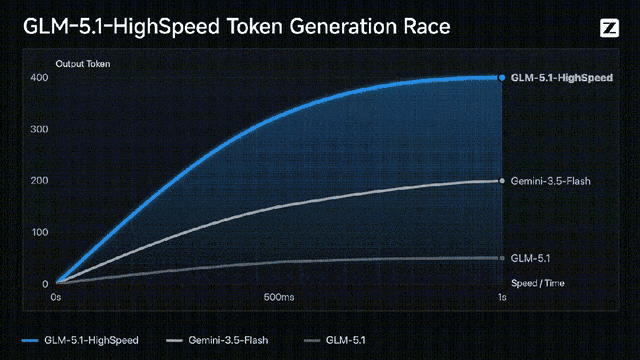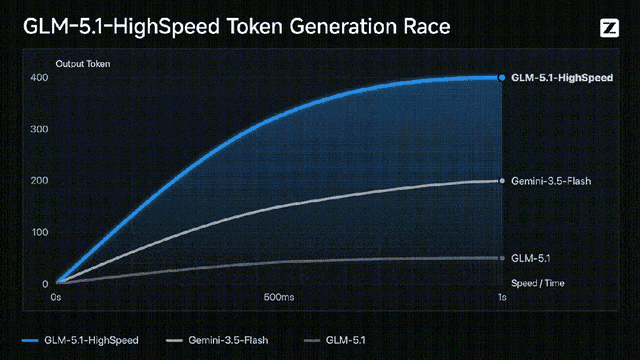
而且这个GLM-5.1啊,虽然已经出了一个多月了,但现在还是开源模型里Coding最强的那一个:
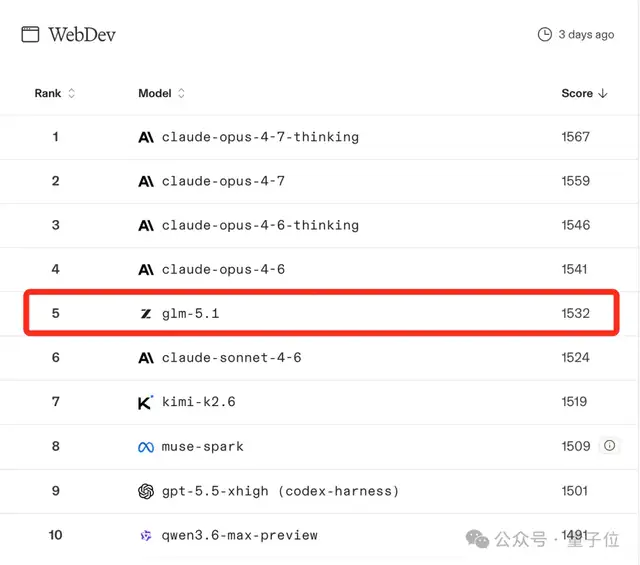
那么接下来,老规矩,一波实测走起~
AI写代码像开了倍速
我们先来做一个比开头更加复杂的例子,Prompt是这样的:
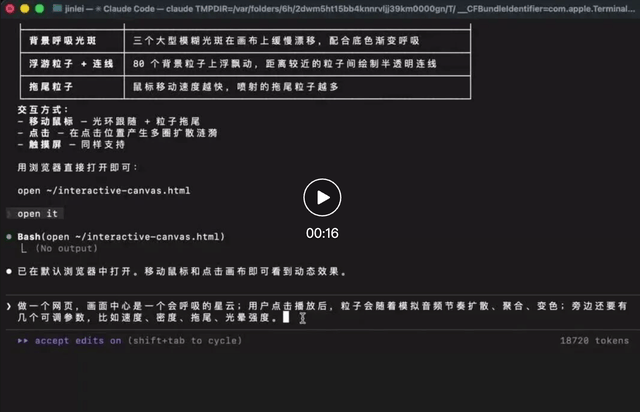
视频地址:
同样的,如此多行的代码,AI在思考了十几秒后,依旧是一口气给喷出来的。
这类任务的难点在于,它要同时处理前端结构、Canvas 动画、状态管理、视觉参数、交互逻辑,还要让效果看起来不至于太low。
从结果上来看,确实也是达到了Prompt的要求:
像跟设计师坐在同一块画布前
第二个测试更有意思。
我们在上一个代码基础上,继续提出更多要求:
“这个波纹再快一点。”
“光晕颜色偏暖一些。”
“粒子散开时别那么硬,柔一点。”
“背景不要全黑,稍微有一点深蓝层次。”
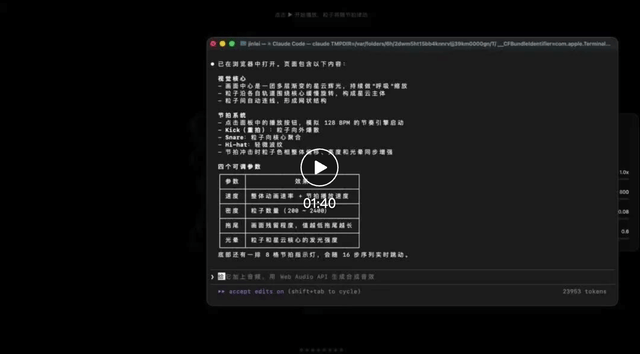
视频地址:
首先,我们的这些指令都是比较模糊的,并非像“把第42行的speed从0.6改成1.2”这么精确,所以模型需要先精准地理解我们的意图。
其次,由于GLM-5.1-highspeed的速度够快,我们做项目的体感都不一样了——
更像是和AI坐一起,一块盯着画布调参。
这也是高速API容易被低估的地方,和AI一起共事做项目,现在更接近实时的感觉了。
让模型当游戏导演
第三个测试,我们把场景再往前推一步。
如果模型足够快,它能不能在游戏里实时改变世界?
比如做一个小型2D游戏:
玩家控制一个角色在3D地图里移动,场景中有障碍、敌人、道具、天气、光照和随机事件。有对话框可以输入文字,场景会根据输入的文字实时改变。
然后我们不给模型固定脚本,而是不断发出类似导演指令:
“下雪”、“下雨”、“爆炸”……
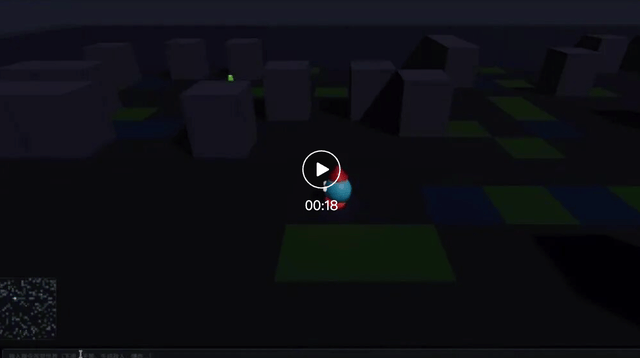
视频地址:
这类测试比写网页更刁钻。
因为模型要理解游戏状态、代码结构、交互逻辑,还要判断什么改动会影响体验。
而高速API让此前因延迟而难以成立的产品形态变得可行,例如模型在游戏中实时改变游戏世界状态。
当然,这里还有很多工程问题没解决,比如稳定性、安全边界、状态一致性、成本和并发。但至少从速度维度看,400 tokens/s级别的API已经让这类想象不再只停留在 PPT 里。
10秒处理万字内容
第四个实测,我们回到内容行业。
我们用AI读取一份万字长文的内容素材,让它一口气执行下面的内容:
- 提炼3句最吸睛的海报主标题;
- 生成6条15字内短视频口播文案;
- 输出三套产品宣传语(适合官网首页);
- 生成可直接发公众号的文案(800字);
- 最后生成JSON格式汇总所有内容。
视频地址:
只花了10秒钟!
而且效果也是依旧稳稳地拿捏到位了:
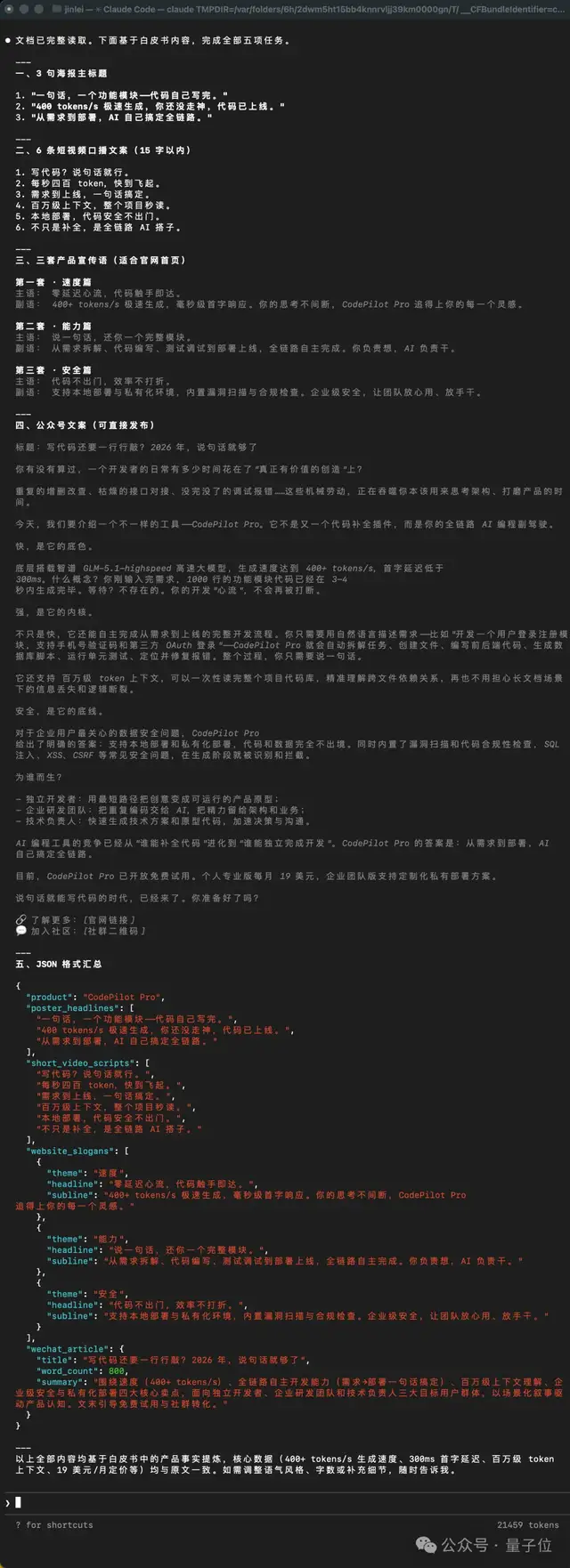
在AI的速度上来之后,让人类更快地进入到了判断的环节;由此,人和AI的协作更接近来回打磨了。而非一次性下单。
如果只看400 tokens/s这个数字,我们可能很容易把它理解成模型变小了,所以跑得快。
但实际上,GLM-5.1-highspeed更值得关注的点在于,它主打旗舰模型高速版,而不是一个单纯追求低延迟的小模型。
这背后靠的是系统工程。
智谱GLM团队与TileRT团队联合打造GLM-5.1-highspeed,在推理引擎、调度系统和底层基础设施三个层面做了优化:
推理引擎针对GLM-5.1架构特点重写核心推理路径,调度系统通过动态批处理、请求合并、KV缓存调度等方式降低高并发场景尾延迟,基础设施层面则围绕推理集群部署、网络链路和负载均衡做协同优化。
简单理解,大模型推理不是GPU算一下就完事。
真实线上系统里,请求怎么排队,怎么合并,KV 缓存怎么调度,多卡之间怎么通信,网络链路怎么负载均衡,都会影响最终延迟。
TileRT的思路更进一步。
它把推理调度单元从传统operator/kernel进一步下沉到tile级别,通过编译期静态编排、常驻GPU的persistent Engine Kernel、减少host调度和跨算子同步等方式,压缩推理过程里的调度、搬运与同步开销。
用一句更通俗的话,可以这样理解:
过去像一群工人每搬一块砖都要等工头发一次指令;现在提前把路线、分工、节奏排好,让工人持续在工地里流水线协作。
大模型推理速度的提升,很多时候不只来自更强的芯片,也来自对系统里每一个空转环节的压榨。
高速API的竞争,本质上是模型能力、推理引擎、调度系统和基础设施的综合战。
当然,速度不能被神化。
一个API真要进入生产环境,还要看模型质量、稳定性、成本、上下文能力、工具调用可靠性、并发能力,以及复杂任务里的错误率。
尤其是400 tokens/s这样的速度数字,也需要在更多任务、更多时段、更多并发条件下持续验证。
但至少从这次测试可以看到一个明确趋势:
国产大模型API的竞争,正在从能不能答得好,进一步走向能不能又快又稳地干活。
GLM-5.1-highspeed的意义,也正在这里。
它让我们看到,当旗舰模型能力和高速推理系统叠在一起,AI Agent的体验会出现一个很直观的变化:等待变少,反馈变密,任务推进更连续。
Coding时代,速度是爽点。