多智能体交互,正在成为世界模型的下一个关键战场。
当前视频生成模型在单智能体场景下已能做到不错的动作预测和视觉延续,但一旦进入“多个智能体共享同一世界”的设定,架构层面的瓶颈便暴露无遗——传统的位置编码和注意力机制从设计上就没有为多个主体预留接口。
近日,NVIDIA联合清华大学、多伦多大学与Vector Institute发布了Gamma-World(γ-World),从RoPE扩展和注意力拓扑两个底层组件入手,给出了系统性的答案。
论文标题:Gamma-World: Generative Multi-Agent World Modeling Beyond Two Players

多智能体世界建模:不是多路视频拼接
现有视频世界模型几乎都建立在单智能体假设之上:给定一个玩家的动作序列,预测该视角下的未来观测。但多智能体场景从根本上改变了问题的性质——模型不再只需预测「这个智能体接下来看到什么」,而是需要同时回答:
- 玩家A的移动应当在玩家B的视野中如何呈现?
- 两名玩家同时操作同一个物体,状态应当如何演化?
这不是「生成N段独立视频」的问题,而是「生成N个耦合视角对同一个演化世界的不同投影」。
技术层面这意味着三重一致性必须同时维护:
- 时间一致性:画面在时序上连贯;
- 跨视角一致性:A在B视野中的呈现与A自身轨迹吻合;
- 交互一致性:多个智能体对共享环境的操作在所有视角中产生一致的状态变化。
单智能体框架在设计上只保证了时间一致性,后两者从未被纳入考量——这是架构层面的结构性缺失,无法通过增加数据量或模型规模来弥补。
此前尝试的结构性局限
在Gamma-World之前,Solaris已经在双人Minecraft上取得了不错的结果,但它暴露出的两个结构性问题,恰恰说明了为什么将单智能体框架直接「扩展」到多智能体,是一条走不通的路。
其一,身份编码破坏了对称性。Solaris为每个玩家分配固定的可学习槽位身份向量,实质上将「1号槽」和「2号槽」学成了两种不同的角色类型。在真实的多智能体世界中,能力相同的玩家本质上可互换,这种对称性的缺失使模型学到的是「特定角色的交互模式」,而非「多个平等主体共享世界的规律」,泛化性从根本上受限。
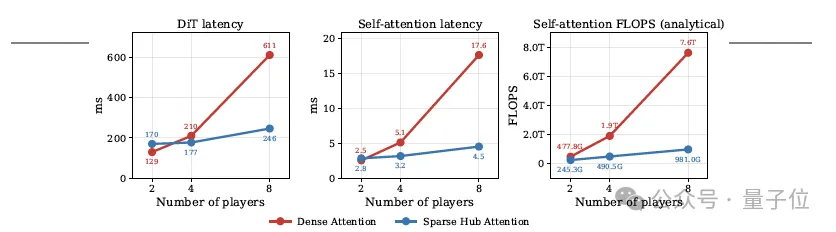
其二,全连接注意力存在扩展性天花板。让所有玩家的token两两直接交互,计算成本随玩家数量平方增长——从2人扩展到8人,计算量从477.8G增至7.6T,增长约16倍。这是算法复杂度决定的天花板,无法通过工程优化解决。
两个问题指向同一个结论:多智能体世界模型需要的不是修补,而是对两个核心组件的重新设计——如何表示智能体身份,以及如何设计跨智能体通信。
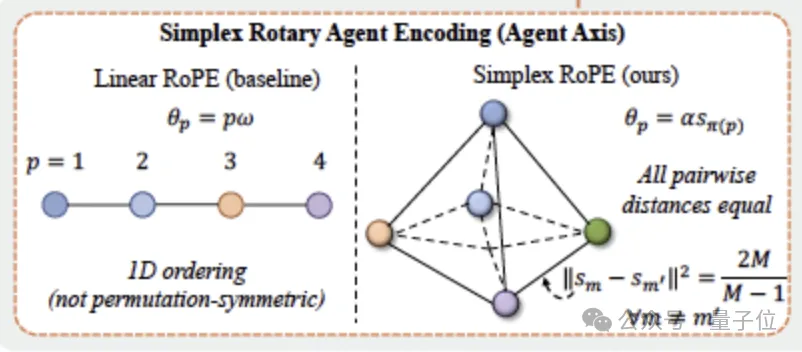
方案一:单纯形旋转编码 —— 让对称性成为架构的一部分
核心矛盾在于:如何让模型既能区分不同的玩家,又不让任何玩家在表示上比其他玩家「更特殊」。
视频Transformer用RoPE(旋转位置编码)来表达位置关系——给每个信息片段分配一个旋转角度。标准视频RoPE编码三个轴:时间、高度、宽度。Gamma-World加了第四个轴——玩家轴,在不改变原有时空编码的前提下,为智能体身份单独留出一个维度。
但这个玩家轴上的编码怎么设计?直接编号行不通——1号和2号差1,1号和3号差2,置换对称性被编码方式本身直接破坏。可学习的槽位嵌入也不行——每个座位绑定一个固定的可训练向量,模型被锁死在训练时的玩家数量上。
Gamma-World的解法很优雅:把所有玩家放在一个正单纯形(regular simplex)的顶点上。
- 2个玩家 → 线段的两端
- 3个玩家 → 等边三角形的三个顶点
- 4个玩家 → 正四面体的四个顶点
无论哪两个玩家,他们在旋转角空间里的距离完全一样。这个编码不需要任何可学习的参数。训练时活跃玩家被随机分配到顶点池里的不同位置,模型只能靠几何坐标来认人。推理时想支持更多玩家,从同一个顶点池里多取几个顶点即可,架构不用改,也不用重新训练。
这一设计的精妙之处在于:它把对称性先验直接硬编码进了架构,而非期待模型从数据中隐式学习。
方案二:稀疏枢纽注意力 —— 从“全连通图”到“轮辐式拓扑”
跨智能体通信以往方案的代价过高——让所有玩家的所有token两两直接交互,计算成本随玩家数量平方增长。问题的根源在于一个错误的假设:每个token级别的细节都需要在所有玩家之间直接传递。
Gamma-World引入一组可学习的hub token(枢纽token),构成轮辐式拓扑:每个智能体只与自身历史及hub token交互;hub token汇聚所有智能体的信息压缩为共享状态摘要,再广播回各智能体流。不同智能体之间的直接注意力被完全屏蔽,信息经由两跳传递:智能体→hub→智能体。
这一结构将计算成本从平方复杂度压至线性复杂度。值得强调的是,稀疏枢纽注意力不只是节省了算力,它本身也是一个更合理的归纳偏置——在架构层面显式编码了「跨智能体信息应经过共享世界状态瓶颈」这一先验。
方案三:三阶段训练 —— 兼顾质量与实时性
扩散模型里,双向模型质量最高但无法流式推理,因果模型支持实时生成但质量下降。Gamma-World用三阶段训练在两者之间架桥。
- 训练双向教师:教师模型可访问完整序列,提供最高质量的生成分布,仅用于训练,不参与推理。
- 训练因果学生:学生模型只能看到当前及过去的帧,结合稀疏枢纽注意力适配流式推理。关键点在于:学生被完整训练为多步扩散模型,而非仅作为蒸馏热身。
- 条件Self-Forcing蒸馏:以因果学生为起点、双向教师为目标,通过分布匹配蒸馏(DMD)将多步采样压缩为4步采样。蒸馏在自回归self-rollout下进行,与推理分布对齐,有效缓解误差累积,最终实现24 FPS流式推演。
实验结果与分析
全面超越现有最强。在多人Minecraft环境的五类场景中,对比帧拼接方案和Solaris,Gamma-World在记忆、空间定位、移动、建造、跨视角一致性五个场景全面领先,关键指标FVD平均降幅超过40%。
消融:每一步设计都有实际效果。从「学习槽位身份」换成「单纯形编码」,FVD从256.3降至228.5,没有增加任何参数,仅通过改变编码方式就带来了整个消融中最大的单步增益。这证明:在架构中显式编码置换对称性约束,比让模型从数据中隐式学习这种结构,在样本效率和最终性能上都有显著优势。
双人训练,四人直接跑通。模型仅在双人数据上训练,推理时从顶点池中启用两个新顶点,直接生成四路同步视角,无需修改任何架构参数。这一结果直接验证了单纯形编码的核心设计目标:泛化到任意玩家数,不需要见过那个玩家数的训练数据。无论是Solaris、Enigma Labs的Multiverse还是Odyssey的Agora-1,这些工作都缺乏这样的拓展泛化能力。

在「放置与挖掘」任务中,两路视角实时同步,一方的操作在另一方画面中得到正确反映。在「建造塔楼」任务中,双方协同搭建的方块在各自视角里位置一致。当玩家暂时移出对方视野时,模型仍能维持正确的空间定位——说明模型追踪的是共享的潜在世界状态,而非独立生成各路视频后拼在一起。
从虚拟到物理:框架的通用性验证
研究团队将Gamma-World应用于RealOmin-Open数据集的真实双臂机器人协同任务,以左右两条机械臂分别作为独立智能体。生成的未来帧保持了双臂的协同运动与空间布局,同一套框架从Minecraft多人场景直接迁移至真实物理操作,无需额外适配。
这一结果验证了多智能体世界模型框架本身的通用性。往更远处想:现实世界中几乎所有有价值的场景,本质上都是多个主体在共享环境中协作或博弈——手术室里的多臂协同、工厂产线上的多机器人调度、自动驾驶中的多车交互。如果一套统一的多智能体世界模型框架能够覆盖这些场景,它所代表的就不只是仿真能力的提升,而是为整个Physical AI领域提供了一个全新的数据生产和策略训练基础设施。
总结与思考
Gamma-World的三项核心设计——单纯形旋转智能体编码、稀疏枢纽注意力、条件师生蒸馏——分别对应多智能体世界建模中三个长期悬而未决的问题:身份的对称表示、交互的高效建模、质量与实时性的同时兼顾。每一项都不是修补,而是在确认原有路径走不通之后,从更底层的建模原则重新给出的答案。
三项设计背后有一个共同的方法论:将对问题结构的理解直接编码进架构,而非期待模型从数据中自行发现。一个真正理解多智能体世界的模型,应当在结构上就是对称的,而不是见过足够多的数据之后,碰巧学出了近似对称的行为。Gamma-World零样本泛化到四人场景的结果,正是对这一判断最直接的实验验证。
这一方法论也指向一个更大的可能性:当多智能体世界模型的生成质量足以忠实还原真实物理规律,训练数据的采集方式本身就会发生根本性转变——从依赖真实场景的物理采集,转向由神经网络驱动的大规模模拟生成。从方块世界到机械臂,Gamma-World迈出的是验证性的第一步。真正的世界模型,学会的不该只是「画面」,而是「规则」。
论文:Gamma-World: Generative Multi-Agent World Modeling Beyond Two Players
机构:NVIDIA / 清华大学 / 多伦多大学 / Vector Institute
项目主页:https://research.nvidia.com/labs/sil/projects/gamma-world/
GitHub:https://github.com/nv-tlabs/Gamma-World
Huggingface:https://huggingface.co/nvidia/GammaWorld