Yann LeCun豪赌的世界模型路线,如今有了一支来自深圳的新势力提前落子。他们正是打造出全球首个视觉大模型——Grounding DINO和DINO-X——的团队。这家名为「视启未来」的公司,显然不满足于让AI仅仅“看见世界”,而是试图将其推向“预见未来”的能力边界。

他们的新赌注,是隐空间世界模型。要知道,这条技术路线极受关注,LeCun为此离开Meta、创办AMI Labs,并完成10.3亿美元融资,创下欧洲史上最大种子轮纪录。与主流的下一帧画面预测不同,隐空间世界模型要求AI在一个更抽象的表征空间里,学习动作与状态演化之间的因果规律。
在近期一场关于AGI的论坛上,视启未来创始人张磊直言:“做世界模型很难,做隐空间世界模型更难,但我们会知难而进。” 这番表态背后,是对技术本质的深刻洞察。

为何隐空间世界模型是更难的路?
随着AI从数字世界走向物理世界,智能体的核心任务已发生质变。它不仅要“看见”,更要“预见”——理解因果关系,把握时空动态,在稀疏反馈与复杂约束下完成规划与决策。强化学习虽提供了基本范式,但在物理世界中,样本效率低、安全约束严、交互成本高,单纯依赖在线试错难以扩展。
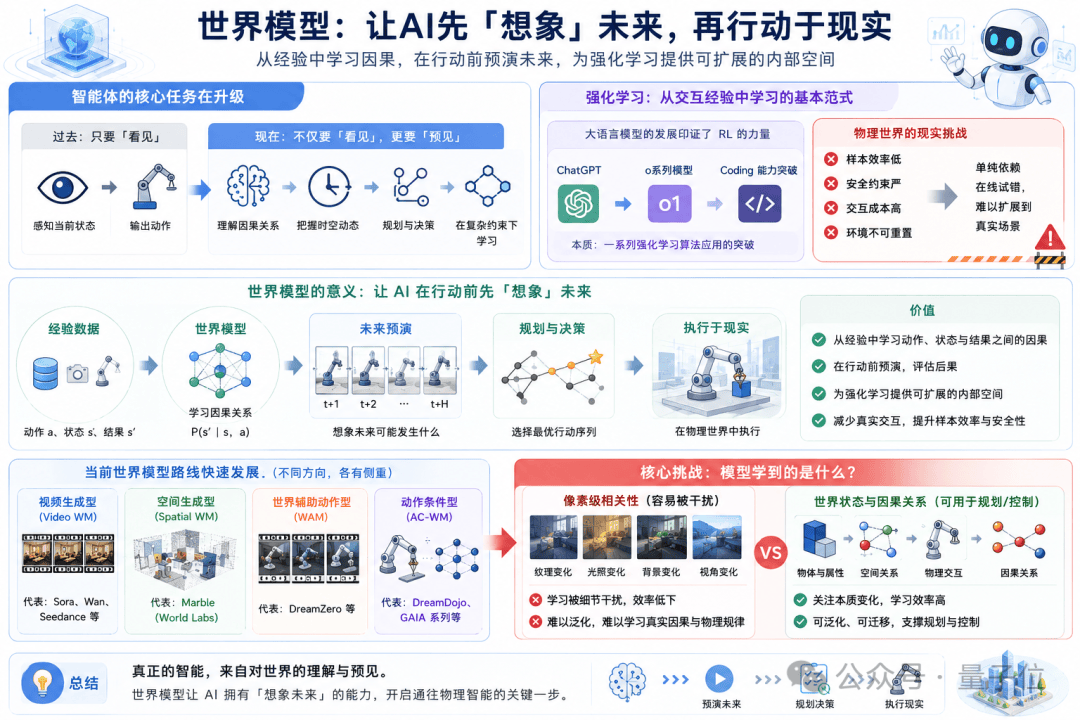
张磊的判断是,真正的智能不能停留在“看到当前状态就输出动作”。如果没有对未来状态的预想、对行动后果的预判,智能体无法在物理世界中持续展开决策链条。这正是世界模型的意义:让AI从经验中学习动作、状态与结果间的因果关系,在行动前先“想象”下一步的可能。
但一个核心挑战始终存在:模型学到的,究竟是像素级相关性,还是可用于规划的物理规律与因果关系? 在像素层面学习,容易被纹理、光照、背景等细节干扰,学习效率低下。这正是LeCun所说“在输入空间做预测是糟糕的”的原因,也是隐空间世界模型的出发点。

Latent表征的价值,在于将高维、冗余的视觉输入压缩成更抽象的状态表示,过滤掉无关像素细节,将学习重点放到本质变化规律上。换言之,隐空间世界模型不执着于“未来画面长什么样”,而更关注“世界状态如何演化”,因此更适合学习物理规律。但视启发现,现有方案还差关键一步:大多数latent表征虽脱离了像素,却并不真正“理解物体”。如果模型不知道场景里哪些是独立物体、物体间有什么关联、哪些变化来自视角或交互,那么直接在隐空间学习物理规律,难度依然极高。
原因很简单:物理规律本质上不作用在像素上,而是作用在物体、结构和关系上。张磊认为,latent表征必须具备理解物体的能力,才能更好地学习物理规律。视启的解法是把物体理解能力引入latent表征学习,通过2D感知、3D表征、分割和语义理解,让latent表征具备“世界由哪些物体构成、它们处于什么空间位置、具有什么语义属性”的基础认知,再进一步学习动作驱动下的状态转移。
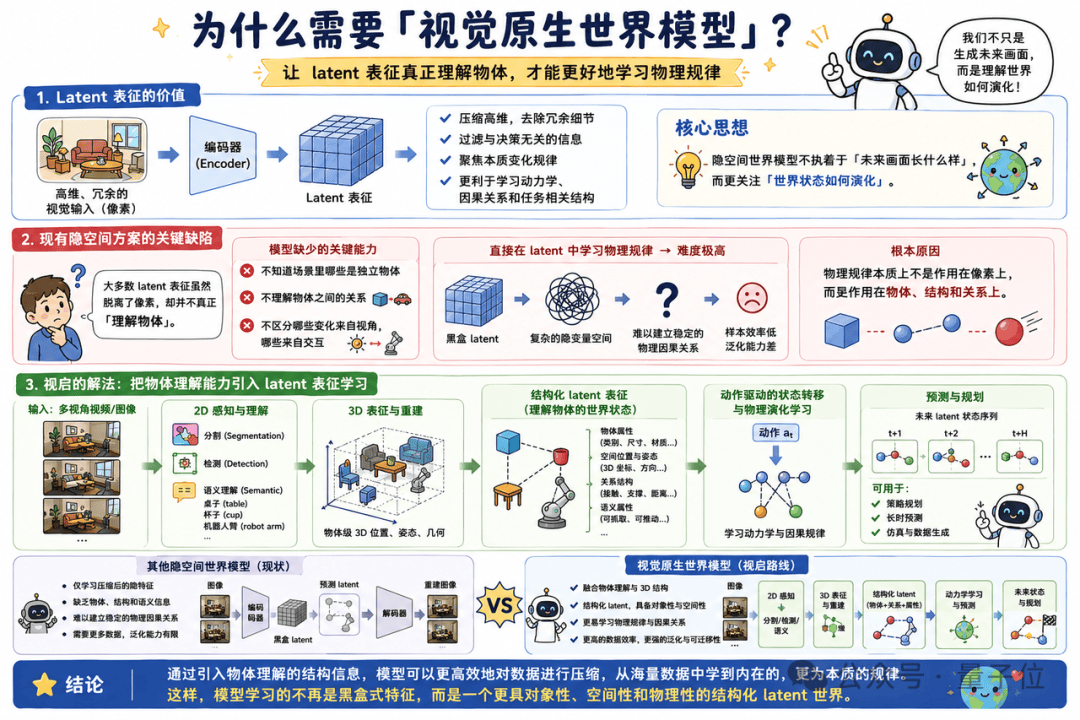
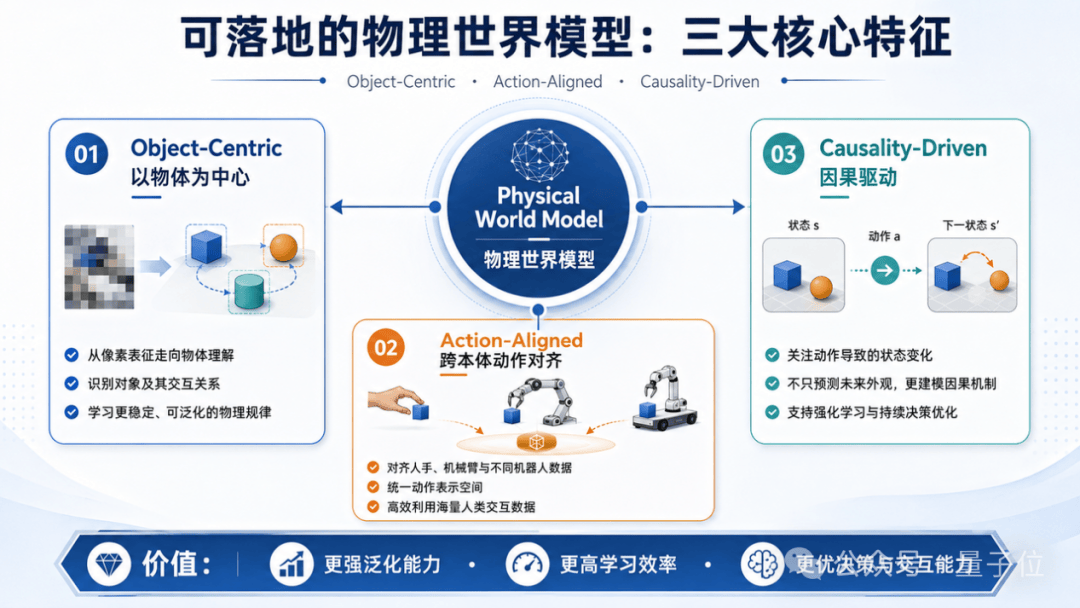
因此,视启将自己的路线称为「视觉原生世界模型」,这是他们与其他隐空间世界模型的关键区别。为实现真正可落地的物理世界模型,他们提出了三大核心特征:Object-Centric(以物体为中心,表征需理解对象与交互)、Action-Aligned(跨本体动作对齐,将人手、机械臂等不同数据统一表示)、Causality-Driven(因果驱动,学习“执行动作后世界状态如何变化”)。
从视觉大模型到世界模型:一条顺势延伸的路径
张磊的见解并非空穴来风。背后是视启长期构建的、以物体为中心的视觉理解能力。这支团队核心来自粤港澳大湾区数字经济研究院计算机视觉与机器人研究中心(IDEA CVR)孵化的DINO-X团队,已连续推出DINO、Grounding DINO、DINO-X等代表性工作。Grounding DINO已成为开放集检测的重要里程碑,而DINO-X则是面向开放世界物体理解的全球领先视觉大模型。
值得注意的是,DINO系列论文广泛被Meta的SAM2/SAM3、阿里的Qwen系列、字节的Seed系列引用。自2023年以来,视启未来凭借这些成果,在开放物体理解榜单上保持了最长的连续领先时间。DINO系列解决的核心问题,正是Object-Centric世界模型最需要的底层能力:让机器“看懂”世界由哪些物体构成、它们在哪里、它们之间是什么关系。
从模型到产品,这种能力已经开始落地。近期,视启未来联合百度智能云正式发布EgoTwin——全球最新的高质量Ego人手3D对齐引擎。它直击行业最卡脖子的难题:把人手操作数据转化为机器人能用的训练数据,数据采集效率是行业主流方案的3.75倍。EgoTwin不仅是数据采集工具,更是为世界模型提供Action-Aligned训练底座的关键一环。

张磊的愿景是:世界模型将成为物理世界AI的核心基础设施。在他看来,数字世界中,大语言模型正承担类似操作系统的角色,而物理世界同样需要一种范式变化。英伟达科学家Jim Fan曾预言,2026年将载入史册,成为世界模型为机器人技术奠定真正基础的第一年。张磊支持这个判断,并强调视觉是物理智能最主要的信息入口,也是通向世界模型的关键优势方向。

重新审视:一场需要持续验证的技术长跑
从客观角度分析,隐空间世界模型的前景虽然诱人,但技术挑战依然不容忽视。首先,如何在保持抽象表征的同时,确保模型不丢失对关键物理细节的建模能力,是一个需要精细平衡的问题。其次,世界模型与强化学习的结合,目前在学术界仍处于探索阶段,距离大规模商业应用还有距离。视启未来虽然在物体理解上具有先发优势,但世界模型赛道竞争激烈,包括DeepMind、OpenAI在内的巨头均已入局,这注定是一场需要持续投入的长跑。
然而,视启的独特之处在于,他们并非从零起步。基于DINO系列积累的视觉基座大模型预训练能力,以及团队在数据组织、预训练范式上的系统方法,为隐空间世界的构建提供了扎实的底层支撑。连续做出多项全球领先成果,更多说明的是团队底层能力已经成型——这种能力既包括做模型的技术,也包括数据组织与能力迁移的系统方法。
从战略角度看,张磊带领的团队选择了一条更难但也许更正确的路。在所有人都向像素空间冲刺时,视启在隐空间方向上积累了先发优势。这种选择能否最终兑现为物理世界智能的突破,还需要更多时间与成果来验证。但可以确定的是,这支曾经做出全球首个视觉大模型的团队,正将同样的信念押注在隐空间世界模型上,走上了一条知难而进的探索之路。






