高一致性、低延迟、实时超分全梭哈
梦瑶 闻乐 发自 凹非寺
AI快讯网 |
AIGC发展到今天,生成几秒钟的AI视频已经不是什么新鲜事。
难点在于,让同一个角色在几分钟里始终保持一致——多镜头切换时脸不会变,换场景时衣服发型不会飘,人物开口时音色能前后接上。
问题不在模型“不会造梦”,而在于它很难“记住”这个梦。目前行业内大多数视频模型在处理长时序内容时,都存在记忆衰减的问题,早期生成的角色特征会随着时间推移被新信息覆盖,导致前后不一致。

△AI生成
也正因如此,长视频生成迟迟未能进入全行业的生产流程,更别说大规模商业化。从技术角度看,长视频不仅需要模型具备更强的记忆能力,还需要在推理速度和画质之间找到平衡点,这对现有架构提出了更高要求。
在长视频生成集体卡壳的当下,刚刚,有团队给出了一套新解法——开源长音视频生成框架JoyAI-Echo,并杀入全球长视频生成领域“第一梯队”。
把长视频创作里角色一致性、音色稳定性、生成速度和画面质量等生成痛点,一把梭哈。
哪怕是几分钟的视频,多镜头、多场景、多段语音连续切换,人物形象和声音也能稳稳稳住。

不仅如此,支持对话式编辑的Agent能力也一起安排上了,以后做视频就像和导演聊天一样。
再仔细一看,这套高性能开源框架,竟然来自京东?!
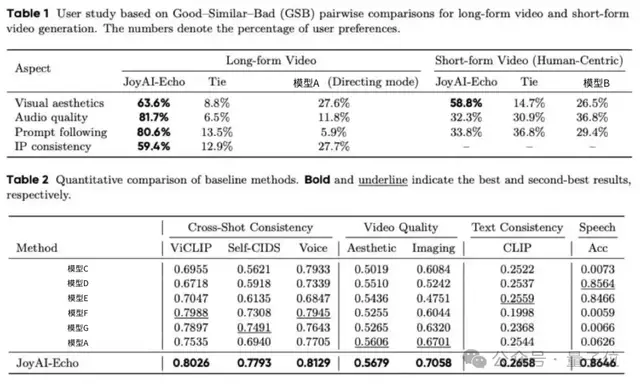
评测显示,JoyAI-Echo在跨镜头一致性、语音准确率(0.8646)等指标上全面领先行业,用户偏好达59.4%-81.7%。
一个可交互、高一致性、可持续迭代的长视频时代来了。
过去一年,AI视频模型的竞争重点多集中在几秒到几十秒片段:画质、运镜、风格、物理合理性。各家模型效果确实肉眼可见地提升,各类评测表现也很漂亮。
但在AI视频生成似乎进入成熟期的今天,一个问题依然没有被真正解决——长视频生成。
原因很简单:长视频,对整个行业来说都“太难了”。

相比短视频生成,长视频不仅是在时间维度上的简单拉长,更意味着跨镜头、跨场景、跨动作的连续叙事。从技术角度看,长视频生成需要解决的核心问题包括:模型错误累积、长程时序一致性弱、推理延迟高,这些都是当前扩散模型架构在处理长序列时的天然短板。
目前行业里的长视频生成,仍然普遍存在几个长期困境:说话人的音色忽高忽低;生成速度也慢得离谱,往往要等上好几分钟才能看到结果。
这些问题背后,暴露的是当前模型在长时序生成上的天然挑战:模型错误累积、长程时序一致性弱、推理延迟高。
最终导致视频里的人物变脸,声音飘忽,生成耗时漫长。这些问题直接限制了AI视频在虚拟叙事、数字人助手、实时内容创作等场景中的进一步落地和规模化应用。

△AI生成
而JoyAI-Echo给出的解法是,通过跨模态音视频记忆库、记忆驱动后训练、轻量化实时超分让长视频生成更稳。这种多模块协同的设计思路,相比单纯扩大模型参数或增加训练数据,更能针对性地解决长视频生成中的实际痛点。
长视频生成最让人头疼、行业最难啃的一块骨头,就是角色和声音的“前后不一致”。
在JoyAI-Echo团队看来,问题的根源在于现有模型缺乏真正意义上的长期记忆能力。
行业里传统方案通常依赖上下文窗口保存历史信息,但随着视频长度增加,早期内容会逐渐被后续信息稀释。模型虽然能够记住最近几个镜头,却很难稳定保存数分钟之前的人物特征。
而JoyAI-Echo的做法是——直接在框架里塞进了一套“跨模态音视频记忆库”。
与其让模型记住所有历史内容,不如把最关键的身份信息保存下来,并在后续生成过程中持续调用。这样一来,即便视频长度来到5分钟,角色的身份、外观和声音依然能够保持高度一致。
这套记忆库最大的特点在于,它记录的不只是人物长相,还会同步记录说话人的音色,并将两者绑定在一起。当角色首次登场时,系统会提取其视觉特征和声音特征写入记忆库;后续每生成一个镜头,都会从记忆库中调取这些信息作为参考。
为了兼顾效果和效率,系统也不会无限扩展记忆,而是保留故事开头的关键镜头,以及最近生成的镜头。这样既不会忘记主角最初长什么样,也始终知道剧情刚刚推进到了哪里:
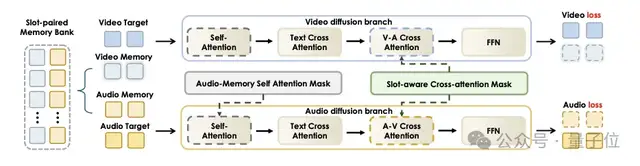
所以说JoyAI-Echo并不是让模型拥有更大的记忆力,而是让模型学会像人一样记忆——只保留最重要的信息,并在需要的时候准确调用。这种选择性记忆机制,在技术上更符合长视频生成的实际需求,也避免了存储和计算资源的浪费。
对于长视频生成来说,一致性只是第一步,生成速度同样决定了产品能不能真正落地。
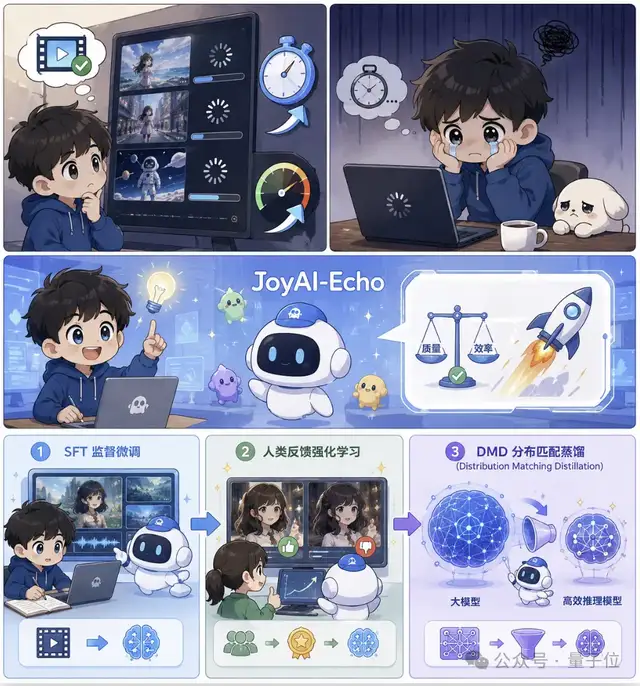
为此JoyAI-Echo团队在模型训练之外,又专门设计了一套记忆驱动的后训练流程,在不牺牲生成质量的前提下,把推理效率再往前推一步。
整个流程主要分为三步,首先通过SFT监督微调,让模型学习高质量音视频生成能力。随后利用人类反馈强化学习进一步优化人物一致性、画面质量以及音画同步效果。最后再通过DMD(Distribution Matching Distillation)技术,将复杂的大模型能力压缩到更高效的推理模型中。
△AI生成
在整个后训练体系中,DMD是最关键的一环。仅DMD相关优化就带来了约7.5倍的推理速度提升。
我们可以把DMD理解成一次“能力浓缩”——先让一个能力更强、但推理速度较慢的教师模型完成完整生成流程,再让一个更加轻量的学生模型去学习和复现教师模型的生成结果。

这样一来,原本需要大量扩散步骤才能完成的生成任务,被压缩成更少的推理步骤,模型却依然能够保持接近的生成效果。这种蒸馏技术在当前AI视频领域并不罕见,但JoyAI-Echo将其与记忆机制结合,针对长视频场景做了专门优化。
如果说跨模态音视频记忆库解决的是“不要忘”,那么这套后训练体系解决的就是“别太慢”。一个负责守住长视频的一致性,一个负责提升长视频的生成效率,两者结合才让JoyAI-Echo真正具备了迈向长视频生产工具的基础能力。
一致性有了,速度也上来了,但长视频生成还有最后一道坎儿——清晰度。在数字人、品牌营销、短剧创作这些场景里,谁也不希望最后拿到的是一个糊糊的视频。
当前业内通常采用“视频生成+离线超分”的两阶段架构——视频先生成,再交给独立超分模型处理。这种方案虽然也能提高分辨率,但额外引入了一轮推理流程,不仅增加等待时间,还容易造成生成结果和超分结果的偏差。

△AI生成
而JoyAI-Echo给出的解决方法是,创新性地把超分能力直接塞进生成链路里。具体来说,系统会先生成720P视频和对应音频,再通过轻量化实时超分模块一步完成高清视频和音频细节增强。整个超分过程只需要一次向前推理,就能直接输出1K甚至2K分辨率结果。
这样不仅画面细节更丰富,音频质量也会同步优化。整个过程不会明显增加生成延迟,用户也终于不用在“速度”和“清晰度”之间做选择。对于数字人直播、实时创作、内容互动这些对延迟极其敏感的场景来说,高清输出不卡顿,这才是关键突破。
现实中的影视制作,从来不是一次完成的。从剧本、分镜到拍摄、审片,再到返工和重拍,每一个环节都需要反复打磨。如果某个镜头出现问题,创作者往往只能重新生成整条视频,不仅耗时,也很难保证前后内容的一致性。这也是AI长视频长期难以真正进入生产环节的原因之一。
这个问题,JoyAI-Echo技术团队也想到了,于是给视频模型配了一位“AI导演”——Director Agent。用户只需要用自然语言说需求,它会自动帮忙拆分成剧本、角色、场景和镜头。
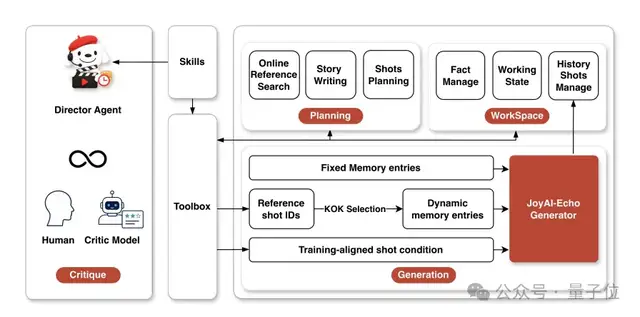
具体来说,Director Agent整个技术链路被拆成:策划、生成、点评修改三个阶段。
在策划阶段,Agent更像一位“编剧兼导演”。它会先理解用户意图,将一句自然语言需求扩展成完整的故事框架,补充角色设定、场景信息和叙事逻辑,再进一步拆解为镜头级规划,最终生成符合模型训练格式的结构化条件。
进入生成阶段后,Agent又变成了一位“现场导演”。它会根据当前镜头内容,从已经生成的历史镜头中检索最相关的信息,并将这些参考内容与当前剧本状态一起整理成模型需要的输入条件,让生成模型能够准确调用角色、场景和剧情上下文。

△AI生成
最后来到“点评修改”阶段,这里反倒更像影视制作里的审片环节。无论是用户反馈,还是自动评价模型发现问题,只要角色形象、动作表现、对白内容或音画同步出现偏差,Agent都能快速定位到具体镜头,重新调整对应条件和记忆信息。
更重要的是,Agent只对受影响的部分进行重生成,而不需要推倒重来,修改后的结果还会同步更新到后续剧情中,确保整个故事始终保持连贯一致。这种局部修改能力,在工业级内容生产中是关键需求,也是从技术Demo走向真正工具的重要一步。
从官方评测数据来看,JoyAI-Echo在长视频生成的多个关键指标上,都展现出了领先表现。
在用户盲测环节,研究团队将JoyAI-Echo与目前代表性的长视频模型进行了对比,结果显示——在长视频任务中,用户有63.6%的情况下更喜欢JoyAI-Echo生成的视频画面。在音频质量维度这一优势甚至达到81.7%,提示词遵循偏好为80.6%,IP一致性偏好为59.4%。
即使放在人像短视频这一竞争最激烈的赛道中,与主流视频模型相比,JoyAI-Echo依然获得了更高的视觉美学用户偏好(58.8% vs 26.5%)。
JoyAI-Echo的发布,同样标志着京东在长视频生成领域进入“全球第一梯队”:
过去几年,AI视频生成发展迅速,但长视频始终停留在演示效果惊艳、真正投入生产却困难重重的尴尬位置。角色变脸、声音漂移、生成速度过慢、修改成本极高——这些问题决定了大多数长视频作品更像是技术Demo,而非生产工具。
而JoyAI-Echo试图解决的,核心正是这些长期困扰行业的关键瓶颈。与许多闭源模型不同,JoyAI-Echo选择了“开源”。这意味着长视频生成不再只是少数头部公司的专属能力,而开始成为一个能够被开发者、创作者和研究者共同验证、调用和迭代的开放工具。

△AI生成
技术框架提供了起点,开放则让更多可能性慢慢长出来。当一致性、高分辨率、Agent等能力被开源持续验证和优化后,行业内长视频生成的技术迭代速度可能进一步加快。
无论是虚拟IP故事、数字人内容、品牌营销视频,还是教育课件、知识讲解、游戏动画和互动剧情,高一致性、可控、可迭代的长视频生产都能够成为可能。如果说过去的大模型解决的是“能不能生成视频”的问题,那么JoyAI-Echo正在尝试回答另一个更重要的问题:AI能不能真正参与长视频的内容生产创作?从目前的结果来看,答案已经越来越接近肯定。
当稳定记忆、实时交互、可控修改和高效生成开始同时出现时,AI长视频正在从技术展示走向生产工具。一个更稳定、更可控的AI长视频时代,正在被推到台前。
GitHub地址:
项目主页: