当前,人工智能技术正经历从“对话交互”向“自主执行”的关键范式转移。业界普遍关注大模型在长上下文理解与复杂任务规划上的表现,这不仅是算法能力的延伸,更是生产力工具形态的根本性变革。在此背景下,开源模型领域的最新进展尤为引人瞩目,标志着 AI 代理(Agent)能力迈上了新的台阶。
耗时八小时,构建完整操作系统环境
技术前沿 发自 研发一线
深度科技观察 | 聚焦 AI 变革
CUDA Kernel 优化这一硬核领域,近期迎来了人工智能技术的实质性突破。
最新测试数据显示,赋予 AI 模型约十四小时的处理窗口,它能够将 CUDA Kernel 的性能加速比从 2.6 倍显著提升至 35.7 倍。
这一进展意味着什么?
在过去,资深 CUDA 工程师往往需要耗费数月时间,经历反复的测试、调优甚至推翻重来才能达成此类优化;而如今,AI 模型能够在无人值守的情况下自主完成这一过程。
更值得关注的是,AI 在此过程中展现出了类似人类专家的技术直觉。
比如在优化初始阶段,模型尝试在现有高层框架内寻求解决方案,但通过自主运行测试发现性能遭遇瓶颈后,它迅速做出了符合专家逻辑的决策——
主动放弃高层框架束缚,转向底层 C++ 进行重构式开发。
在这漫长的 14 个小时里,该 AI 系统实现了真正的全自动化闭环:自主识别瓶颈、自主切换技术栈、自主编译代码、自主验证结果。
那么,具备如此能力的究竟是何方神圣?
答案揭晓,这正是来自智谱最新推出的开源模型——GLM-5.1。

伴随此次长程任务(Long Horizon Task)能力的显著增强,官方也同步宣布了一项关键里程碑:
开源模型首次在综合能力上与全球顶尖闭源模型 Claude Opus 4.6 实现全面对齐!
这标志着该模型已稳居全球最强开源模型之列。
此外,多项权威评测数据也进一步佐证了这一结论。
在被誉为“软件工程能力试金石”的SWE-bench Pro基准测试中,GLM-5.1 刷新了全球纪录,力压 Claude Opus 4.6、GPT-5.4 等头部模型,位居榜首:
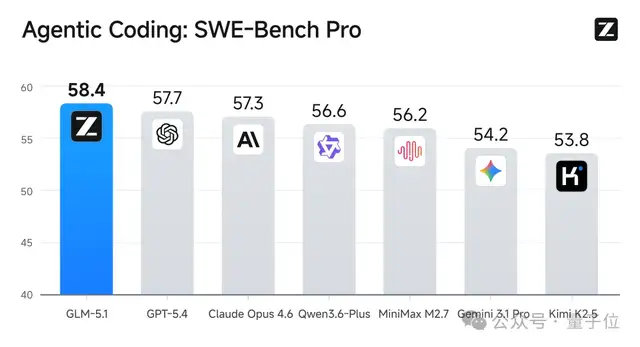
甚至在海外开发者社区中,已出现转向使用开源方案的趋势:
其操作手感与 Opus 高度一致,可用额度是 Claude Code 的 3 倍,而成本仅为对方的 1/3。
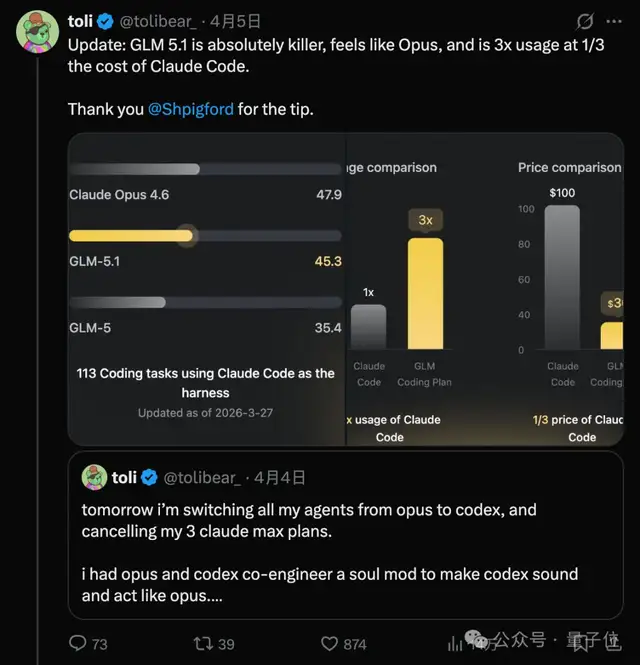
HuggingFace CEO也对此予以确认,指出 SWE-Bench Pro 中性能最强的模型已正式开源:

所有成就的基石,正是智谱针对小时级长程任务能力的专项优化。
目前主流的大模型,大多仍局限于“分钟级交互”的场景。
而 GLM-5.1 的交付粒度发生了本质变化——直接交付完整项目。
下面,我们通过多项实测案例,深入解析 GLM-5.1 的实际工程能力。
调用工具超千轮,优化真实机器学习负载
首个实测环节,延续前述 CUDA 优化场景,对 GLM-5.1 进行压力测试:
基于 KernelBench Level 3 优化基准,该基准包含 50 个真实机器学习计算负载,旨在还原真实工业场景,考核的是端到端的完整优化能力,而非单一算子的调试。
在超过 24 小时的不间断迭代过程中,GLM-5.1 全程自主运行,无需人工干预,反复执行“编译—测试—分析—重写”的闭环流程,最终交付了如下成果——
几何平均加速比达到 3.6 倍,相比之下,torch.compile max-autotune 模式仅能达到 1.49 倍,性能差距超过一倍!
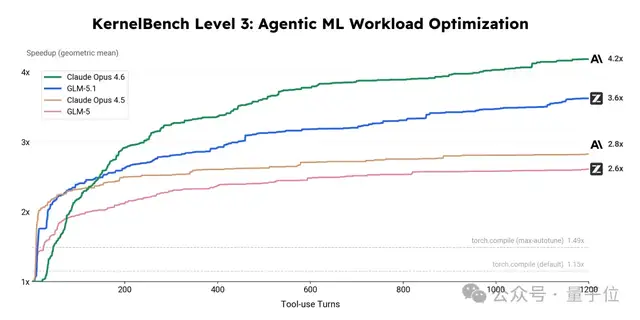
过程分析显示,GLM-5.1 能够自主编写定制化的 Triton Kernel 和 CUDA Kernel,运用 cuBLASLt epilogue 融合技术,并实施 shared memory tiling 与 CUDA Graph 优化。
这些策略覆盖了从高层算子融合到底层微架构调优的全技术栈,每一步均由模型自主决策。
结果再次印证,在 GPU 内核优化这一传统上高度依赖专家经验的领域,AI 模型已展现出从问题分析、方案设计到迭代调优的端到端自主工作能力。
1 小时从零构建 MacOS 桌面环境
在此项实测中,我们向 GLM-5.1 输入了一份 3000 字的产品需求文档(PRD),核心要求明确:
从零开始复刻 MacOS 核心 UI 与交互,不仅需要前端界面,还必须包含窗口管理器、Dock 栏调度、以及模拟的底层文件系统。
这是一个标准前端工程团队至少需要数天才能打磨出原型的任务,但在 GLM-5.1 这里,时间被压缩到了小时级别。
观察其运行过程,任务分析完成后,模型便开始自动编写代码:
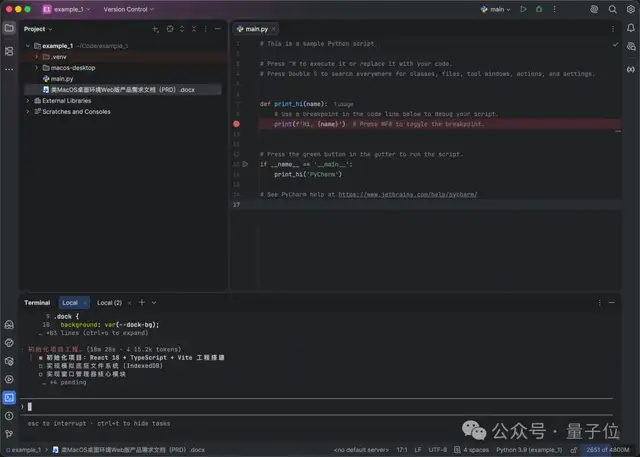
1 个小时之后,在没有任何人工参与的情况下,一个功能完备的 MacOS 桌面环境顺利生成!

视频演示地址:
测试显示,更改桌面背景、窗口缩放、终端命令执行、系统截图等功能,均能正常实现。
而在官方演示中,GLM-5.1 甚至耗时 8 小时实现了更为复杂的 Linux 系统:

视频演示地址:
整个过程执行了 1200 多步,涵盖了完整桌面、窗口管理器、状态栏、应用程序、VPN 管理器、中文字体支持、游戏库等……相当于一个 4 人团队一周的开发工作量。
可以说,现在 GLM-5.1 的每一次代码提交,都代表着系统级的实质演进。
全自动重构遗留代码
开发者皆知,比从零写新项目更痛苦的,是重构他人留下的遗留代码。
现在有了 GLM-5.1,这一棘手任务可交由它处理。
例如下段代码堪称典型:变量名无意义、五层嵌套判断、重复计算总和、全局变量滥用、函数过长未拆分……
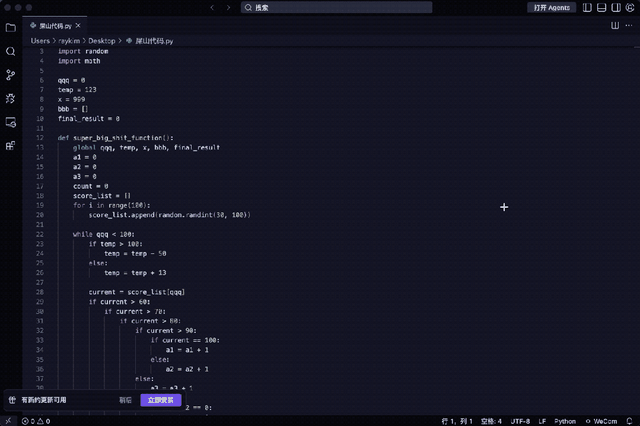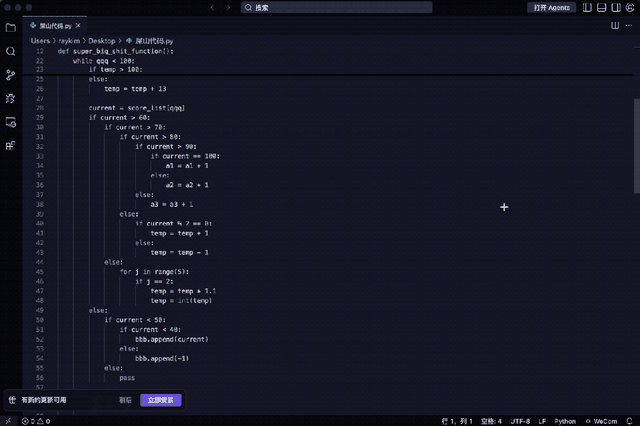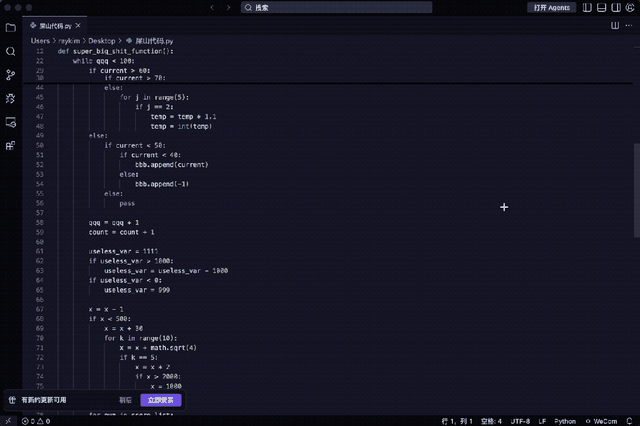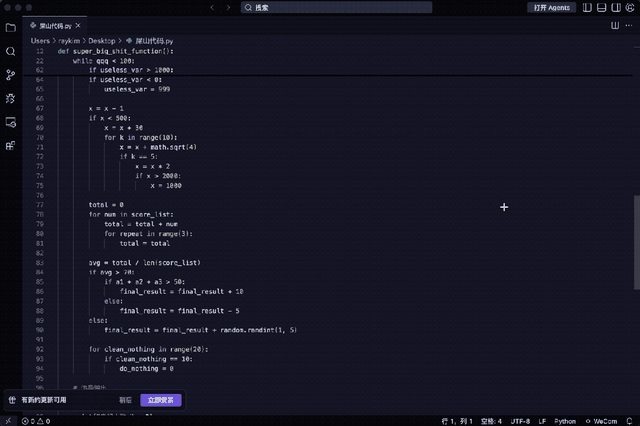
能运行吗?可以;可维护性如何?极差。
而在 GLM-5.1 仅需半小时的自动重写之后,一份注释清晰、符合规范的代码随即生成:
655 次迭代,突破向量数据库性能瓶颈
如果说重构代码是将已有工作做好,那么向量数据库优化,考验的则是AI 自主迭代、持续突破的能力。
这也正是人类资深工程师核心价值所在。
在此项测试中,GLM-5.1 的目标是优化现有向量数据库的查询性能,最大化提升 QPS。
随后,它启动了完全自主的“测试 – 分析 – 优化 – 再测试”闭环。
每一轮优化后,模型都会主动运行完整 Benchmark,获取 QPS、延迟、内存占用等核心数据,自主分析性能瓶颈。
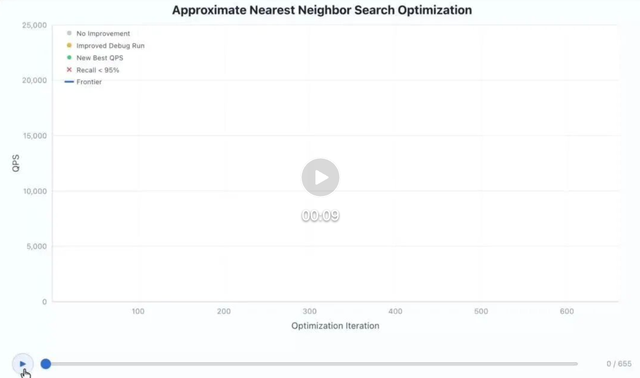
视频演示地址:
最终,历经 655 轮迭代,GLM-5.1 将向量数据库的查询吞吐从初始的 3108 QPS 提升至 21472 QPS,性能达到初始正式版本的 6.9 倍。
GLM-5.1 此次表现之所以惊艳,本质上是因为它抓住了 AI 行业的下一个核心赛点:长程任务(Long Horizon Task)能力。
2025 年 3 月,全球顶尖的 AI 安全研究机构 METR 提出了一个改变行业认知的新指标,即 Task-Completion Time Horizon(任务完成时间线)。
该指标的核心思想在于,不再单纯用做题准确率衡量模型智能,而是用时间来衡量它能独立完成多长时间的人类专家任务。
研究显示,前沿模型的时间线每 7 个月就会翻一倍,这条指数曲线,被权威媒体称为”AI 领域最重要的一张图”。资本界更是在 2026 年初直接宣告:“这就是 AGI 的核心方向”,并直言:2023-2024 年的 AI,是只会对话的”talker”,而 2026-2027 年的 AI,将成为能真正落地做事的”doer”。
而 GLM-5.1,是全球第一个在真实工程任务中,验证了 8 小时持续工作能力的开源模型。
它能在单次任务中,持续、自主地工作长达 8 小时,过程中自主规划、自主执行、自主测试,遇阻时主动切换策略,出错后自行修复,最终交付完整的工程级成果。
GLM-5.1 之所以能做到这一点,核心源于三个维度的系统性技术突破:
第一,更强的长程规划与目标保持能力。
它能把一个复杂的大目标,拆解为可执行的多阶段计划,并且在长达十几小时、上千步的执行链路中,始终围绕最终交付目标推进。简单来说,就是干到第十步,还记得第二步定的规矩。
第二,更稳的自适应纠错与持续执行能力。
它实现了代码编写、工具调用、环境调试、API 对接等多个环节的稳定衔接,中途出错时,不会停下来等人工介入,而是会自主查看错误日志、定位问题根源、修复 bug,甚至自己写回归测试用例验证修复效果。
第三,更好的状态延续与上下文整合能力。
面对长时间跨度、多轮反馈和百万级 token 的上下文信息,它能稳定追踪已完成的工作、当前所处的阶段和下一步的核心动作,持续整合新的信息,保持整个执行链路的一致性。
GLM-5.1 的出现,不仅是模型能力的升级,更改写了全球大模型行业的叙事逻辑。
长久以来,中国开源模型始终带着追赶者的标签,与美国顶尖闭源模型存在差距,而 GLM-5.1 彻底打破这一局面:
它在权威榜单上对齐 Claude Opus 4.6,在 SWE-bench Pro 等核心工程指标上实现反超,让中国开源 AI 在核心工程能力上与全球前沿并驾齐驱。
更重要的是,它的变革远超模型本身,正重构万亿级 IT 服务市场的底层逻辑。
AI Coding 的进化有清晰路径:从程序员提效工具,到降低代码门槛,再到能自主做事的初级工程师,而 GLM-5.1 的 Long Horizon 能力,直接将 AI 推向能持续工作数小时、交付完整项目的新阶段。
当 AI 的交付单位从一行代码变为一个完整项目,便冲击了整个软件工程的生产关系——4 人团队一周的工作量、资深工程师数月的优化任务,它数小时就能完成,这将重构多个行业的定价与人力配置逻辑。
当然,我们不必陷入 AI 会替代程序员的无谓焦虑。就像当年计算机的普及,没有淘汰会计这个职业,只是淘汰了不会用计算机的会计;AI 的到来,也不会淘汰开发者,只会淘汰不会驾驭 AI 的开发者。
GLM-5.1 的出现,真正给整个行业抛出的核心问题是:当 AI 已经能自主完成长达数小时的复杂长程任务,实现从规划、执行、纠错到完整项目交付的全闭环时,人类的不可替代性到底在哪里?
答案或许就是定义问题、创造价值、做出核心决策的能力,毕竟这是 AI 暂时无法替代的核心护城河。
而对中国 AI 行业而言,GLM-5.1 只是开始,当开源模型达到全球顶尖工程能力、AI 从对话者变为执行者,行业必将迎来更彻底、更深刻的变革。
纵观此次技术突破,其意义不仅在于单项指标的刷新,更在于验证了开源生态在通用人工智能路径上的可行性。对于开发者而言,这预示着编程工作的重心将从代码编写转向架构设计与需求定义。虽然自动化程度的提升引发了关于职业替代的讨论,但历史经验表明,工具能力的增强往往伴随着新岗位的产生。关键在于人类如何重新定位自身在智能协作链条中的核心价值。






