在智能体(Agent)技术飞速演进的当下,图形用户界面(GUI)智能体被视为打通数字世界“最后一公里”的关键。然而,长期困扰学术与工业界的难题在于:训练环境仿真度不足、评测标准缺乏统一、真机部署成本高企。这三个环节的割裂,导致许多模型在论文中表现优异,却难以在真实设备中落地。
近期,来自浙江大学真实智能实验室(ZJU-REAL)的团队开源了ClawGUI框架,试图通过构建一条从在线强化学习训练、标准化评测到真机部署的完整流水线,来解决这一结构性痛点。这不仅是一个工具集的更新,更是对 GUI Agent 工程化路径的一次系统性探索。
没有人工干预,没有预设脚本
ClawGUI 团队 投稿
看着它一步步把方块消掉,莫名有种解压感。
这不是游戏外挂,而是一个通用 GUI 智能体在「认真工作」:它用的是和操作手机 App、填写表单、浏览网页完全相同的视觉理解与操控能力。能玩消消乐,只是因为它真的学会了「看懂屏幕并操作」这件事。
当前 GUI 智能体研究普遍面临一个结构性挑战:训练、评测、部署三个环节彼此割裂,难以形成闭环。模型在仿真环境里训练完成后,往往缺乏配套的工程路径迁移到真实设备;评测体系标准不一,不同框架下的数字难以横向比较;而部署到真实设备,又需要独立搭建一套工程基础设施。三个环节各自为战,整体推进的成本极高。
今天,来自ZJU-REAL的团队带来了ClawGUI,一个覆盖 GUI 智能体在线 RL 训练、标准化评测、真机部署完整生命周期的开源框架。不是三个独立工具的简单拼接,而是一条打通的流水线:用 ClawGUI-RL 训练,用 ClawGUI-Eval 评测,用 OpenClaw-GUI 部署,端到端验证。
基于这套流水线,一个仅 2B 参数的小模型 ClawGUI-2B,在 MobileWorld 基准上取得17.1 SR,大幅超越基线的11.1,达到了接近 8B 模型的水平。
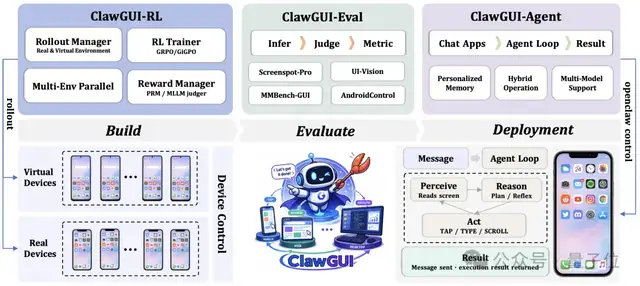
△ClawGUI 系统架构总览
GUI Agent 的 RL 训练需要与真实设备进行持续交互,截屏、解析、操作、获得反馈,形成完整的 episode。这意味着训练基础设施不仅需要模型训练框架,还需要大规模环境仿真和设备管理能力。ClawGUI-RL 是目前开源社区中为数不多的、经过端到端验证的 GUI Agent Online RL 解决方案。
具体来说,ClawGUI-RL 将整个训练基础设施拆解为三层:环境管理、奖励设计、策略优化。
环境层面,所有设备后端(Docker 虚拟机和物理手机)被统一抽象为同一套接口,训练代码无需区分底层是模拟器还是真机。每个环境遵循「重置→执行→评估→回收」的标准生命周期,配合 Spare Server 轮转和周期性重启,保证长时间训练的稳定性。
奖励层面,ClawGUI-RL 采用二元结果奖励+PRM 逐步奖励的双层设计。结果奖励在 episode 结束时给出成功/失败的 0/1 信号,PRM 则在每一步操作后根据前后截图和历史动作判断当前操作是否有效推进了任务,两者相加构成最终奖励。这种稠密的逐步反馈极大缓解了 GUI 长序列决策中奖励稀疏的问题,让优化器能够区分哪些中间步骤是有价值的、哪些是无效绕路。
策略优化层面,ClawGUI-RL 支持 GRPO、GiGPO 等主流强化学习算法,并提供统一的训练接口,方便研究者根据任务特性灵活切换和对比不同优化策略。
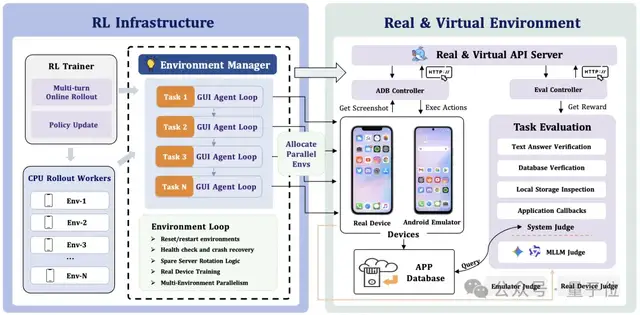
△ClawGUI-RL 架构图
基于 Docker 的 Android 虚拟环境,ClawGUI-RL 支持大量虚拟 Android 环境同时并行运行。内置的 Spare Server 轮转机制保证了训练的鲁棒性,当某个容器截图失败或设备不健康时,系统自动切换至备用服务器,训练不中断。团队提供了经过验证的端到端真机 RL 训练流程,物理手机和云手机均可接入。真机训练的交互协议与虚拟环境完全一致,为后续大规模云手机训练铺平了道路。
标准 GRPO 为整个 Episode 分配一个单一的优势分数,成功了就是 1,失败了就是 0,中间步骤好不好完全不管。这就像考试只看总分,不知道哪道题做对了哪道做错了。ClawGUI-RL 通过引入过程奖励模型(PRM)改变了这一点,对每一步操作进行评估,提供更密集的梯度信号,实现更精细的策略优化。
以 MAI-UI-2B 为基座,ClawGUI-2B 在 MobileWorld 基准上的表现:
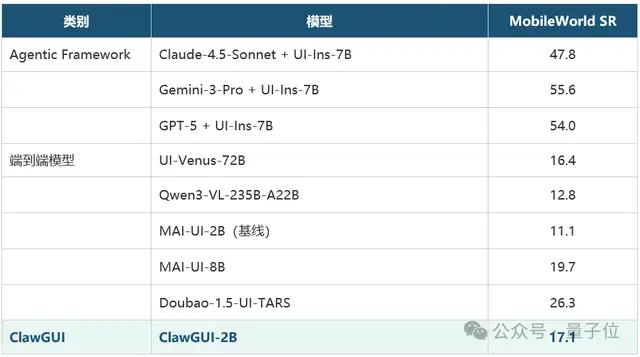
几个关键数字:ClawGUI-2B 达到17.1 SR,大幅超越 MAI-UI-2B 基线(11.1),提升幅度达6%。一个 2B 小模型,达到了接近 8B 模型的水平。
GUI 模型评测领域长期面临复现一致性的挑战:不同框架、不同实现细节下,同一模型的评测数字往往存在明显差异。差个 prompt 格式、搞混坐标系、调错分辨率,结果就可能偏差数个百分点。
ClawGUI-Eval 通过标准化的Infer→Judge→Metric三阶段流水线系统性地解决了这个问题。
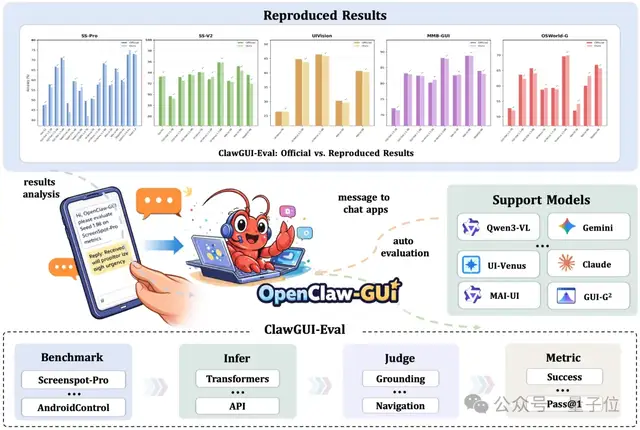
△ClawGUI-Eval 评测框架
覆盖 6 大 Benchmark(ScreenSpot-Pro、ScreenSpot-V2、UIVision、MMBench-GUI、OSWorld-G、AndroidControl),支持 11+ 模型(Qwen3-VL、Qwen2.5-VL、UI-TARS、MAI-UI、GUI-G2、UI-Venus、Gemini、Seed 1.8 等)。48 个有官方基准的格子中成功复现 46 个,总体复现率 95.8%。前沿模型 Gemini 3.0 Pro 和 Seed 1.8 在 ScreenSpot-Pro 上实现 100% 复现,并首次评测了 Gemini 3.1 Pro(85.01)。
比数字更有价值的,是团队总结的关键复现经验,每一条都是用准确率换来的教训:
1. 坐标系统不匹配=准确率归零。Qwen2.5-VL 输出绝对像素坐标,Qwen3-VL 输出 [0,1000] 归一化,StepGUI 用 [0,999],搞混一个就是灾难。
2. 图文输入顺序(tv vs. vt)可导致数个百分点差异。大部分模型需要图片在前(vt),MAI-UI 需要文本在前(tv),用错直接崩盘。
3. 哪怕一句”You are a helpful assistant.”也能带来约 1% 的提升。System prompt 必须严格对齐官方。
4. Prompt 格式必须逐字对齐。措辞微小差异就可能影响结果。
5. 温度建议设为 0.0。非零温度影响坐标精度。
所有推理结果已全部开源,欢迎下载验证。
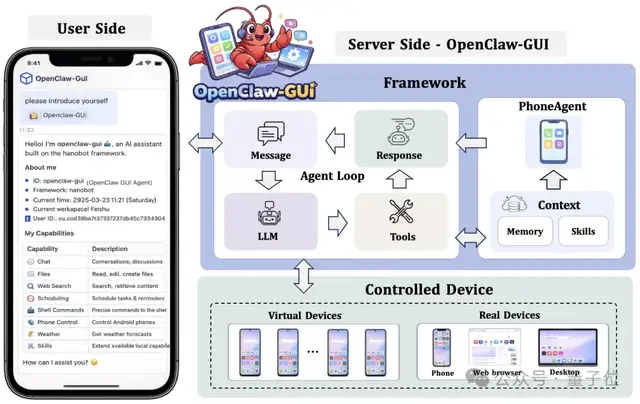
GUI 智能体真正的价值,在于能够在用户手边的真实设备上运行、帮人完成实际任务。OpenClaw-GUI 正是为此而生,把 GUI 智能体带到真机上落地。
更关键的是,OpenClaw-GUI 把评测也集成进来了。说一句「帮我测一下 qwen3vl 在 screenspot-pro 上的指标」,Agent 会自动完成环境检测→多 GPU 推理→判分→指标计算→结果对比。这本身就是 CLI+GUI 协作的绝佳例证,计算密集型工作由 CLI 高效完成,人机交互和结果呈现依赖 GUI。
核心能力:跨平台支持 Android(ADB)、鸿蒙(HDC)、iOS(XCTest);多模型接入 AutoGLM、MAI-UI、GUI-Owl、Qwen-VL、UI-TARS;个性化记忆,自动学习用户偏好,跨任务持续复用;Episode 记录,每次执行以结构化 Episode 保存,支持回放与数据集构建;Web UI 基于 Gradio,支持设备管理、任务执行与记忆查看。
2026 年,CLI Agent 无疑是最火的赛道。Claude Code、Gemini CLI、CodeBuddy……一个自然的问题浮现:GUI 智能体还有必要吗?
研究团队倾向于认为:GUI 的故事远没有结束,CLI+GUI 的融合或许是通往通用 Agent 的一条重要路径。
人类短期内离不开 GUI。从文字到图片到视频,越容易被感知的媒介越具备传播优势。外卖、打车、社交、购物,移动互联网绝大多数的交互发生在图形界面上。至少在可见的未来,GUI 仍将是数字世界的主要入口。
不是所有 App 都有 API。微信、银行、大量企业内部系统只有图形界面。CLI 面向 Agent 执行,高效干活;GUI 面向人类理解,感知和交互。两者更像是互补关系而非替代关系。
GUI 的「可见性」提供了一种独特的信任机制。假如 Agent 在执行任务时涉及支付操作,CLI 以用户看不见的方式直接完成了付款,造成的损失谁来承担?GUI 操作到关键步骤时,用户可以看到屏幕上正在发生什么、随时介入。这种可控性可能是纯 CLI 方案较难提供的。
Online RL 的工程挑战远未被解决。GUI Agent 的 RL 训练需要与真实 App 交互,登录验证、反爬机制、动态 UI 变化,大规模 RL Scaling 的稳定性仍是行业难题。ClawGUI-RL 的 Spare Server 轮转和周期性重启机制是一个初步的探索,距离大规模生产级训练还有很长的路要走。
ClawGUI 的规划不止于此:OpenClaw-GUI 支持自然语言手机操控与评测;ClawGUI-RL 可扩展的 Mobile Online RL 训练基础设施,支持 PRM 逐步奖励;ClawGUI-Eval 标准化评测套件,6 个 Benchmark,95%+ 复现率;ClawGUI-2B 达到 17.1 SR(基线 11.1);后续将推进真机部署 OpenClaw-GUI,直接部署在手机上避免云端隐私泄露;Desktop / Web Online RL,将在线 RL 扩展至桌面和网页环境;以及基于 OPD 算法的实时强化学习。
ClawGUI 不是要证明 GUI 比 CLI 更好,而是想探索一种可能性:训练、评测、部署打通之后,GUI 智能体能走多远?CLI 和 GUI 的协作又能释放出怎样的潜力?
ClawGUI-RL 让 GUI Agent 的在线训练从虚拟环境走向真机,ClawGUI-Eval 为社区提供了一套可信赖的评测标准,OpenClaw-GUI 把 GUI 智能体从研究带到了真实设备。
项目已开源,欢迎 Star 支持,让更多人看到 GUI Agent 的可能性。
项目地址:
https://github.com/ZJU-REAL/ClawGUI
项目主页:
从行业视角来看,ClawGUI 的出现标志着 GUI Agent 研究正在从“单点突破”转向“系统工程”。过去,许多研究过于关注模型架构的创新,而忽视了数据闭环和部署环境的复杂性。浙江大学团队通过开源整套流水线,降低了后续研究者的门槛,这将有助于加速该领域的技术迭代。
然而,也必须客观认识到,尽管复现率达到了 95.8%,但在面对千变万化的真实应用场景时,智能体的鲁棒性仍需时间检验。特别是涉及隐私敏感操作和复杂动态界面时,如何平衡自动化效率与用户控制权,将是未来产品化过程中必须直面的伦理与安全考题。ClawGUI 迈出了坚实的一步,但通用智能体的终极形态,仍需产业界与学术界共同摸索。






