生成式人工智能的发展速度,往往超出公众的预期阈值。当文本生成已经能够媲美人类作家时,视觉领域的突破则成为了下一个争夺高地。近期,一系列关于多模态模型能力的演示在技术社区引发了广泛讨论,尤其是图像中文字渲染的准确性与场景的真实感,标志着 AI 生图技术可能正在跨越某个关键的奇点。
这不仅仅是一次版本的迭代,更可能是视觉信息生成逻辑的根本性转变。以下是对最新技术进展的详细观察与分析。
这将是一个虚拟与现实,彻底融合的世界
假如你看到马斯克出现在抖音直播间,手里拿着老干妈,背后整墙都是他心爱的大火箭模型,你会作何感想?

直播间在线人数瞬间突破 10 万,评论区里特斯拉车主纷纷刷屏支持。甚至,连预计年末发布的《GTA-6》也传来了梦幻联动的消息——马总现身罪恶都市,SpaceX 办公楼被植入游戏场景。

更有甚者,连奥特曼也同框现身。如果这一切看起来如此真实,以至于你准备点击链接或转发分享,那么需要立刻止损了。

全!是!假!的!!!
并没有抖音直播,没有弹幕,也没有游戏截图。这些以假乱真的画面,全部出自 OpenAI 最新的生图模型 GPT Image 2。
这一进展意味着,「有图为证」的时代可能正在终结。AI 技术的发展已经不可避免地迈入了一个新的阶段。

Image 2 最令人震撼的特性在于其隐蔽性。面对生成的图片,用户往往不会第一时间产生「这是 AI 画」的警觉。普遍情况下,你第一眼根本看不出来这些图是 AI 生成的。
这种体验带来了一种迟来的「Aha-moment」。当你后知后觉得知真相,再回过头仔细端详,试图寻找蛛丝马迹时,会迎来第二个惊讶时刻——根本找不到瑕疵。
以一张时尚海报为例。从人像质感、配饰细节、背景光影,到文字排版,非专业人士完全无法识别异常。它与报刊亭里售卖的杂志封面几乎没有区别。

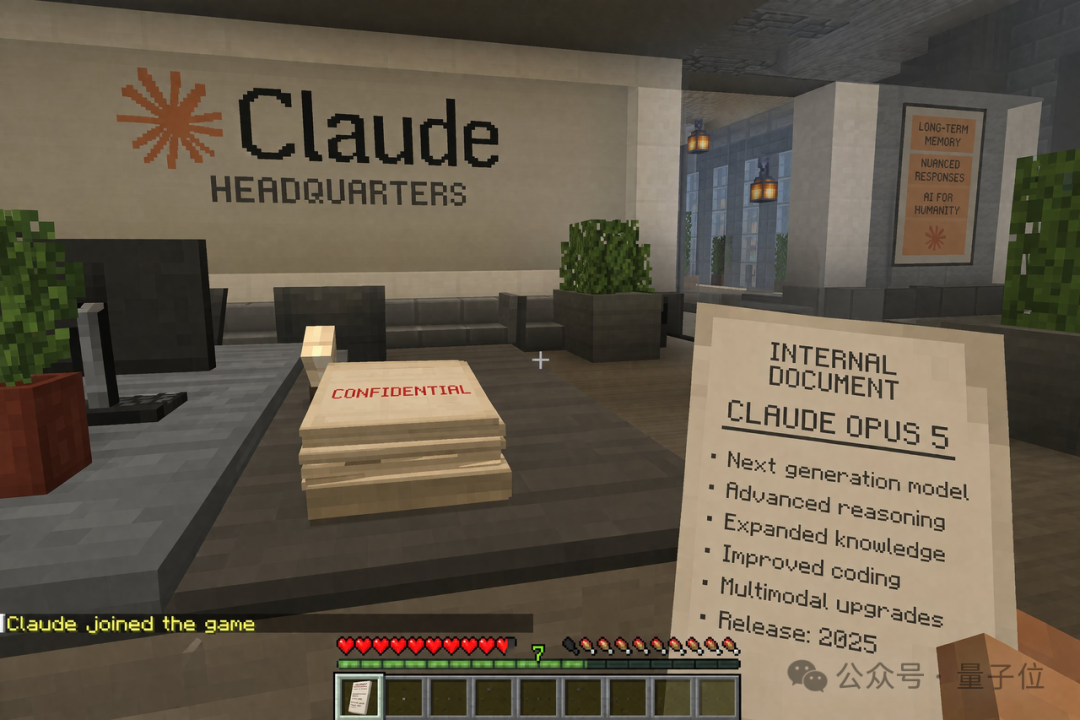
在游戏场景还原上,资产形态与《我的世界》完全一致,血条、饥饿值、经验值等状态栏完美还原。甚至连手中握着的「机密文档」,上面的文字也是正确且有逻辑的。
文字渲染能力的提升是此次升级的核心看点之一。以下是纯文字生成的案例。
这是一份用 Image 2 生成的韩文日记。构图自然,金属线圈装订的光泽感真实。经翻译确认,内容并非乱码,而是一份逻辑通顺的韩国高中生日记,记录了周日补习后与朋友喝咖啡的日常。

再看更高密度的信息场景,例如汉语字典。信息密度极大,且无乱码现象,直接作为出版社源文件使用也毫无违和感。

这是一项极具实用价值的技能。在设计场景中,文字是除视觉之外最重要的信息模态。与纯视觉资产不同,这类应用贴近实际生产,需要展示产品信息、活动详情等具体内容。
因此,Image 2 在文字上的升级,对于可用性而言是至关重要的。制作游戏海报、电商海报的门槛被大幅降低,即便是非专业人士也能轻松上手。

甚至可以实现多重元素的融合。
纯商品图的生成更是轻而易举,质感直出,这可能会让传统设计行业感到压力。

对于个体而言,这意味着副业门槛的消失,AI 生成的上架素材可以直接与全球顶尖品牌对齐。

对于 OpenAI 而言,Image 2 的出现或许承载着更具野心的用途——前端设计。
熟悉 Codex 的用户都知道,过往 GPT 的 UI 设计能力常常备受诟病,往往生成一堆风格突兀的卡片,需要人工二次调整。但这次,OpenAI 似乎找到了一种不同的解法。
不再单纯依赖创造力路线,而是将模仿能力发挥到极致。
以下是网友利用该能力生成的官网界面预览。
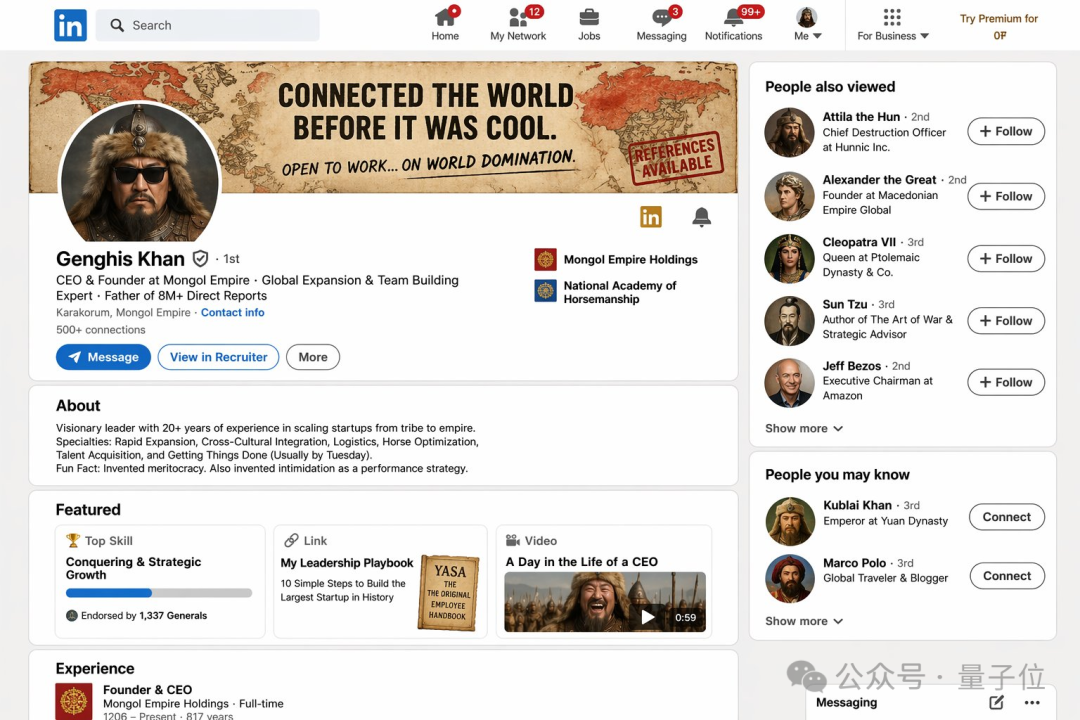
以及领英界面。
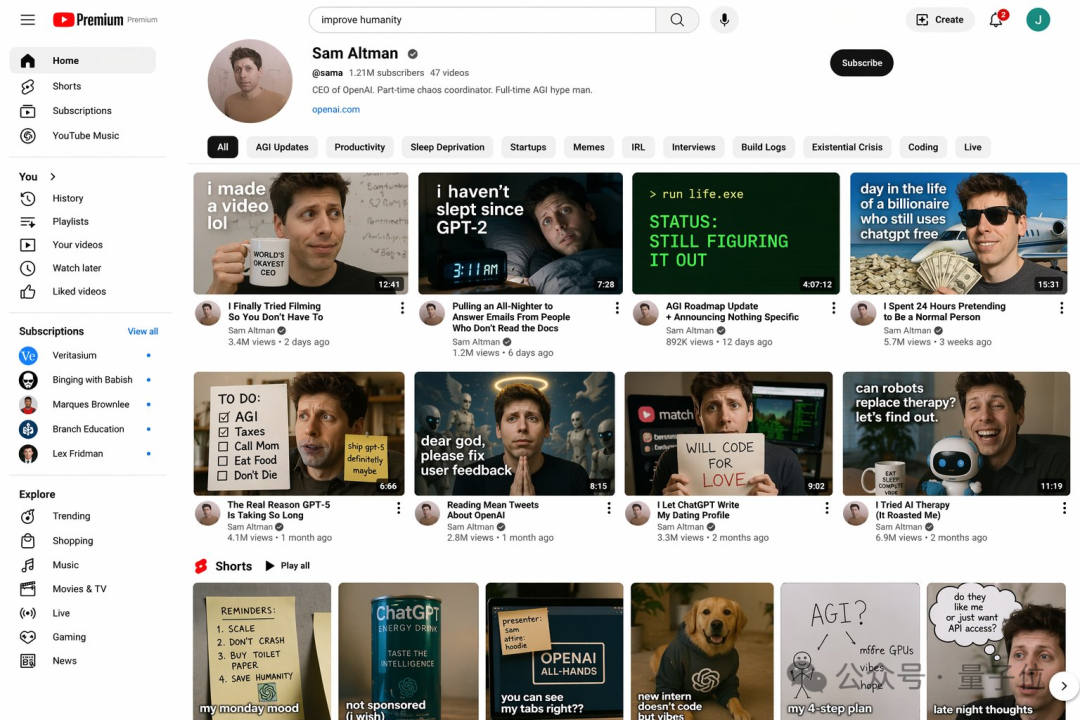
甚至是平行宇宙中的科技博主主页。
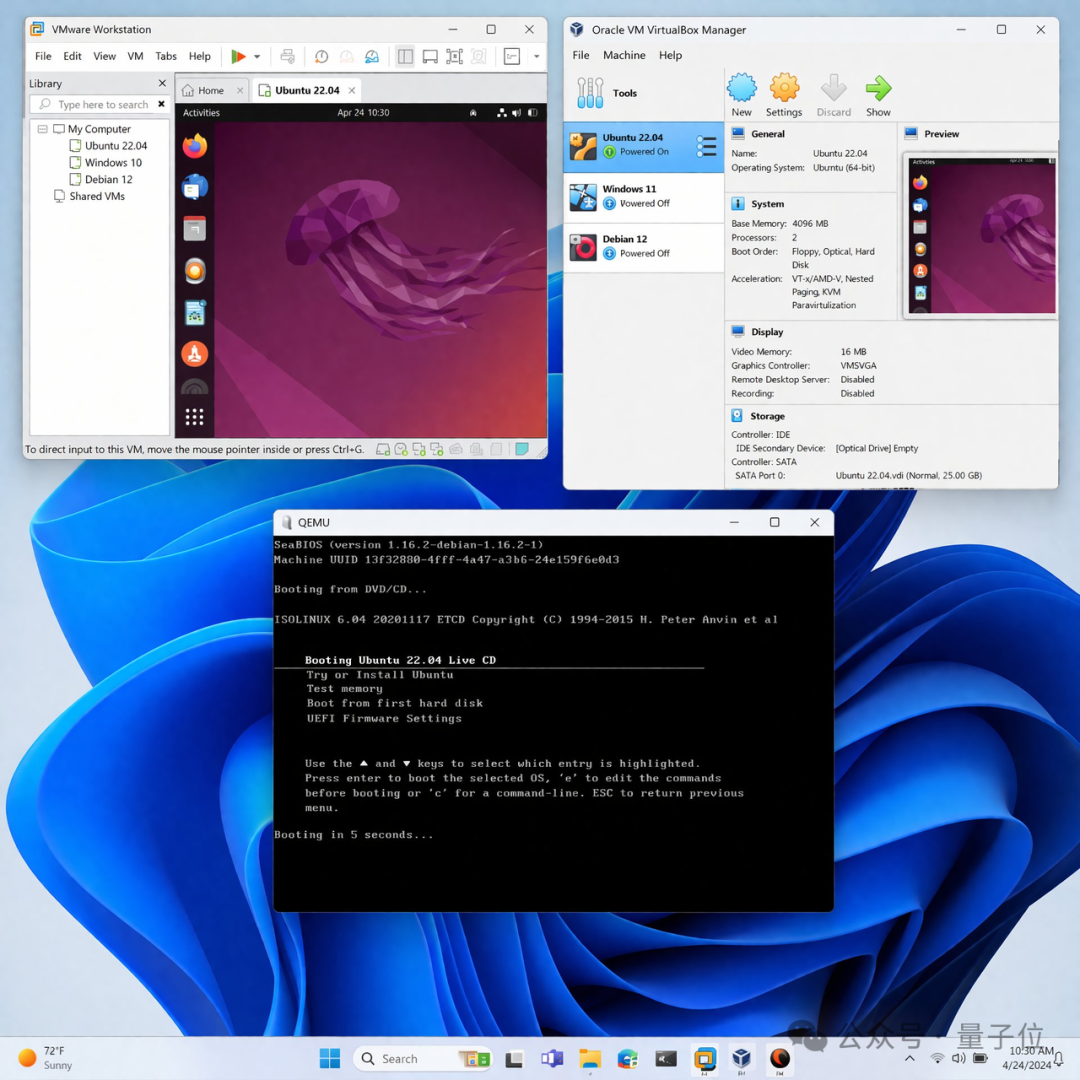
还有一张Windows 桌面,其真实程度让人第一眼误以为是截图。
这项能力如果与编程组合在一起,潜力巨大。此前就有消息称,OpenAI 正在构建一个整合 ChatGPT、Codex、Atlas 的超级 APP。
如今看来,Codex 正在成为这个想法的雏形。前几天,OpenAI 将浏览器内置,使得 vibe-coding 更加直观。
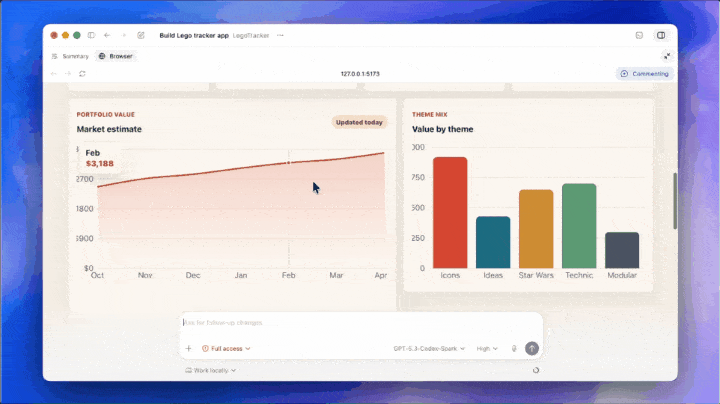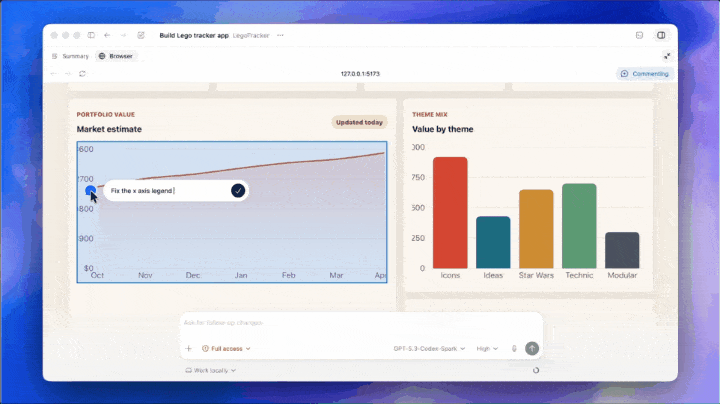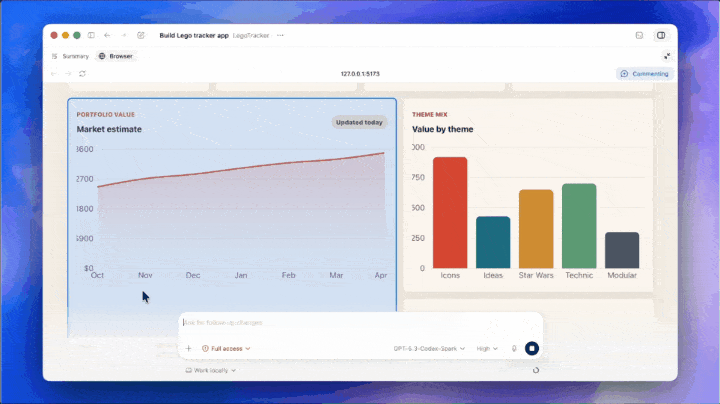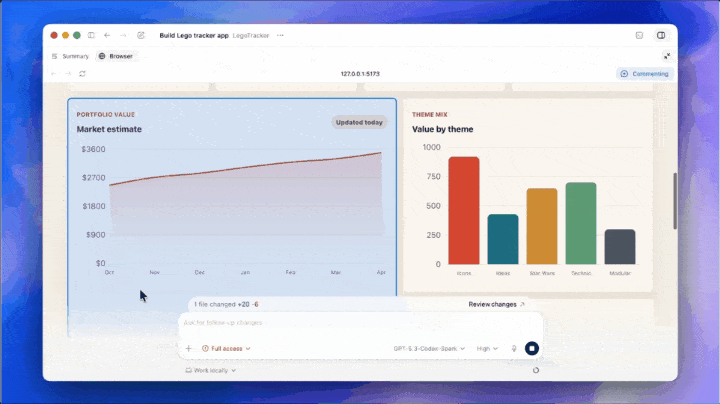
更关键的是,图像生成能力已接入 Codex。
简单来说,这类似于 Google Stitch 与 Claude Code 的结合。Codex 将 UI 设计做成了端到端流程,无需在其他地方生成参考图片再导出。
无需提前准备素材,想要什么界面直接在 Codex 生成,交互逻辑一键适配。有了图像生成能力的把关,GPT 的 UI 能力有了质的保障。
如此强大的 UI 模仿能力,无疑能让 Codex 的前端开发体验大幅升级。虽然 Sora 视频模型进展缓慢,但多模态这条路对 OpenAI 依然具有核心价值,Codex 可能会在 UI 设计领域,将编程和图像生成垂直整合。
不过,目前该模型并未向所有会员开放。尝试复现类似效果时,可能会发现效果存在差异。

如果想体验,目前可以通过 LM Arena 等平台尝试。
其实,这类高精度生图模型已经引发了一段时间的关注。但奇怪的是,很少有人察觉到这件事背后意味着什么,大部分反应仅停留在:
噢,好厉害的生图模型。
确实提升巨大,也足够让人兴奋。但问题在于,这次好像有点跨过界限了。
细想一下,AI 生图已经以假乱真到 99% 的人都看不出来了,这难道不让人毛骨悚然吗?
对于视觉行业专业人士来说,这些图片或许仍有破绽,但对于普通大众,现在 AI 生图的程度,已经能完全骗过肉眼。
电信诈骗、视频谣言……这些网络安全问题,或许比技术本身更和我们日常生活息息相关。
AI 生图的图灵测试,正在悄然无息地通过奇点。我们可能再也回不到,那个还能拿着放大镜像抓贼一样抓 AI,「AI 味」人人喊打的时代了。
从行业发展的宏观视角来看,这种技术能力的跃迁是一把双刃剑。一方面,它极大地释放了创意生产力,让内容制作的边际成本趋近于零,中小企业甚至个人开发者都能获得以往只有大型团队才具备的视觉表达能力。这对于互联网生态的繁荣无疑是一剂强心针。
但另一方面,信任机制的重构迫在眉睫。当视觉证据不再可靠,数字水印、区块链确权以及来源验证技术将成为基础设施的一部分。未来的互联网,可能不再默认「所见即所得」,而是需要「所见即所证」。对于用户而言,提升数字素养,保持对信息的批判性思维,将成为在这个虚拟与现实彻底融合的世界中生存的必备技能。