在大模型推理成本日益成为行业焦点的当下,算力资源的调度效率直接决定了服务的经济性与可用性。长期以来,Prefill(预填充)与 Decode(解码)阶段的耦合部署,以及 KV Cache 传输对高性能网络的依赖,构成了制约大规模推理集群扩展的关键瓶颈。
尤其是随着上下文窗口的不断扩展,显存带宽与网络带宽的压力呈指数级上升。如何打破机房物理边界,实现跨地域的算力协同,不仅是工程挑战,更是架构演进的必然方向。以下这项来自月之暗面与清华大学的最新研究成果,或许为异构算力调度提供了新的解题思路。
研究团队:月之暗面 & 清华大学计算机系
核心成果:PrFaaS 跨数据中心推理架构
在大模型长上下文推理领域,月之暗面再次取得关键技术突破。这一次,他们将矛头指向了困扰行业的推理架构跨机房调度难题。
研究团队提出了一套全新范式:Prefill-as-a-Service(简称 PrFaaS),即预填充即服务。
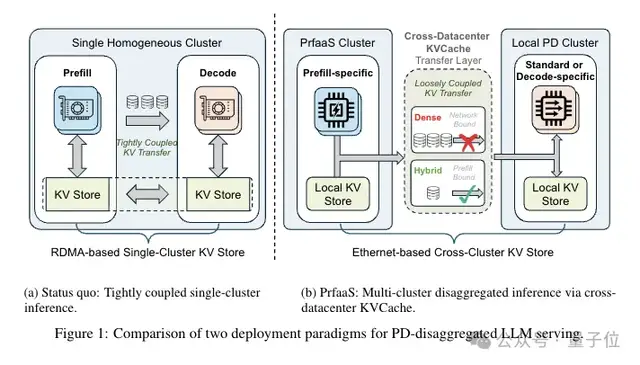
该架构的核心突破在于实现了 KV Cache 的跨数据中心传输,成功将 Prefill 和 Decode 阶段彻底解耦,并部署到不同的异构集群中。
引入 PrFaaS 后,Prefill 和 Decode 之间的调度不再受物理机房限制,可以跨越城市甚至地域。
尤为重要的是,在面对长文本场景时,上下文长度越长,该架构的性能优势越显著。
可以说,这是专为长上下文场景打造的底层架构优化。
这项工作由月之暗面和清华大学郑纬民院士、武永卫教授团队联合推出。
在内部 1T 参数混合注意力模型的实测验证下,这套 PrFaaS-PD 架构交出了极具说服力的数据。
相比传统同构 PD 部署,吞吐量提升 54%,P90 延迟大幅降低 64%;即便对比未做智能调度的朴素异构方案,吞吐量依然提升 32%。
而跨数据中心传输仅占用 13Gbps 带宽,远低于 100Gbps 的以太网上限,也就是说普通商用以太网即可稳定承载。
这背后是怎么做到的?
Prefill-Decode 分离是大模型推理服务的行业标配。
但这让KV Cache 传输高度依赖 RDMA 网络,牢牢地把 Prefill 和 Decode 两个阶段强行绑定在单一集群内。
解绑单飞不了,压根儿解绑单飞不了。
于是,如果最适合做 Prefill 的算力芯片和最适合做 Decode 的带宽芯片不在一个机房,是异地恋的状态,就根本没办法一起用。
但强行把异构硬件塞到一起,必然导致资源配比完全僵死。
大家都知道流量是波动的。配比如果定死,很容易出现一边忙到飞起,一边闲成狗的情况出现,算力利用率大打折扣。
导致这个情况的“病灶”,就是就是KV Cache 的带宽墙。
研究团队在这项工作中给出了量化数据。
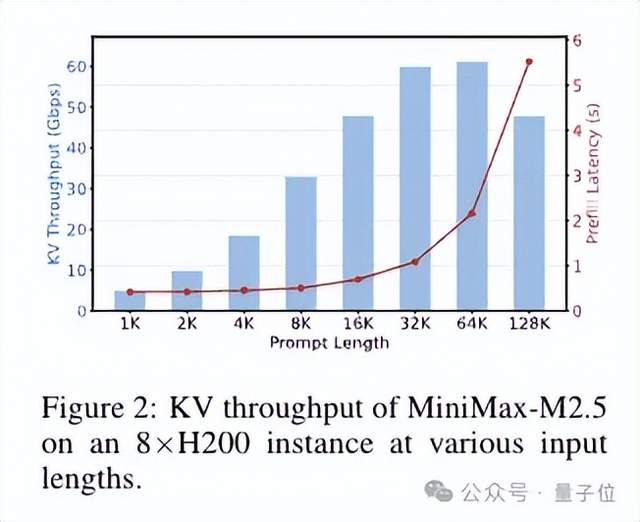
以 MiniMax-M2.5 这款典型的 dense GQA 架构模型为例——
在 32K 上下文时,单实例产生 KV Cache 的速率达到 60Gbps,而跨数据中心以太网带宽通常只有 10-100Gbps,相当于后者试图用家用小水管来扛消防水带的流量,根本带不动。
因此,为了保证推理不被卡住、不出现等待延迟,Prefill 与 Decode 之间必须使用高带宽、低时延的 RDMA 网络进行通信。
这就是传统 PD 分离架构只能被限制在 RDMA 域内的根本原因。
不过,新一代混合注意力架构带来了转机。
近期,Kimi Linear、Qwen 3.5、MiMo-V2-Flash、Ring-2.5 等模型齐刷刷用上 了线性注意力 + 全注意力混合架构。
在这种混合架构下,线性层只产出固定大小的循环状态,不随上下文变长而膨胀;只有全注意力层才会生成和长度相关的 KV Cache。
它带来了喜人的效果。在 32K 上下文下:
- MiMo-V2-Flash 的 KV 吞吐量仅 4.66Gbps,比起 MiniMax-M2.5 来降了 13 倍;
- Qwen3.5-397B 的 8.25Gbps 相比同规 dense 模型的 33.35Gbps,降低 4 倍;
- Ring-2.5-1T 的 MLA 压缩叠加 7:1 混合比例,整体 KV 内存节省约 36 倍。
“线性注意力 + 全注意力”混合架构把 KV 吞吐量从 RDMA 级别降到了以太网级别。
跨数据中心做 PD 分离,终于从不可能变成了可能。
光有模型架构还不够,想真正落地跨数据中心推理,还需要一套能把“有可能”变成“能用”的系统架构。
针对这一点,清华联合月之暗面团队推出了PrFaas。
PrFaaS 即 Prefill-as-a-Service,翻译过来叫预填充即服务。
它是一种跨数据中心的大模型推理服务架构,核心是将长上下文请求的 Prefill 计算,选择性卸载到独立的、算力密集型的专用集群完成,再把生成的 KV Cache 通过普通以太网传输到本地 PD 集群执行 Decode。
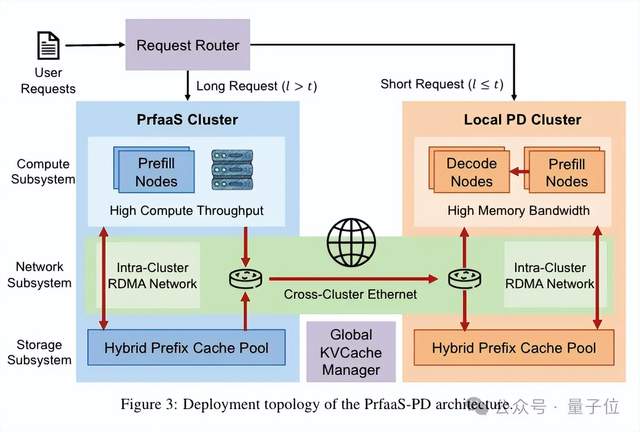
具体来说,系统会设一个动态长度阈值 t。
如果是短请求(未缓存长度≤t),就老老实实留在本地 PD 集群跑完整个流程。
只有长请求(未缓存长度 > t)才会被送到专门的 PrFaaS 集群做 Prefill,生成的 KV Cache 再通过以太网传回本地做 Decode。
值得注意的是,阈值 t 会跟着实时带宽、请求长度分布自动调整。

整套架构由三大子系统紧密配合。
第一,计算层。
PrFaaS 集群上,H200 这类高端芯片,只啃长上下文 Prefill 硬骨头;而本地 PD 集群去用 H20 这类带宽优化芯片,专心做 Decode、处理短请求。
术业有专攻,两类硬件各自独立扩容,不再强行配对。
第二,网络层。
集群内部用 RDMA 保证低延迟,跨数据中心就用 VPC 或专线,走通用以太网传 KV Cache,以此大幅降低部署难度和成本。
研究人员表示实测环境是 100Gbps VPC。这虽然远低于 RDMA 的 800Gbps,但足够用了。
第三,存储层,这也是最有意思的子系统。
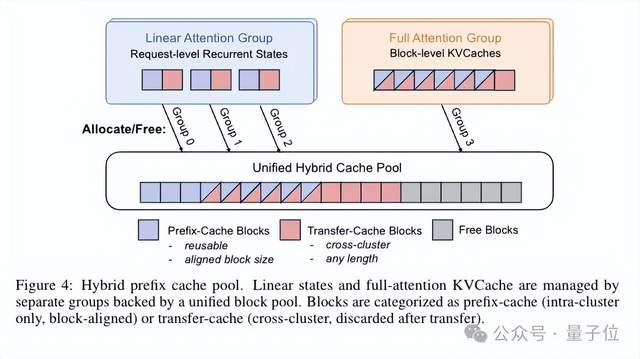
团队设计了一个混合前缀缓存池,把 KV Cache 分成两类。
一类是 prefix-cache 块,另一类是 transfer-cache 块。
prefix-cache 块在集群内复用,必须块对齐才能命中;transfer-cache 块则专门用于跨集群传输,传完即弃,不占用长期存储。
为什么这样设计?
因为混合模型的 KV Cache 是 heterogeneous 的。
线性层的 recurrent state 是 request-level,大小固定,必须完全匹配才能复用;全注意力层的 KV Cache 是 block-level,支持部分前缀匹配。
而统一池化管理,既能高效复用本地缓存,又能灵活支持跨集群传输。
此外,为了稳住生产环境,PrFaaS 还设计了双时间尺度调度算法。
简单理解一下,就是短期毫秒级做带宽 + 缓存感知路由,长期分钟级做流量驱动的资源重分配。
短期调度监控 PrFaaS 出口利用率,接近阈值时提高 t、减少跨中心流量。
对于带前缀缓存的请求,调度器会权衡缓存命中位置和带宽可用性。如果带宽紧张,优先用本地缓存;如果带宽充裕,可以从远程集群拉缓存来减少重复计算。
长期调度观察各阶段的队列深度和利用率。
当 Prefill 成为瓶颈时,把 PD 集群的节点从 Decode 角色转为 Prefill 角色;当 Decode 成为瓶颈时,反向调整。
这种动态重分配让系统能适应流量模式的缓慢变化。
为了验证跨数据中心 KV Cache 传输与 PrFaaS 架构的真实落地能力,研究团队基于生产级配置开展了严格的对照实验,完整还原了异构硬件、跨域网络与真实长上下文流量的组合场景,让方案从架构设想变为可量化、可复用的工程实践。
实验选用团队内部自研的 1T 参数混合注意力架构模型,整体设计对齐 Kimi Linear 架构,采用线性注意力层与全注意力层 7:1 的混合配比。
此外,在保持模型能力的同时实现 KV Cache 的高效压缩,为跨数据中心传输奠定基础。

硬件层面,团队采用了典型异构组合。
专门负责长上下文 Prefill 的 PrFaaS 集群配备 32 张 H200,凭借更强算力吞吐处理高负载计算;本地 PD 集群配备 64 张 H20 GPU,面向 Decode 阶段优化内存带宽,兼顾短请求 Prefill 与全流程推理。
网络层面,团队采用跨数据中心通用方案,通过 VPC 对等连接提供约 100Gbps 的跨集群带宽,完全贴合主流云厂商与多数据中心部署环境。
实验 workload 采用截断对数正态分布的请求长度,均值约 27K tokens,高度贴近线上长上下文服务的真实流量特征。

实验结果证明了 PrFaaS-PD 架构的工程有效性。
在核心性能指标上,相比同等硬件规模的同构 PD 集群,PrFaaS-PD 架构将服务吞吐量提升 54%;相比未做智能调度的简单异构部署,吞吐量仍有 32% 的提升。
在端到端延迟上,PrFaaS-PD 架构带来的优化效果更为显著,P90 TTFT(首词时延)降低幅度达 64%,长请求不再与短请求争抢本地 Prefill 资源,排队阻塞与计算拥堵问题大幅缓解。
更关键的是工程可行性指标。
PrFaaS 集群的平均出口带宽仅 13Gbps,在 100Gbps 的跨集群链路中占比仅 13%,留有充足的带宽冗余,完全不会出现拥塞与链路抢占。
实验结果证实,在混合模型与 PrFaaS 调度的协同下,KV Cache 传输可以不再依赖 RDMA,普通商用以太网即可稳定支撑。
这项研究由月之暗面与清华大学联合完成。
作者包括 Ruoyu Qin、Weiran He、Yaoyu Wang、Zheming Li、Xinran Xu、Yongwei Wu、Weimin Zheng、Mingxing Zhang(通讯作者)。

其中,研究团队成员中来自月之暗面的,有 Ruoyu Qin、Weiran He、Yaoyu Wang、Zheming Li、Xinran Xu 五位。
一作Ruoyu Qin(秦若愚),是清华大学计算机科学与技术系 MADSys 实验室在读博士生,师从本文通讯作者、清华大学计算机系副教授 Mingxing Zhang(章明星),后者长期面向 KV Cache 架构与分布式推理。
同时,Qin 也在月之暗面工作,还是 Mooncake 分布式推理系统的一作。

月之暗面工程副总裁Xinran Xu(许欣然)也在作者名单之列。
观察发现,作者名单中月之暗面的五位,同样也是 Mooncake 架构的核心贡献者。
除上述的教授章明星外,研究团队中来自清华大学的作者还有 Yongwei Wu 和 Weimin Zheng。
Weimin Zheng(郑纬民),中国工程院院士,清华大学计算机系教授,长期从事并行/分布处理、大规模数据存储系统领域的科研与教学工作。

Yongwei Wu(武永卫)是清华大学计算机科学与技术系副主任、教授、博士生导师,此外还担任 AI Infra 公司趋境科技的首席科学家。
此前,月之暗面与清华大学 MADSys 实验室联合主导研发并开源了 Mooncake 项目,趋境科技是该项目核心共建单位与深度贡献者。
从产业视角来看,PrFaaS 架构的推出标志着大模型推理基础设施正从“堆叠算力”向“精细化调度”转变。通过解耦计算与传输瓶颈,企业能够更灵活地利用不同地域、不同规格的算力资源,显著降低长上下文服务的边际成本。
这一技术路径若能广泛普及,将极大缓解算力稀缺带来的焦虑,使普通商用网络环境下的跨区域推理成为常态。对于追求极致性价比与大规模部署的 AI 应用而言,这种架构演进无疑具有重要的参考价值。






