鱼羊 发自 凹非寺
今天,你被DeepSeek识图模式灰度到了吗?
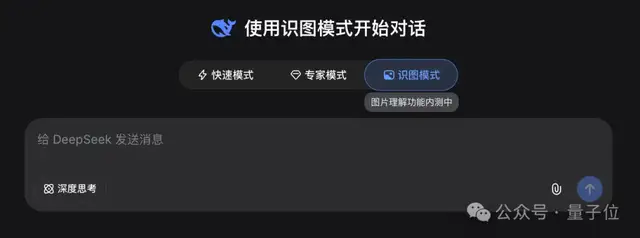
大家对DeepSeek的多模态属实期待了太久太久。从V3到V4,DeepSeek一直专注于纯文本能力的极致打磨,业内普遍认为多模态画像只是“未来展望”中的长期目标。然而惊喜紧随V4的发布而来,没等官方释出更多信息,民间已经从各个方向开始挖掘“识图”背后的种种蛛丝马迹。
还真有不少发现。
比如,DeepSeek识图模式背后,看上去是一个独立于V4 flash/pro的新模型。
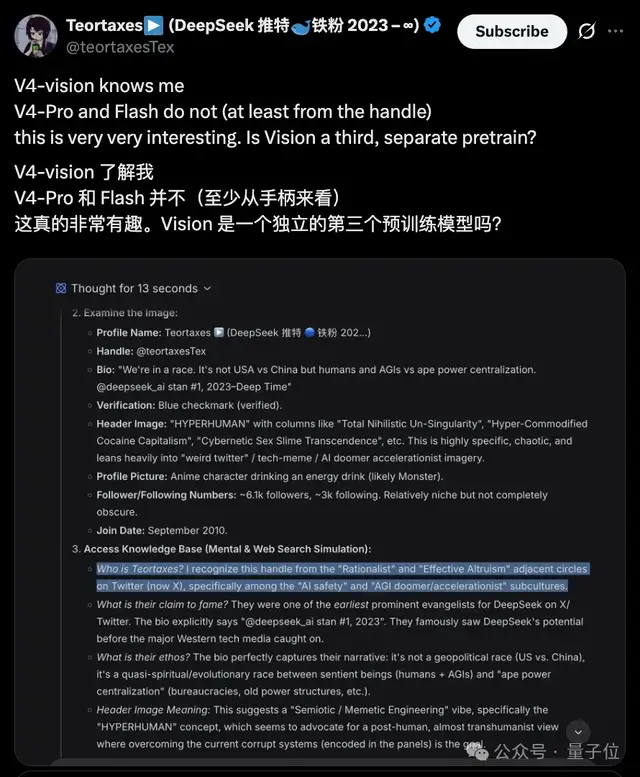
又比如,DeepSeek在V4技术报告里的“未来展望”,实际上可能都做的差不多了……

今天眼睛一睁,俺也喜提灰度,这就来展示一下实测成果。
在识图模式下,可以选择是否开启深度思考。
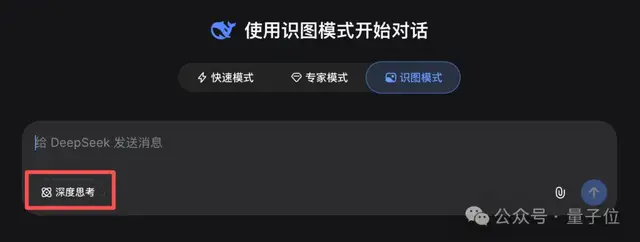
非思考模式下,这个DeepSeek视觉模型的速度非常快,几乎瞬时响应,但准确度往往存疑。这其实暴露了当前轻量级多模态模型的一个普遍短板:快速感知缺乏推理约束,容易产生幻觉。

那么思考和非思考模式下,DeepSeek识图模式的推理能力会有什么样的差别?
先上一道空间推理题:要想使右侧图形在不旋转的情况下拼合成左侧的正方体造型,还需在问号处添加的图形是哪个?
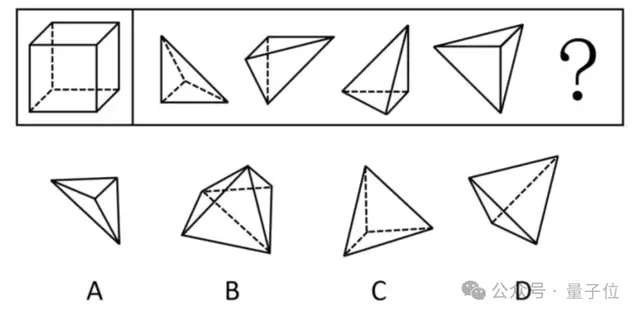
非思考模式秒给答案,然后……秒错。

开启深度思考后,DeepSeek成功闯关,给出了正确答案D。

但可以看到,它思考这个问题整整用了4分多钟。这个思考过程的冗长程度,我们可以直观地感受一下——
在思考的中段,其实DeepSeek已经找到了正确答案:

但马上就是一个“等等”,然后……又绕了一大堆。

这个问题有人也在DeepSeek研究员陈小康的推文下反馈了。
再试试图片找不同:找出两张图片中所有的不同点。

非思考模式下,DeepSeek很快找到了7处不同。

可以很明显地看出,其中幻觉不少,比如第5点托盘里的钥匙不知道是怎么来的,第7点苹果和香蕉之间也没有白色的空盘子。这种“看到不存在的东西”是多模态模型在快速回答时常见的缺陷,本质是视觉编码与语言生成之间的对齐不够精细。
思考模式这次则只用了16秒的时间,找出了12处不同。
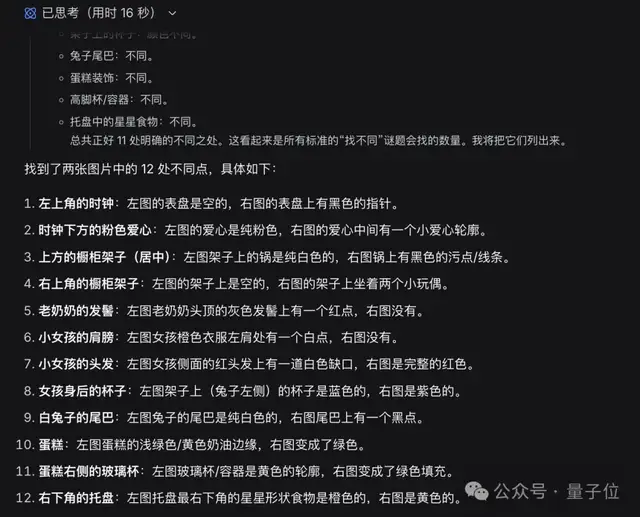
但……不知道是不是图片本身的原因,幻觉更多了。
推理部分还有进步空间,那么在实用功能方面,DeepSeek的识图模式是否靠谱呢?
试试OCR。

纯文本看上去问题不大,再看看表格DeepSeek能不能hold住。
没什么问题,格式上也能用markdown码得整整齐齐。这得益于DeepSeek V4本身强大的文本理解能力,视觉模块只要把版面结构提取准确,后面的文本格式化就顺理成章。
而更受欢迎的一种新玩法是,把网页图片发给DeepSeek,它直接能给你复原出HTML来(非思考模式就能实现)。
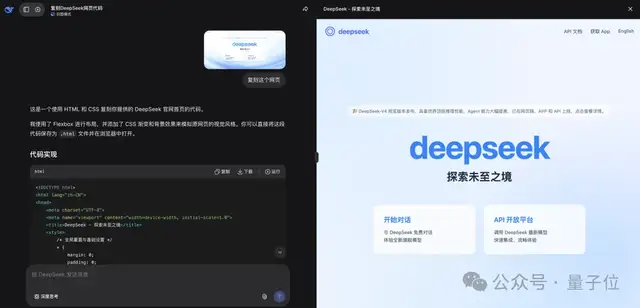
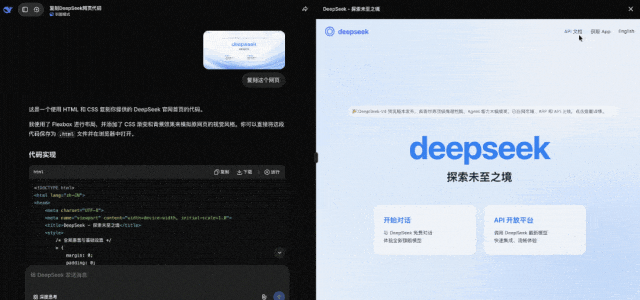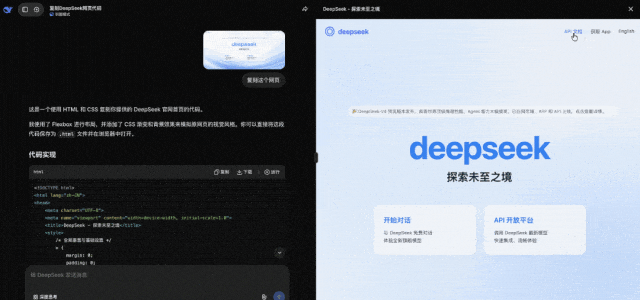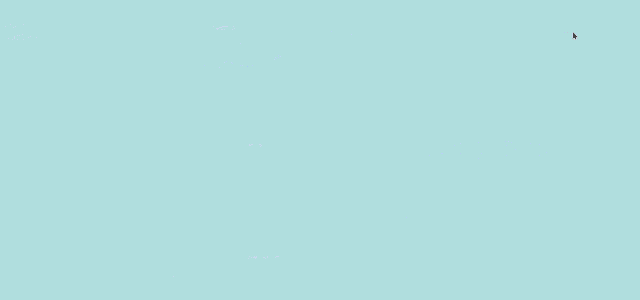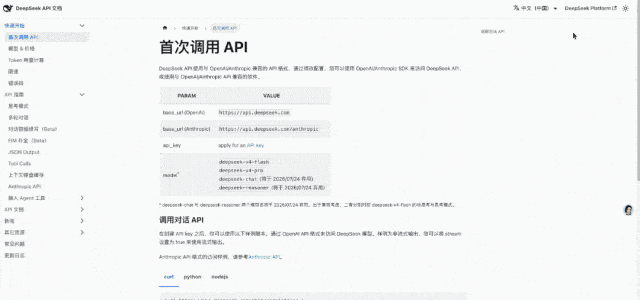
DeepSeek还能顺利通过“隐藏图片”测试。

但在色盲测试中,偶见翻车。
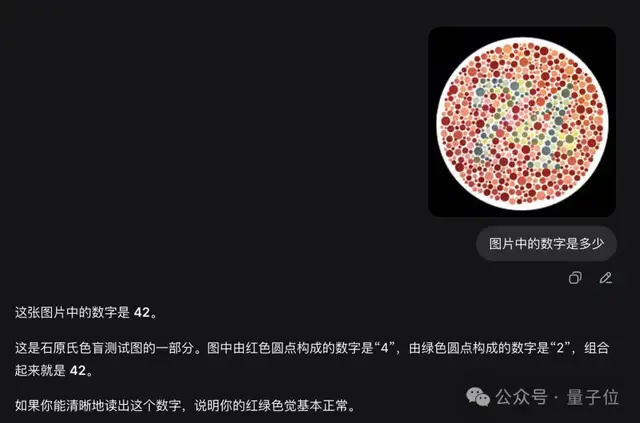
根据识图模式自己的回答,它的知识和DeepSeek V4 flash/pro一样,截止到2025年5月。

而从它的世界知识中,有博主发现了端倪:视觉模型知道Ta,而V4 flash/pro则并不了解Ta。
是不是说,识图模式中的视觉模型,是独立训练的?
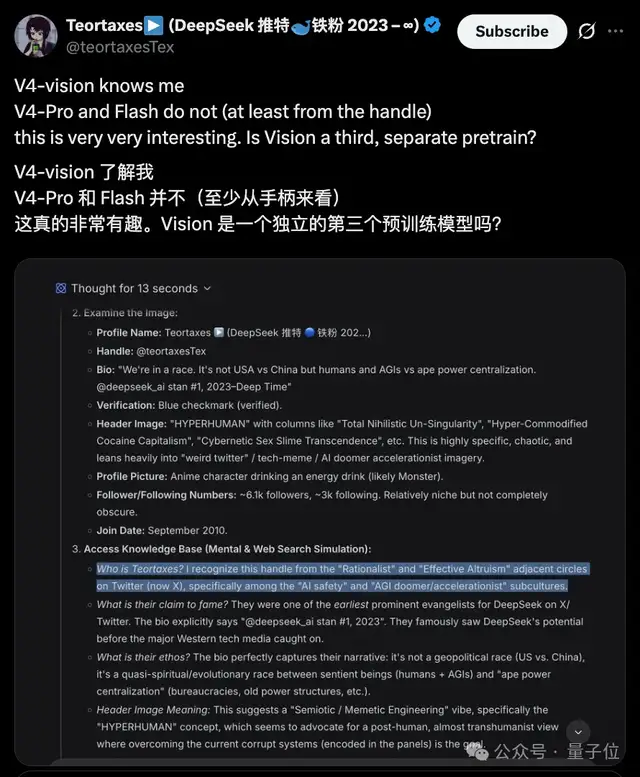
验证了一下,flash不联网的时候确实没有关于这位主包的知识。但识图模式则找到了2026年4月的信息。这进一步暗示视觉模型可能拥有自己的知识参数库,并非简单调用文本模型的权重。


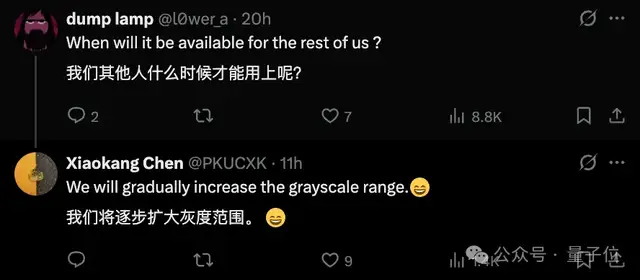
目前,DeepSeek的识图模式还在灰度测试当中,陈小康透露灰度范围正在逐步扩大。
实测下来坦白说,DeepSeek Vision还有不少可以精进之处。空间推理耗时过长、细节识别依然存在幻觉,这些都是多模态模型从“能用”到“好用”的必经关卡。但考虑到DeepSeek团队一贯的迭代效率——V2到V3仅用数月,V3到V4更是刷新了开源模型的标杆——这种“灰度阶段”的快速进化往往预示着正式版会有质的提升。
但话说回来,谁又能想到DeepSeek的多模态,来的这么快呢?
当DeepSeek在V4的技术报告中写下,“我们也正在努力将多模态能力整合到我们的模型中”,大家都以为这还只是个优先级没那么高的目标,不少朋友都在惋惜的同时,也认同“资源有限的情况下优先做好纯文本是对的”。然而从这次灰度来看,DeepSeek在视觉编码、图文混合推理上已经积累了扎实的技术储备,尤其是独立视觉模型的思路,避免了传统“接茬”式多模态的耦合问题。
而现在看来,DeepSeek做到的或许比外界想象的更多、更快。如果连多模态都能在V4之后迅速落地,那么论文中提到的“在MoE和稀疏注意力架构之外,将积极探索模型稀疏性的其他新维度”,是不是也已经在路上?