在红杉AI Ascent 2026的讲台上,英伟达机器人方向负责人Jim Fan用短短20分钟,给整个具身智能行业带来了两场“告别仪式”。这位曾以乐观姿态描绘机器人未来的技术领袖,如今语调中混杂着决绝与期待。VLA范式宣告终结,遥操作技术即将淡出舞台,取而代之的是一套彻底向LLM学习的新框架——世界动作模型WAM以及人类传感器数据。
这一转变的背后,是业界对机器人数据瓶颈的长期焦虑。过去几年,依赖遥操作和VLA模型的路线虽然在实验室中产出不少成果,但其数据采集效率低、泛化能力弱的问题始终存在。Jim Fan提出的新范式,试图用人类第一视角视频和神经模拟器来打破这些限制,其核心逻辑与LLM的“预训练-微调-强化学习”三部曲高度相似。这意味着,机器人领域正在经历一场从“模仿”到“生成”的深刻范式转移。
Jim Fan全新暴论出炉
henry 发自 凹非寺
AI快讯网 |
VLA已死,世界动作模型当立。遥操已死,人类的传感器数据长存。
在今年的红杉AI Ascent 2026上,Jim Fan只用了20分钟,就给机器人行业连开了两场“葬礼”。
第一场,送别过去三年几乎统治具身智能的VLA;第二场,送别所有人以为还能再吃很多年的遥操作。
作为现任英伟达机器人方向负责人,Jim Fan去年还在同一张讲台上讲机器人如何通过测试。今年,他已经开始讨论——
旧范式怎么死,新范式怎么立。
而这一新范式在Jim眼里,很大程度上得靠抄LLM的作业。
预训练模拟下一个世界状态,对应LLM的next token prediction;
动作微调校准对真实机器人有价值的部分,对应supervised finetuning;
最后,由强化学习完成最后一里路。

过去一段时间,英伟达陆续放出EgoScale、DreamDojo、Dream Zero等一系列工作,几乎以一己之力定义了具身智能2026年的走向。
而在这场名叫Robotics: Endgame(机器人联盟,终局之战)的演讲中,则汇聚了Jim Fan关于VLA、世界模型、遥操作、UMI、egocentric、仿真、Scaling Law等机器人领域思考的最新沉淀,十分值得一看。
以下是演讲核心观点摘录:
- VLA已死,WAM将作为新的预训练范式。
- 未来一到两年,遥操占比会降到几乎可以忽略不计。机器人的「主食」会变成第一视角人类视频,整个数据范式转向Sensorized Human Data(人类传感器数据)。
- 人类第一视角视频成功启示了机器人领域的scaling law,英伟达将彻底押注第一视角人类视频。
- 算力=环境=数据。
- 机器人科技树只剩三个成就待解锁,物理图灵测试(2-3年内)、Physical API、Physical Auto Research,2040年有望全部点亮。
几组值得留意的信号:Jim Fan将“算力=环境=数据”提升到战略高度,这实际上暗示了英伟达正在将自身GPU优势转化为机器人领域的主导权——通过提供高算力来生成虚拟环境,再通过环境产出海量训练数据,形成闭环。这不仅是技术路线,更是商业护城河。
以下为演讲全文。
(为方便阅读,做了适当的润色与删减)
2016年的一个夏日,我就在我们现在坐的办公室里。有一个身穿亮皮夹克、手臂粗壮的家伙,举着一个大金属托盘。
他在上面写道:致Elon和OpenAI团队,致计算与人类的未来,我将向你们展示世界上第一台DGX1。
那是我第一次见到黄仁勋。和任何优秀的实习生一样,我迫不及待地排队签上自己的名字。
你能找到吗?我的名字在这里,还有Andrej Karpathy的名字。

那时,我完全不知道自己将要经历什么。而接下来的事情,没人能比Ilya本人描述得更好:
果然,他们对深度学习的信念感染了我们每一个人。
三步函数,六年时间,这就是我们到今天的全部历程。
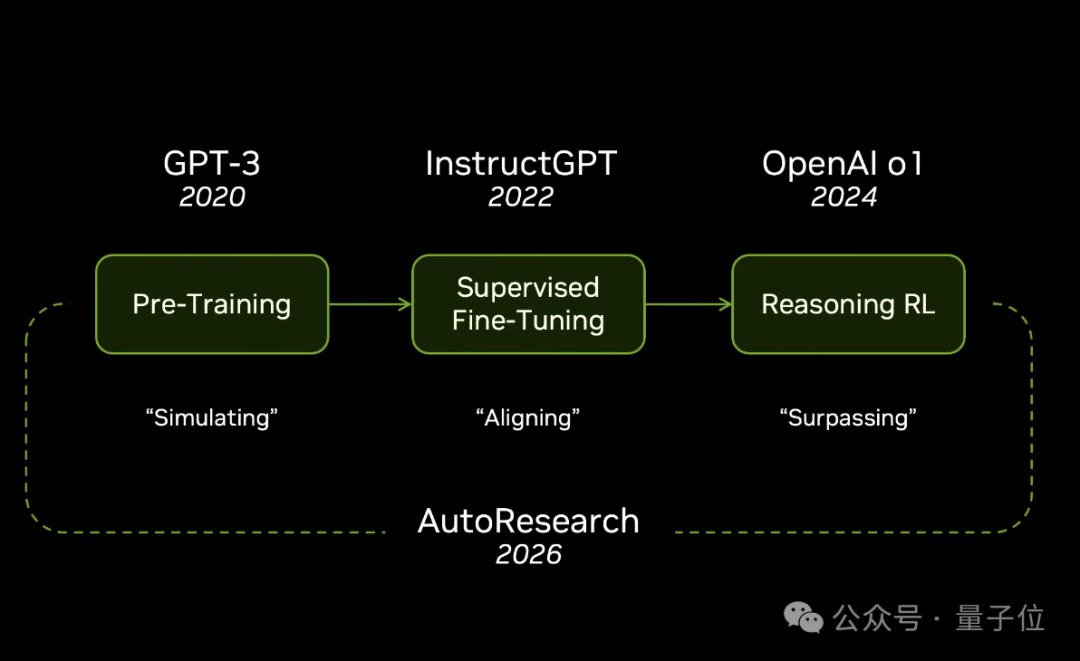
第一步(2020年),GPT-3预训练。预测下一个词元(next token prediction)主要是学习语法规则,理解语言结构,模拟思想、代码和字符串的展开方式。
第二步(2022年),InstructGPT(指令GPT)通过监督微调对模拟进行校准,使其能够执行实际任务,或使用强化学习超越模仿学习。
第三步(2026年),自动化研究(autoresearch)加速整个循环,超越人类能力。
正如Andrej所说,所有付出都在向最终目标冲刺,对于LMS(语言模型系统)来说,他们正处于终局阶段。
老实说,我非常羡慕,看Andrej的笑容就知道他有多开心。
语言模型团队正在享受他们的巅峰时刻,他们正在极速开发AGI(通用人工智能),并将路上的创造称之为“神话(myhtos)”。
那为什么搞机器人的不能也享受这种乐趣呢?
作为自尊心强的科学家,我复制了他们的思路并将它重新命名——“大平行(Great Parallel)”。
我们不再模拟字符串,而是模拟物理世界的下一个状态(next physical world state),然后通过动作微调(action finetuning)校准模拟中对真实机器人有价值的部分,并让强化学习完成最后一里路。
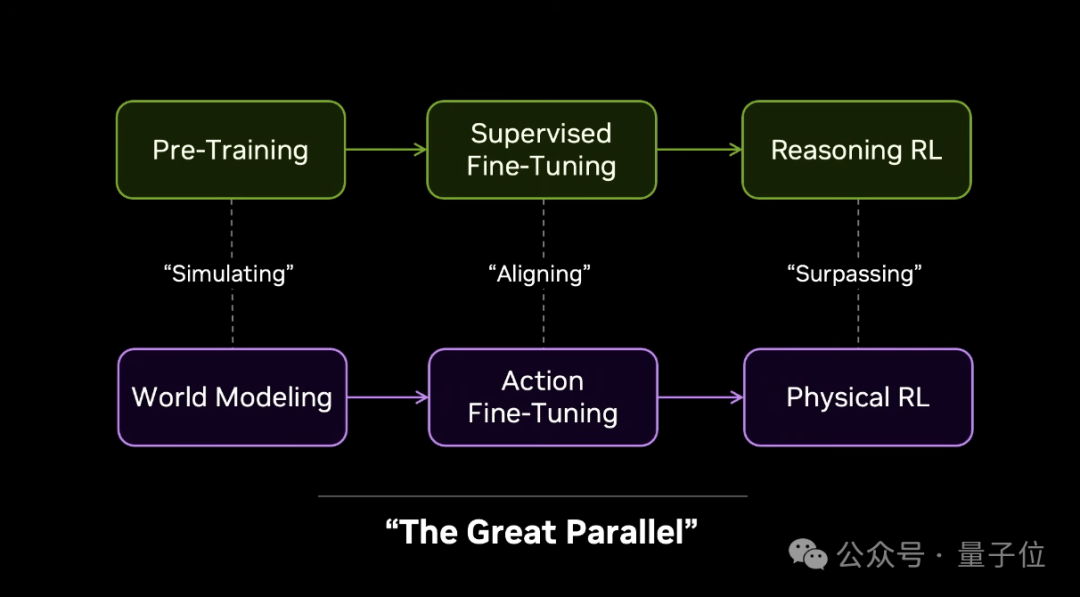
大平行就是复制语言模型的成功策略。打不过他们,就加入。
接下来的章节就到了——机器人联盟:终局之战(Robotics:The End Game)。
抱歉,我忍不住开个小玩笑,香蕉太有趣了,感谢哈萨比斯。

如何玩转终局?归结为两点:模型策略(models trategy)和数据策略(data strategy)。

先看模型策略。过去三年,视觉-语言-动作模型(VisualLanguageActionModels,VLA)占据主导,Pi和Gr00t等模型也属于这一类。
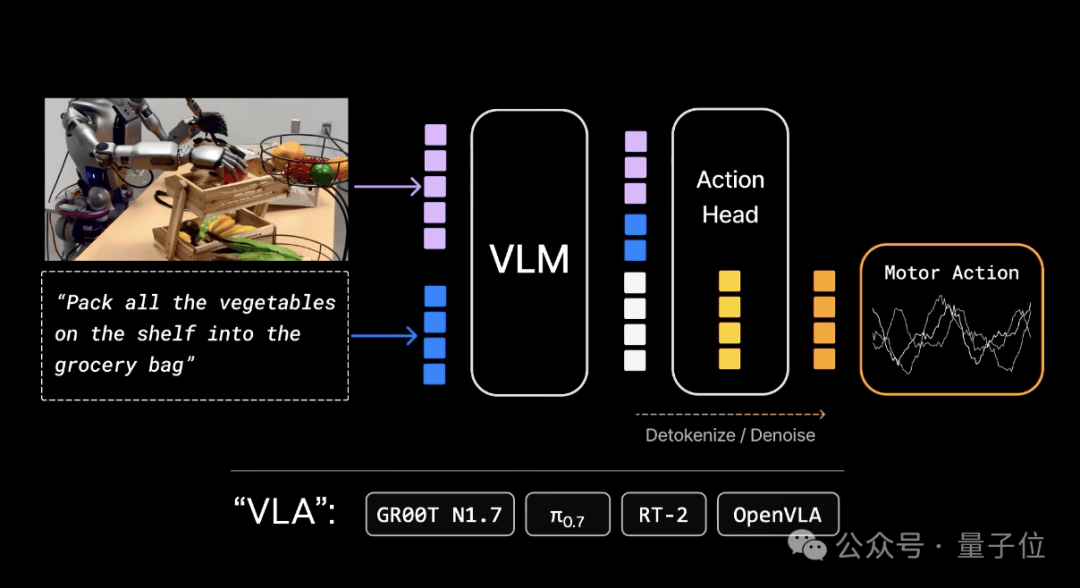
我们假设预训练由VLM(视觉语言模型,Visual Language Model)完成,然后在其上添加动作头(action head)。
但实际上,这些模型都是LVA(语言视觉动作模型,Language Visual Action),大部分参数用于语言,使语言成为核心,其次是视觉和动作。
在VLA里,语言才是一等公民,视觉和动作只能靠边站。
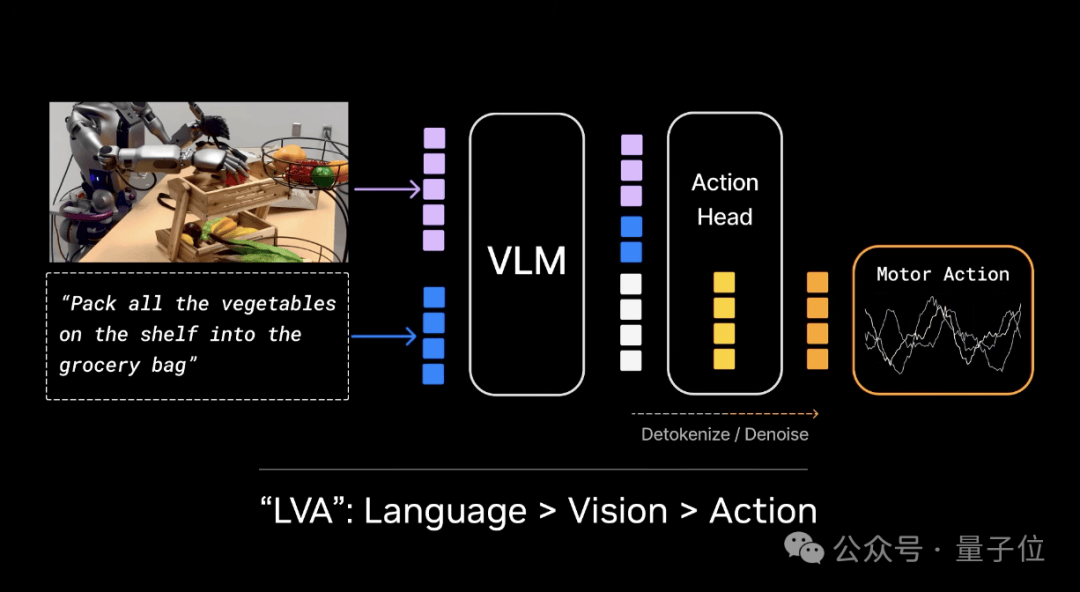
设计上,VLA更擅长编码知识和名词,但在物理和动词方面表现不足,有点「头重脚轻」。
我最喜欢VLA原论文(RT-2)中的例子,把代码移动到泰勒·斯威夫特(TaylorSwift)的图片上。
它从未见过她,却能泛化,但这并不是我们想要的预训练能力。

那么,第二条预训练范式是什么?
我们认为,第二种预训练范式理应应该非常美丽,但不幸的是,它变成了AI视频垃圾(AI Video Slop),比如看猫咪在监控摄像头上弹班卓琴。
这虽然表面上看很娱乐,但没人认真对待它,直到我们意识到这些视频模型实际上在内部学习模拟下一个世界状态。
这是Veo3的一些例子,模型自动学习了重力、浮力、光照、反射、折射等物理规律,没有显式编码,通过大规模预测下一团像素,物理规律自己涌现了,视觉规划也自然出现。

如何让这些世界模型有用?我们通过动作微调,将所有可能的未来状态的叠加(superposition)压缩到对真实机器人有价值的部分。
于是,就有了Dream Zero。

Dream Zero是一种全新的策略模型。它会先“梦”到未来几秒钟里可能发生什么,然后再据此做出动作。
要知道,机器人的运动控制本质上是一组高维、连续的信号。从某种意义上说,它和像素并没有本质区别,都可以被看作连续变化的数据流。
所以,我们可以像渲染视频一样,同时把动作也渲染出来。
Dream Zero能同时解码两个东西,下一刻的世界状态,以及下一步该执行的动作。
也正因为如此,它能够零样本(zero-shot)完成那些训练中从未见过的新任务、新动作。
更有意思的是,当机器人真正开始执行时,我们甚至可以实时“看到”它正在想什么,而且这种相关性非常紧密。
如果视频预测是对的,动作通常就是对的; 如果视频开始幻觉,动作也往往会失败。
所以,也直到这里,视觉和行动才第一次真正坐到了一张桌子上。
我们后来用Dream Zero做了很多有趣的实验,就让机器人在实验室里到处转,然后往prompt输入框里随便打各种指令,看看它会怎么做。
当然,Dream Zero现在还做不到把每个任务都100%稳定完成。
不过,它有点像GPT-2,虽然未必每次都精准,但它几乎总能先把动作的大致“形状”做对。
Dream Zero,是我们迈向机器人“开放式任务”和“开放词汇提示”(open-ended, open-vocabulary prompting)的第一步。
我们把这类全新的模型称为:World Action Models,简称WAM——世界动作模型。
所以此刻,让我们一起为我们的老朋友VLA 默哀片刻。

它们曾经很好地服务过我们。安息吧,VLA。VLA已死,WAM当立。
而要实现WAM,接下来要拼的,就是下一代数据策略。
画面里的这个人,是Bill Dally,正在我们实验室里亲自做遥操作。

考虑到他的薪水,我敢说这大概是我们整个数据集里,成本最高的一条遥操作轨迹。
过去三年,机器人领域几乎被遥操所统治。那简直是遥操的黄金时代。
各种VR头显、为低延迟串流做极致优化的系统、还有那些结构复杂、看起来像中世纪刑具一样的遥操作设备。
整个行业砸了大量资金。也经受了大量痛苦。
但问题是遥操的数据产能从物理上就有上限。理论上,一台机器人一天最多也就24小时的数据。
但说实话,如果现实里每台机器人一天能稳定采到3小时,就已经谢天谢地了。

而且前提还是——机器人之神今天心情不错。因为这些家伙,真的隔三差五就闹脾气(机器人故障)。
那问题来了,我们还能做得更好吗?
有人的答案是直接把机器人的手,戴在你自己的手上。
这套系统叫UMI(Universal Manipulation Interface,通用操作接口)。
它的想法简单得近乎狡猾你把机器人穿在自己手上。你的手怎么动,机器人就怎么动。与此同时,把机器人其余身体部分,统统从数据采集闭环里拿掉。
换句话说,直接用人类的手,去采机器人需要的数据。
在我看来,UMI可能是机器人数据领域最伟大的论文之一。而它最终催生了两家独角兽公司。

左边,是Generalist团队成员把这个设计进一步优化。现在,你可以直接把机械夹爪戴在自己的手上。
右边,则是Sunday做出的三指数据手套。
而去年,我们又往前迈了一步。我们设计出了一套外骨骼(exoskeleton)系统,它和五指灵巧机器人手之间,能够做到1:1映射。
我们把它叫做DexUMI,来看实际效果。

左边,是最传统也最快的数据采集方式,人类直接完成操作,永远是最快的。
右边,是遥操作。你会发现这有多难。画面里这位操作员,是我们团队最熟练的PhD之一。
即便如此,他仍然得极其小心地对齐、校准。整个过程又慢又累。而且,成功率也不高。
中间,就是我们的方案。你只需要戴上这套外骨骼,直接完成动作,数据就同步被采集下来。然后,我们用这些数据训练机器人策略模型。
而你现在看到的,是一个完全自主执行的机器人策略。最关键的是它训练过程中,使用的遥操数据是零。
这意味着,我们第一次打破了那个机器人领域的诅咒,每台机器人每天最多只能采24小时数据。而且你看这些机器人有多开心。因为,它们终于不用再亲自参与数据采集了。
但问题来了,这就是终点吗?我们真的解决了机器人的scaling问题吗?
在场有人开Tesla或Waymo吗?开车的时候,其实你一直都在参与世界上最大的物理数据飞轮。
更妙的是,你甚至感觉不到。尤其是在Tesla FSD工作的时候,数据上传,是一个悄无声息、在后台自动完成的过程。
但戴着UMI这种数据穿戴设备呢?
说实话,还是太麻烦了。它依然是侵入式的。远没有每天开车去上班那样自然。所以,我们需要一个属于机器人的FSD等价物。
我们需要让数据采集,彻底退出前台,融入背景,悄无声息地发生。只有这样,我们才能真正捕捉到,人类灵巧操作最完整的样子。
不只是实验室。而是各行各业,而是所有具备经济价值的劳动场景。
基于此,我们彻底押注在第一视角人类视频(human egocentric videos)。并且给这些视频加入精细的手部位置追踪;高密度语言标注。
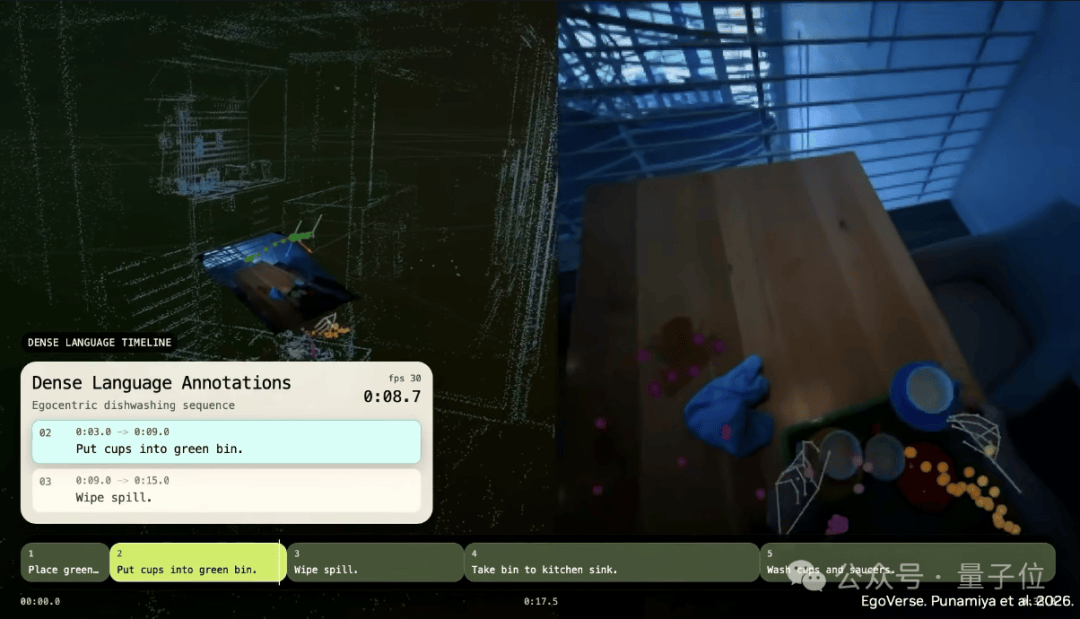
我们把这套训练范式叫做EgoScale。在EgoScale中,99.9%的训练数据,全部来自人类第一视角视频。
最终的结果是一个真正end-to-end的机器人策略模型。它能够直接从摄像头像素输入,映射到拥有22个高自由度的灵巧机器人手。一句话就是,从“看见”,直接到“动手”。
你现在看到的,就是一个完全自主执行的机器人。

在预训练阶段,我们用EgoScale,在2.1万小时的真实世界第一视角人类数据上进行预训练。没有使用任何机器人数据。
在预训练过程中模型学习去预测手部关节位置和手腕姿态。
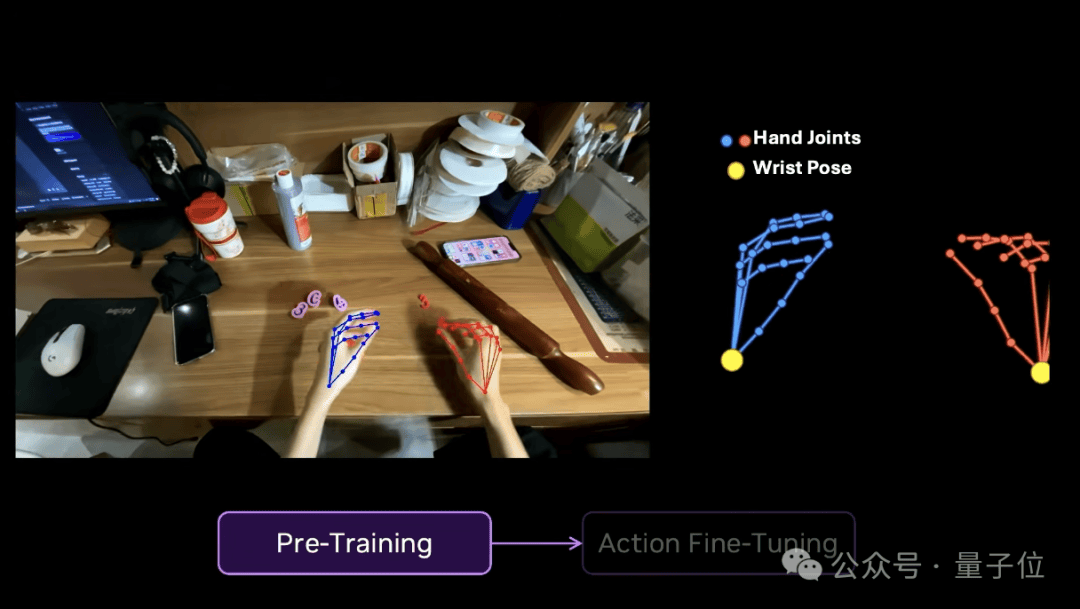
到了动作微调阶段,我们只额外采集了50小时的高精度数据手套数据以及4小时的遥操数据,这甚至不到整个训练数据混合中的0.1%。

而靠着EgoScale,模型已经能够泛化到各种高度灵巧的任务。比如,整理扑克牌、操作注射器、精准转移液体。说不定哪天,家里的机器人护士,真会因此出现。
更有意思的是,对于像折衬衫这种任务,模型在测试阶段只需要一次示范就能学会全新的折叠策略。
这篇论文里,也许最令人兴奋的发现是,我们第一次发现了“机器人灵巧性”的神经scaling law。
它描述的是预训练时长,与最优验证损失之间的关系。这个关系,漂亮得惊人。
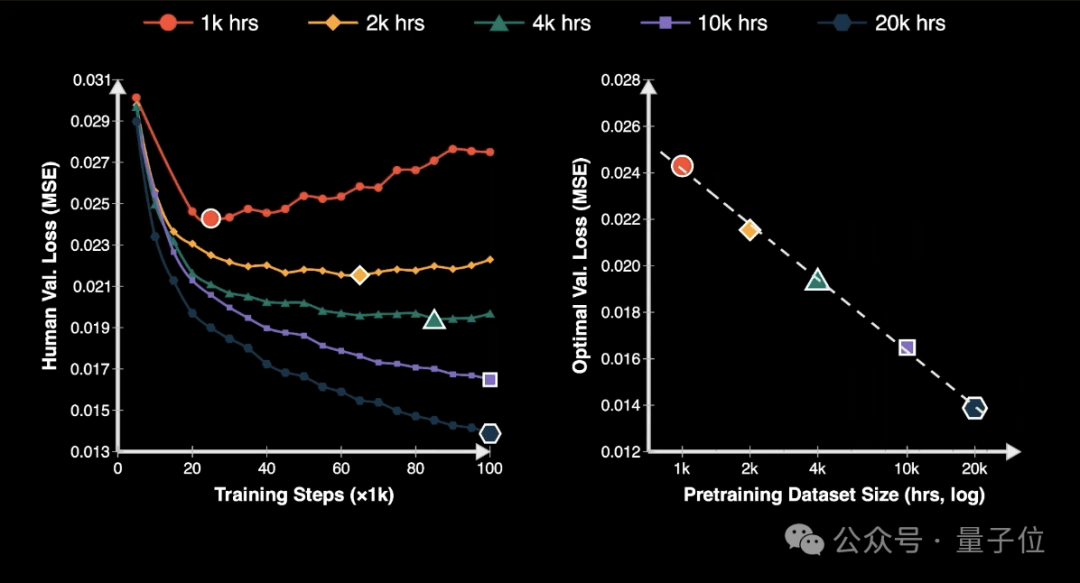
它几乎是一条完美的log-linear(对数线性)曲线。距离语言模型第一次发现neural scaling law,已经过去整整六年。
如今,机器人,也终于有了自己的scaling law。如果把这些数据策略画成一张图:X轴,和机器人硬件的对齐程度;Y轴,可扩展性。
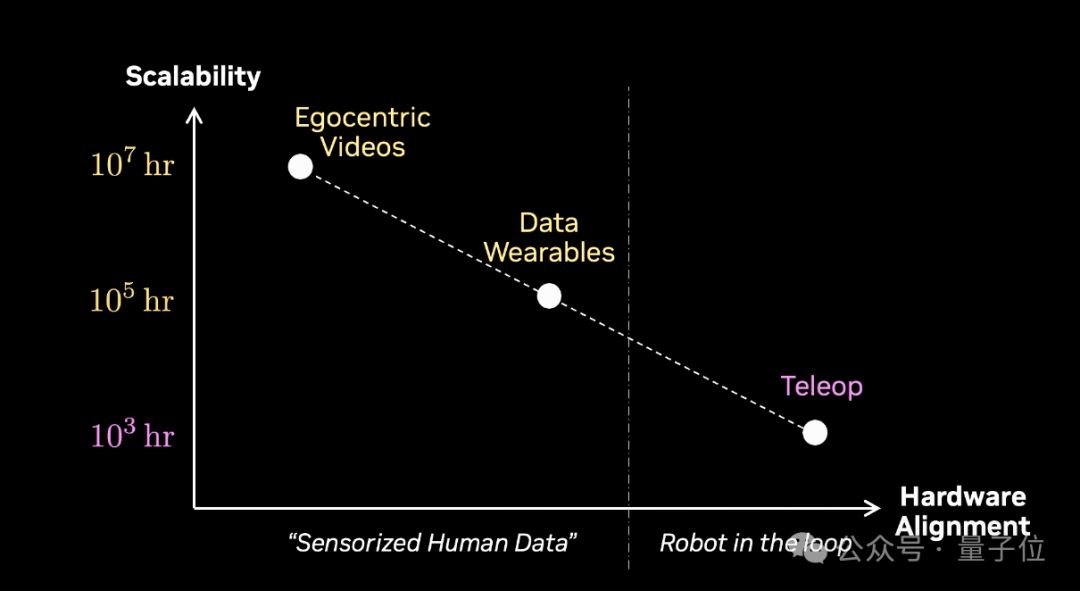
那大概会是这样,遥操作在最左下角。它最贴近机器人硬件,但几乎最难扩展。
再往上,是数据穿戴设备,它大概能扩展到几十万小时。
而再往上,是第一视角视频如果我们真的能跑通机器人版的自动驾驶飞轮,那它的规模,轻轻松松就能达到千万小时级。
如果在图上画一条线,那这条线左边,代表的是机器人的新范式Sensorized Human Data,人类的传感器数据。
所以,我想大胆做几个预测未来一到两年,遥操的占比会越来越低。低到几乎可以忽略不计。
接下来,会出现大量针对不同机器人硬件、不同场景量身定制的数据穿戴设备。
而最终,机器人的“主食”,会变成第一视角人类视频。
所以,让我们再次为我们的老朋友,遥操,默哀片刻。

它曾经很好地服务过我们。安息吧。遥操已死。人类传感器数据长存。
但数据策略,到这里就结束了吗?没有。
你注意到我画了两层圆。那外圈是什么?
今天,所有前沿实验室都在砸重金购买数百万个代码环境用来做强化学习。
机器人也一样。我们迫切需要海量环境。
当然,你也可以直接在真实机器人上做RL。在我们的实验室里,我们用RL把某些任务推到了接近100%成功率。
机器人可以连续执行几个小时不停。说实话,看着机器人自己默默组装GPU,还有点治愈。
正如一位智者说的Good boi(这项任务,已经通过老板审批。)
但问题是,如果机器人也想像今天的大模型一样,把强化学习真正推向百万环境的规模,传统路线几乎走不通。
因为按过去的做法,100万个环境几乎就意味着你得先准备100万台机器人,这在成本、维护、部署上显然都是不现实的。
于是,我们开始寻找一条全新的路。
比如,你只需要拿出一台iPhone,随手拍下一张现实世界的照片,再把它送进一套3D world scanning pipeline(3D世界扫描管线),系统就能自动识别场景中的所有物体,提取它们的三维结构,并进一步把这些物体自动重建到经典物理模拟器里。
更关键的是,这些被重建出来的物体不是静态模型,而是真正可以被交互、被操作、被碰撞的数字实体。
接下来,研究人员还可以基于这些场景无限扩增各种变体,他们把这些变体称为Digital Cousins。
到了这一步,iPhone不再只是手机,而变成了一个真正意义上的“口袋世界扫描仪”。
而整个流程,也被命名为Real→Sim→Real——从真实世界出发,进入仿真,再回到真实世界。
靠着这套方法,机器人终于第一次拥有了一种可以规模化地把物理世界搬进数字世界的能力。
但即便如此,这套方案本质上依然建立在传统的图形学模拟器之上。
那么,我们还能不能再往前走一步?
来吧!Dream Dojo。
Dream Dojo是一套建立在视频world model之上的、真正意义上的神经模拟器,它接收输入的不再是传统物理参数,而是一连串连续的动作信号;
而输出的,则是机器人下一刻将会看到的RGB视频画面,以及对应的传感器状态,并且这一切都是实时生成的。
换句话说,你此刻看到的画面里,没有一个像素是真的。
Dream Dojo能够通过一种纯粹数据驱动的方式,直接捕捉并学会不同机器人背后的运动机制和动力学规律,整个过程里,没有任何物理方程参与,也没有任何图形学引擎介入。
因此,机器人正在进入一个全新的post-training范式。
少量真实机器人站点负责在物理世界中持续采集高价值交互数据,而另一端则是大规模并行运行的graphics cores、world scans以及高强度推理计算,共同支撑世界模型的持续迭代。
在这个新范式里,有一个极其关键的等式正在成立——
算力=环境=数据。
也就是说,算力正在变成环境,环境正在变成数据,而数据本身又反过来定义下一轮算力投入,整个过程开始像自动驾驶里的FSD flywheel一样形成自我强化的飞轮。
正如老板半开玩笑地总结的那样“买得越多,省得越多。”当然,这句话也已经通过他的审批。
把这一切拼在一起,你会发现,机器人正在走上一条和大模型几乎完全平行的进化路径,而且这一切不是未来式,而是此刻正在发生。
我们眼前看到的,也许正是机器人终局之战的开端。
我一直最喜欢《文明》,并且喜欢把自己的研究想象成在文明科技树上不断解锁成就。
如果按照我的判断,机器人这棵科技树上,现在只剩下最后三个成就等待被点亮,只要全部解锁,我就可以退休了。
第一个成就,叫做物理图灵测试。
所谓物理图灵测试,说白了就是在足够丰富、足够复杂的现实任务里,人类已经无法仅靠观察去判断,眼前完成工作的到底是人类,还是机器人。
它并不神秘,无非就是单位能源输入,单位劳动力输出。只要同样的能量输入能够产出同等级的劳动价值,机器人就真正通过了物理世界里的图灵测试。
也许喝醉的人类不算在内,而看看今天机器人那些还有些“僵硬甚至略显性感”的动作姿态,我们显然还有很多工作要做,但如果一切顺利,他认为这件事距离我们可能只剩下两到三年。
第二个成就,叫做Physical API。
那时候,机器人将不再是一台台独立存在的机器,而会像今天的软件服务一样,变成一种真正可编程、可调用、可编排的基础设施。
你拥有的可能不再是一台机器人,而是一整个舰队,而你控制它们的方式,也不再是按钮和控制器,而是API、CLI以及更高级的编制系统。
也许某一天,这一切甚至会由比今天更强大的agent,比如Opus4.6,统一进行调度。
而一旦Physical API真正出现,很多今天听起来像科幻的东西都会迅速落地。
比如所谓的Lighthouse Factories——灯塔工厂,它们本质上不再是流水线,而更像“原子打印机”,你输入的不再是CAD图纸,甚至不需要复杂工程文件,而可能只是一份markdown文档,输出的却是已经完全组装好的实体产品,整个过程完全自主完成;
又比如wet labs,也就是自动化湿实验室,机器人将独立完成化学实验、生物实验乃至药物研发,把科学发现的速度推到人类实验室从未达到过的高度。
而最后一个,也是机器人科技树上的终极成就,叫做Physical Auto Research。
到了那一天,机器人将不再只是执行人类交给它们的任务,它们会开始自己设计自己,自己优化自己,自己制造下一代自己,并且迭代速度将远远超越任何人类工程团队所能达到的极限。
听到这里,你也许会觉得,这听起来已经太像科幻了,我们这一代人真的有机会看到吗?
从2012年AlexNet完成第一次forward pass开始,那个连猫和狗都分得磕磕绊绊的模型。
到今天,整个AI community只用了14年,就走到了agentic AI时代。
而今天是2026年,如果机器人也遵循类似的指数曲线,那我们不妨再给它14年,2026年刚好站在2012年和2040年的正中间,而技术从来不是线性前进的,它永远以指数形式爆发。
所以,我有95%的把握,在2040年之前,我们会真正走到机器人科技树的终点,而等那一天到来时,我们依然年轻。
我们的这一代人,也许出生得太晚,没赶上探索地球,也出生得太早,还没赶上探索星辰,但我们出生得刚刚好,因为我们正好赶上,去解决机器人。
纵观整个演讲,Jim Fan描绘的路线图充满雄心,但也存在一些需要审视的环节。首先,EgoScale和Dream Dojo的规模化有效性尚需更多第三方验证,尤其是神经模拟器能否在实际复杂工业环境中稳定替代物理模拟,仍是一个悬念。其次,将第一视角人类视频直接转化为灵巧手策略,涉及巨大的域迁移问题——人类的手部结构和速度与机器人机械手存在本质差异,模型能否真正“理解”这些差异或在训练中被自动弥补,取决于数据多样性和网络结构的鲁棒性。最后,关于2040年解锁全部科技树的预测,虽然听起来激动人心,但物理世界中的意外和长尾问题远比LLM面临的文本空间复杂,过度乐观可能掩盖执行中的系统性挑战。不过,方向性的确定性正在变得清晰:具身智能已不再满足于模拟人类,而是开始寻找属于自己的Scaling Law。