< img id=”wx_img” src=” width=”400″ height=”400″>
“1%是我写的,99%是Agent写的。”
一位不愿具名的观察者 发自 凹非寺
智能涌现 | 公众号 AIFront
DeepSeek研究员陈德里,在个人博客更新了一篇研究综述论文。
1%是我写的,99%是Agent写的。
所用的工具组合颇为讲究:DeliAutoResearch(他自研的智能体管线)负责核心研究写作,DeepSeek-V4-Pro提供推理能力,GPT-Image2负责图表生成。
论文共迭代6次(V1:4次,V2:1次,V3:1次),总耗时6天,进行了约108轮Agent调用,消耗64.8万token,最终输出2234行LaTeX代码。
103个参考文献,全部经过交叉验证。论文现为46页,538KB,含7个图表+4个表格。

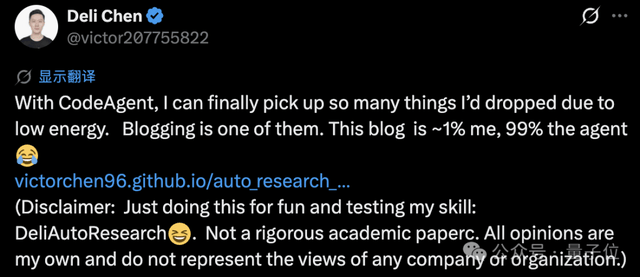
论文聚焦自动研究智能体的L1–L5自主度分类体系,这是一套试图为混乱的AI Agent研究领域建立秩序的标准。
通过分析四大架构模式,从可扩展性、成本、可靠性等维度进行横向对比。
并基于六维特征矩阵,对17个主流系统进行了系统级剖析。
还提出了六大开放问题与对应研究方向,为后续工作提供了路线图。
陈德里认为,Code Agent的普及导致计算机科学领域的论文数量呈现指数级膨胀——同样的工作以往至少需要一个月才能完成。
但现在,他的大脑(碳基)处理这个问题的“总CPU时间”不到2小时。这种对比本身就在提醒我们:研究的生产力正在发生结构性变化,而评价体系尚未跟上。
他也写了一句免责声明:观点仅为个人所有,不代表任何组织。这或许是AI辅助时代下,研究者必须反复强调的灰色地带。

基础模型的快速迭代,正推动AI工具从“研究辅助”向“自主研究”跨越。但领域内缺乏统一框架、术语混乱、评估标准不一——这些问题如果得不到解决,所谓的“自主研究”只会沦为各自为战的技术demo。
陈德里和他的AI合著者,提出了一个L1-L5的自主分级体系。这并非首创,但将SAE自动驾驶分级思路迁移到AI Agent领域,确实让混乱的图景清晰了许多。
类比自动驾驶的SAE级别,把混乱的AI Agent领域理出了清晰的谱系。这种跨领域类比的价值,在于它让研究者、工程师甚至投资者都能快速理解当前技术所处的阶段。

- L1是最基础的自动补全——GitHub Copilot的早期形态,预测下一行代码。
- L2是任务执行——ChatGPT/Claude聊天机器人结合工具,能分解任务但每一步需人类批准。
- L3是多步骤执行——目前主流的Claude Code、Cursor Agent,能自主执行10到100步,关键节点请求审核。
- L4是受限领域内全自主执行——人类仅提供研究目标、评估最终成果,智能体可完成多步实验、代码、论文撰写,但无法自主选择研究问题。
- L5是完全自定研究议程——智能体可自主选题、分配资源、长期积累知识、跨领域持续研究,这是当前尚未实现的理想状态,核心瓶颈在于持续知识积累、可靠自我评估、架构规模化。
目前行业前沿初步达到L4,L5仍停留在设想阶段。值得注意的是,论文中强调了一个容易被忽略的观点:真正的瓶颈并非模型能力,而是“持续知识积累”和“可靠自我评估”。这提示我们,单纯提升参数规模并不能解决自主研究中的长期记忆和幻觉控制问题。
论文认为真正的瓶颈不是模型能力,而是「持续知识积累」和「可靠自我评估」。
除了按自主性分级,论文还从架构视角总结了4种主流模式。这种双重分类法——既看能力等级又看实现方式——让理解更加立体。
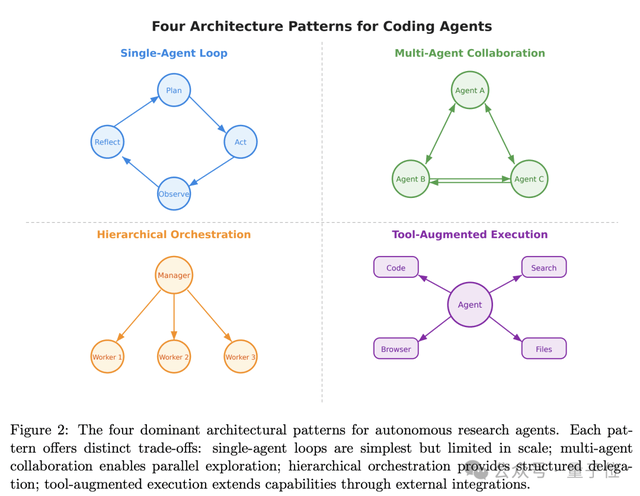
早期研究以ReAct、Reflexion、LATS、思维树等为代表。单智能体迭代推理-行动-观察,简单高效但复杂任务能力有限。这类模式在简单场景下性价比极高,但遇到需要多步推理的任务时,容易陷入局部最优。
以CAMEL、AutoGen、MetaGPT为代表的多智能体协作模式,特点是分工协作、多视角纠错。成本较高且沟通容易混乱。但它在需要不同“角色”互相验证的场景中(如代码评审、论文润色)表现出独特优势。
Claude Code和Devin等采用分层调度架构,通过分层规划、任务分解,适合长时程复杂研究。这种模式对底层工具的调度能力要求较高,但执行稳定性最好。
SWE-Agent等代表工具增强执行模式,核心工具有代码执行环境、网页浏览、API/数据库、多模态工具。Agent-Computer Interface(ACI)的设计直接影响性能。这一模式的关键不是模型有多强,而是工具链的完备程度。
论文指出四种模式并非优劣之分,而是需根据任务特性选择:简单短任务选单智能体循环(低成本、易实现);需多视角纠错、复杂分工选多智能体协作;长时程、高复杂度研究选分层调度(强规划、易监管);需对接外部工具选工具增强执行(能力边界由工具决定)。
在实际应用中,多数系统其实都采用混合架构,结合多种模式优势。这种务实态度值得肯定——毕竟AI研究的终极目标不是架构的纯粹性,而是解决问题的有效性。
但实际应用中,其实多采用混合架构,结合多种模式优势。
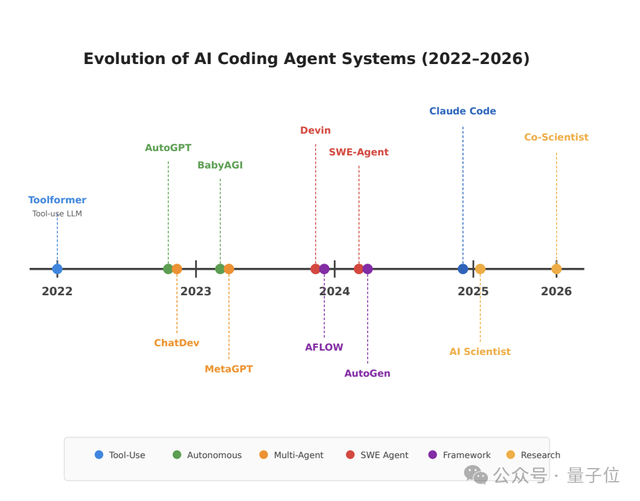
有了研究框架,论文横向对比了当前常见的17个自主研究智能体。结果揭示领域已从早期通用脆弱原型,演进为L4级受限域专用系统。代码智能体成熟度最高,科学智能体开始产出可验证的新发现——比如英伟达的Cosmos模型已经在材料科学领域有了实际应用。
而迈向L5完全自主的核心瓶颈在于持续知识积累、可靠自我评估、架构规模化。这三点并非孤立的,知识积累依赖于可靠评估,而评估又需要架构支持长期记忆。
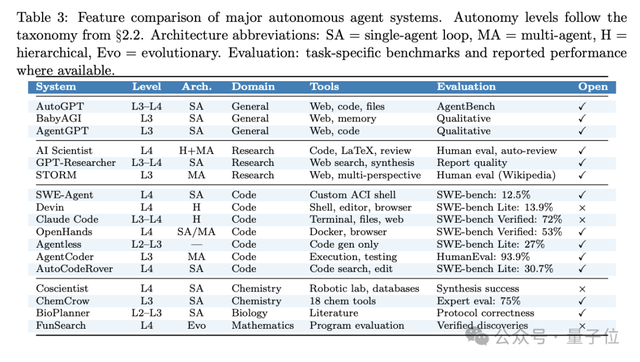
论文最后提出六大开放问题,这些问题既是挑战也是研究方向:
- 认知循环陷阱:智能体陷入重复无效策略,无自我终止能力。当前大多数Agent缺乏“放弃”的机制,这在实际研究中会导致资源浪费。
- 上下文限制:固定窗口(4K-1M token)无法支撑长时程研究。即便使用无限上下文方案,也存在注意力衰减的问题。
- 创新性评估:缺乏自动化方法衡量研究原创性与价值。目前的论文评审仍高度依赖人工,而AI生成的内容让评审更加困难。
- 可复现性:模型随机性、提示敏感性导致结果无法复现。这是AI研究领域的顽疾,在Agent场景下被放大。
- 安全伦理:双用途风险、自主提升风险、学术诚信风险。当Agent可以自主写论文,学术界的“作者”定义需要重新思考。
- 成本问题:单任务成本高达50美元,高成本加剧科研不平等。资源丰富的机构将获得更大的优势,可能进一步拉大全球科研差距。
陈德里自述,高强度工作导致的精力不足曾让他搁置了很多事。博客、写作,一度成为奢侈。现在,Agent让他有机会把这些重新捡了起来。
除了这篇研究综述,他还用Agent更新了个人主页。这些原本需要数小时甚至数天的工作,现在只需下达指令即可完成。
有了Agent,这些任务完成起来效率超高。但更值得关注的,或许是这句话背后隐含的范式转变:人类的角色,从“执行者”变成了“发起者”。
当研究者只需要贡献1%的灵感,而99%的苦活交给Agent时,学术产出的加速器已经启动。接下来需要回答的问题不再是“AI能不能写论文”,而是“我们如何确保论文的质量不会被这种速度冲淡”。






