机器人训练领域长期存在一个隐形共识:要想快,就得把所有计算都塞进GPU。IsaacLab、MuJoCoPlayground、mjlab等主流框架无不遵循这一范式,结果就是整个生态被牢牢绑定在NVIDIA的CUDA围墙里。但最近,清华AIR DISCOVER Lab联合多家机构放出了一套新架构——UniLab,直接挑战了这个“默认选项”。
从技术底层的系统设计看,UniLab的破局点在于把仿真和训练彻底解耦。传统GPU管线把物理引擎的步进和策略网络的更新串行塞进同一块显卡,导致显卡忙着算物理时CPU闲着,CPU忙着算数据时显卡又歇了。UniLab的做法是:CPU侧用多核并行跑MuJoCo或MotrixSim等物理引擎,GPU侧专心做策略梯度更新,中间通过共享内存建立无锁缓冲区,让CPU仿真和GPU训练的数据流高度重叠。这样一来,不仅消除了跨总线搬运的延迟,还把硬件的每一丝算力都榨干了。
这套思路的收益在实测中非常直观。在相同硬件配置下,UniLab达到相同训练目标奖励的端到端时间,比传统方案快了3到10倍。团队还在6类真机任务上做了闭环验证:四足行走、人形全身运动追踪(包括翻跟头、攀爬),以及灵巧手操作,全部从仿真平滑迁移到了实物机器人。这种“仿真训练半小时,真机部署跑起来”的效率,放在以前很难想象。
更值得关注的是,UniLab彻底摆脱了硬件绑定。它原生支持CUDA、Apple、AMD、Intel等多种后端,甚至在Mac(Apple Silicon)上利用统一内存架构的低延迟特性,让本地训练人形机器人成为现实。工业级的代码成熟度意味着研究者3分钟就能配好环境、5分钟跑通第一个demo。团队还展示了令人咋舌的数据:在4090+9950×3d的系统上,12秒训练好四足行走,3分钟让人形G1学会走路——机器人运动控制训练正式迈入“分钟级”时代。
清华AIR DISCOVER Lab投稿
在具身智能训练中,“把计算全部塞进GPU”似乎成了唯一的提速密码,机器人运控并行训练的框架,IsaacLab、MuJoCoPlayground、mjlab都默认遵循这一范式,这些系统都牢牢绑定在NVIDIA生态中。
清华大学智能产业研究院(AIR)DISCOVER Lab联合清华、上交、上海创智学院等多所高校和谋先飞技术、求之科技、原力灵机,正式推出了全新的机器人强化学习训练架构——UniLab。

团队另辟蹊径,通过大胆重构系统结构,打破了“GPU包揽全部”的潜规则,为具身智能打造了全新一代“CPU高效仿真+GPU策略训练”的异构高吞吐训练底座,在多项运控任务训练上实现了数倍效率提升。
UniLab从底层重新组织了仿真、数据采集与策略学习之间的系统结构。
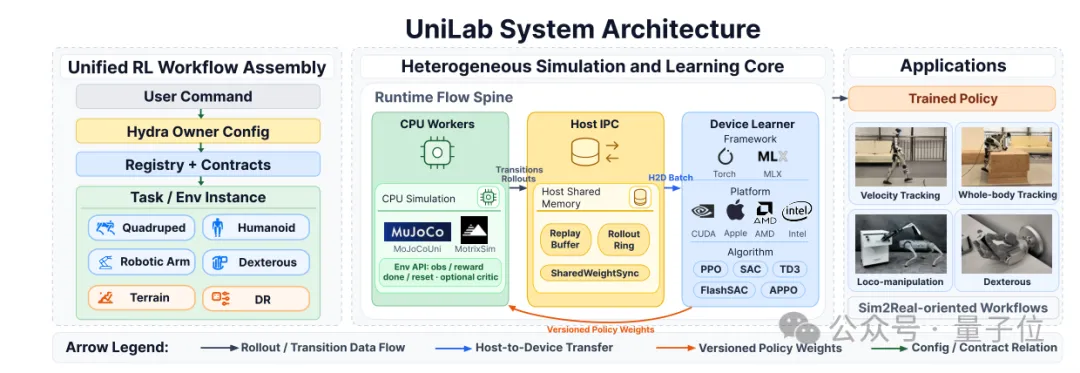 △UniLab系统架构图
△UniLab系统架构图传统GPU管线将物理步进与策略学习同步串行执行,所有的计算都放在GPU上,导致显卡和多核CPU出现“一方计算、一方闲置”的资源闲置。
- 并行解耦:UniLab采用异步异构架构,CPU侧利用多核算力并行运行MuJoCo或MotrixSim高保真物理引擎,GPU侧则专注于策略网络梯度更新。
- 数据流高度重叠(Overlapping):利用共享内存建立无锁的运行时缓冲区。当GPU在执行当前Batch的网络更新时,CPU阵列已经在异步并发跑完下一步环境仿真,消除了昂贵的数据跨总线搬运延迟,榨干每一份硬件算力。
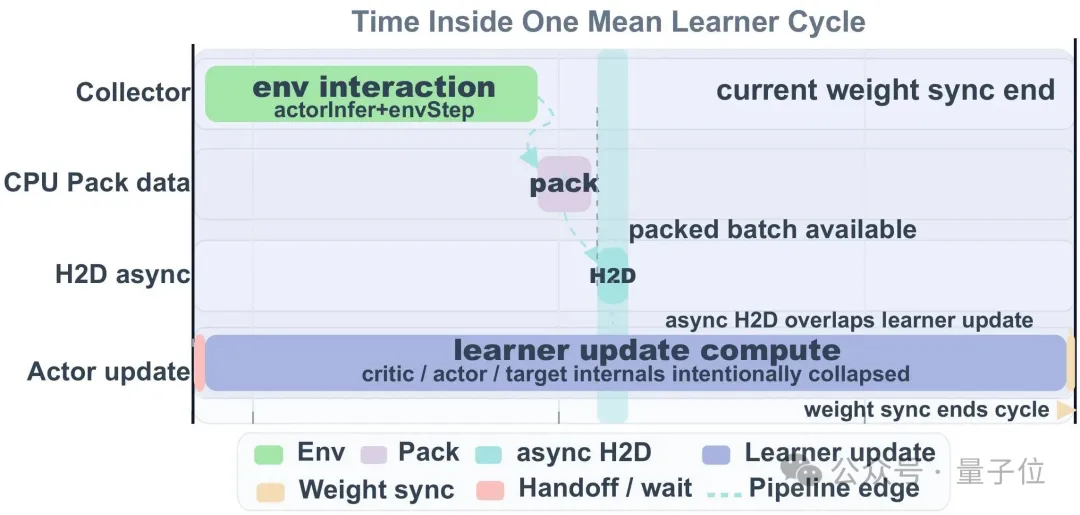 △UniLab单周期流水线时序
△UniLab单周期流水线时序传统GPU管线将仿真和学习绑在同一块显卡上,资源互相争抢。
UniLab用实测数据证明,将仿真解耦到CPU侧并通过运行时协调,可以带来显著的端到端墙钟时间(Wall-clock Time)收益:
- 3-10倍爆发提速:在相同硬件的基准测试中,UniLab达到相同目标奖励的端到端训练速度比传统方案快3至10倍。
- 真机验证闭环:团队已将UniLab训练的策略成功部署到6类真机任务上,覆盖四足行走、人形全身运动追踪(含翻跟头、攀爬)以及灵巧手操作,完成了从仿真到真机的完整闭环验证。
 △端到端训练效率对比曲线
△端到端训练效率对比曲线UniLab彻底去除了对特定硬件的硬编码依赖,让机器人强化学习训练走向大众化:
- 跨平台全后端兼容:原生支持CUDA、Apple、AMD及Intel等多种后端,无缝适配PPO、APPO、SAC、TD3等主流强化学习算法。
- Mac训练神器:在Mac(Apple Silicon)平台上,UniLab借助统一内存架构(UMA)的低延迟特性,CPU仿真与GPU学习之间的数据传输无需跨越PCIe总线,传输开销大幅降低。让Mac本地训练人形机器人成为现实。
- 全品类任务覆盖:基于统一的任务接口,UniLab不仅支持四足和人形行走,还完美覆盖高动态人形动作跟踪(G1 Flip、G1 WallFlip、Dance等)、高维接触的灵巧手精细操作(Sharpa hand),以及复杂的全身手脚协同(Loco-Manipulation)。
- 超高效训练系统:4090+9950×3d的系统上,12秒训练好四足行走,3分钟人形G1学会走路,让机器人运控训练迈向“分钟级”时代。
- 工业级成熟代码架构:工业开发级代码构建成熟度,零成本上手,3分钟本地配好环境,5分钟运行好第一个demo,面向AI-Native的开发协作模式让机器人模型和算法迁移“零摩擦”。
 △多任务应用场景 collage
△多任务应用场景 collageUniLab现已正式开源。
未来项目将围绕接触密集型灵巧操作的物理保真度评测、算法benchmark、以及多模态触觉策略等方向持续迭代,将UniLab从一个高效训练系统进一步扩展为通用的机器人学习研究平台。
客观来看,UniLab的价值不仅仅在于提速本身——它打破了“机器人训练必须依赖特定显卡生态”的思维定式,让更多研究者可以用Mac甚至AMD平台参与具身智能研究,对降低行业门槛意义重大。当然,目前UniLab仍处于早期开源阶段,在超大规模并行仿真场景下的稳定性、以及复杂接触动力学下的物理保真度,还需要更多社区验证。但方向本身足够清晰:与其让CPU闲置,不如让它和GPU各司其职。这种朴素而有效的系统重构,或许正是具身智能走向更广泛实用化的关键拼图。





