当AI Agent开始像人类一样“思考”时,一个尴尬的真相浮出水面:它们获取信息的管道,依然是几十年前为人类眼球设计的搜索引擎。这种错位,正在成为制约Agent能力天花板的关键瓶颈。
Agent模型在推理能力上突飞猛进,但喂养它的信息源,却仍是一个为人类视觉浏览习惯打造的搜索体系。金融数据、裁判文书、学术引用、威胁情报——这些完成专业任务真正需要的高价值数据,大多隐藏在传统搜索引擎无法触及的角落。这些开发者日常体验中的痛点,导致Agent和AI工作流在执行复杂任务时,往往需要经历多轮低效搜索。信息更新不及时、来源不可靠,这些低质量数据会直接将后续的推理引向错误方向。
针对这一结构性缺陷,一家初创公司推出了专为Agent设计的AI搜索层服务。AnySearch于5月11日正式上线,首月即吸引10万名全球开发者接入,累计搜索调用量突破400万次,GitHub Star数超过4000。来自亚太、北美、欧洲等地区的开发者,已将其设置为Agent的默认搜索层工具。
AnySearch上线仅一周便登顶Agent技能市场Skills.sh热榜;6月3日,V2.1.0版本正式发布,完成了上线以来算法层与架构层的核心升级。
适配Agent需求:重构传统搜索逻辑
AnySearch要解决的核心问题,是当前搜索体系与Agent需求的根本错位:过去三十年的搜索引擎全部围绕人类视觉设计,以Top-K相关性作为主要优化目标。但Agent不是人,它拥有更宽、更平缓的信息感受野,能短时间消化大量输入,搜索结果会直接进入后续推理链路,成为分析和决策的依据。给人看的相关性排序,对Agent而言是一套过时的机制。
“我们认为,未来Agent的竞争不仅是模型能力的竞争,更是信息获取能力的竞争。” AnySearch联合创始人韩广彤表示。
图丨 AnySearch团队成员(来源:AnySearch)
AnySearch核心成员均为资深AI开发者。在产品开发初期,他们围绕AI Agent信息获取的话题,深度访谈了100多位开发者,提炼出三个普遍需求:搜索过程要高效,减少调用次数和上下文消耗;相比覆盖更多网页,开发者更想直接拿到金融、法律、学术、安全这类专业领域的多维数据;他们要的不是又一个搜索引擎,而是一套贴合Agent、AI工作流的信息获取基础设施。
全链路智能搜索:少量调用完成复杂专业调研
基于对开发者需求的深刻洞察,AnySearch构建了一套全新的搜索体系。一条查询进入AnySearch,第一步不是直接检索,而是查询理解。
以企业尽调场景为例,用户在Agent里输入查询某公司股权结构、涉诉记录和专利布局的指令,系统会先识别出这是一项企业研究任务,并把它拆解成几个维度的信息需求。随后进入路由编排:股权结构走企业工商数据源,涉诉记录走法律数据库,专利布局走知识产权数据库,多路并行检索。

图丨 AnySearch的查询检索流程(来源:AnySearch)
结果返回后,系统对不同来源的数据做归一化、重排序和结构化融合,把股权关系、经营记录、诉讼信息和专利数据映射到同一家企业实体上。最终交付给Agent的是一份带来源标注的结构化尽调结果,Agent可以直接基于它生成报告。
同样的路由逻辑适用于AI编程、学术研究等垂直领域,其价值不只是信息更准,也在于减少无效检索带来的延迟和资源浪费。
这种效率差距是可以被量化的。在AnySearch最近做的一次搜索能力测试中,几个接入不同搜索工具的Agent完成同一项代码研究任务,所有方案都找到了正确答案,但AnySearch只用了1次搜索调用,其他工具分别用了7次、16次和28次。有开发者实测反馈,平台输出的金融数据精确到了具体数字,而不是模糊的“大幅增长”。
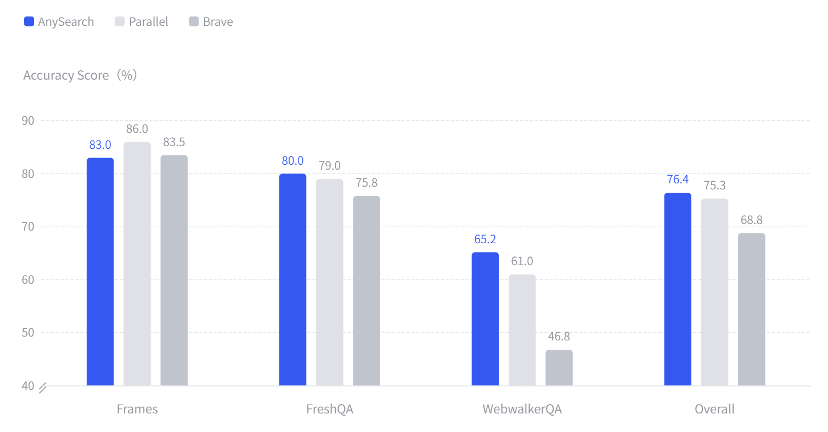
图丨 AnySearch在三个基准数据集上的准确率表现(来源:AnySearch)
V2.1.0的升级重点也在这条链路上:算法层引入了融合语义相关性与时效性信号的混合排序,架构层重构了领域划分和路由逻辑。韩广彤表示,此前最大的瓶颈不是单纯的延迟或准确率,而是搜索质量的稳定性,当Agent开始处理越来越复杂的跨领域任务时,系统需要持续返回正确结果。
自建数据管线的苦活儿,成为信息护城河
专业数据从哪来,决定了产品的质量。AnySearch采用自建索引加外部数据源接入的联邦架构。对于金融、法律、学术、安全、企业工商等高价值领域,团队建设了自己的数据管线,覆盖采集、清洗到索引构建的端到端链路;核心数据完全自主可控,规避第三方API带来的质量、更新频率与稳定性问题;通用场景与长尾需求则通过外部数据源补足。
针对金融、司法等高容错率场景,平台搭建了多源交叉验证机制,所有结构化数据均保留来源信息和可追溯链路,避免Agent基于单一来源信息做出误判。
但真正的苦活儿在日常维护。专业数据运维是长期深耕的系统性工作:不同领域数据更新节奏差异极大、接口协议和质量信号完全异构、跨领域之间也不存在天然可比的质量标准。此外,Agent拿到结果后推理效果如何,搜索系统看不到,只能靠间接指标持续改进。韩广彤说:“这是一块永远滚不到山顶的石头”。
Skill接入方式走红,社区生态自发生长
AnySearch同时支持Skill、MCP、API三种接入方式,几乎零配置、易部署的Skill方案最先出圈,在社区赢得了广泛认可,AnySearch上线仅一周便冲上Agent技能市场Skills.sh的热榜第一。
图丨 AnySearch的GitHub主页(来源:GitHub)
韩广彤表示,虽然AnySearch Skill在GitHub上的关注度高于MCP,但这不代表实际使用量领先。在团队的定位里,Skill适合个人轻量化场景,MCP与API更适配企业级深度集成与生产环境部署,本地化MCP方案也在持续探索中。
除了增长速度超出了预期,更让团队意外的是扩散方式。越来越多开发者自发为AnySearch编写第三方工具和工作流,一些团队原本没有重点关注的Agent框架里,也出现了社区贡献的集成项目。
商业模式清晰,持续验证信息质量的价值
生态的自发生长解决了从0到1的认知问题。做AI搜索能不能收到钱,先行者已经给出了肯定答案。
放眼全球,美国AI原生搜索厂商Exa以22亿美元估值完成融资,印证了赛道的广阔前景。而AnySearch走出了差异化路线:相比把网页搜得更准,AnySearch押注的是网页之外的专业数据。
目前,产品对个人开发者全面免费,Pro付费版与企业定制方案也在同步推进中,全程无广告、无用户数据追踪,查询处理后即销毁,以信息质量本身构建商业壁垒。
上线首月,10万开发者对AnySearch的产品力给出了正反馈。未来,AnySearch将持续迭代技术与数据能力,目标成为Agent和AI工作流的默认信息获取底层,也将持续验证高质量信息服务的商业化价值。
来源:AnySearch