在当前人工智能技术飞速迭代的背景下,语音合成(TTS)领域正经历着从“能听”到“好听”再到“情感丰富”的关键转折。以往高保真、多方言的语音模型往往依赖庞大的参数量与封闭的算力集群,这使得开源社区在这一领域长期处于追赶状态。然而,随着模型架构的优化与蒸馏技术的成熟,轻量化模型正在展现出令人惊喜的性能边界。
此次面壁智能发布的新一代语音模型,正是在这一趋势下的典型代表。它不仅在参数量上做到了极致的精简,更在语音的自然度、情感表达及多语言支持上取得了显著突破。对于开发者而言,这意味着在端侧设备部署高质量语音交互成为可能;对于普通用户,则意味着更低门槛的创意工具。以下是对该模型技术细节及实际表现的深入评测。
刚融资数亿元的面壁又发新模型,让歪果仁直呼 Amazing
金磊 发自 凹非寺
AI 技术观察 | 专业评测
终于,郭德纲老师那段堪称地狱难度的贯口——《莽撞人》,被一款免费开源的 2B 国产 AI 模型完美复刻了!
先来听为敬~

△ 图片和音频均为 AI 生成
视频地址:
这段《莽撞人》在业内被公认为难度顶尖,甚至是北影台词课的教科书级范本,不少专业演员面对它都得掂量掂量。
以往 AI 语音模型想要挑战这段贯口,要么语速跟不上,要么咬字含糊、节奏错乱,最关键的是往往缺乏那种抑扬顿挫的“韵味”。
但这一次,AI 通过自行音色设计生成的女声版贯口,不仅节奏拿捏得精准到位,就连百(bē)战百(bē)胜、白(bē)盔白(bē)甲白(bē)旗靠……这些极易出错的特殊发音也全部读对了!
包括近期网络上火爆的沈阳翻译片段,这个免费国产 AI 也能分分钟复刻出男声版:

△ 图片和音频均为 AI 生成
视频地址:
那几个让网友们笑翻了的小词儿:“音乐会儿”、“害有”、啊,国产 AI 把大姨东北话的灵魂捕捉得稳稳当当。
不止是东北话,这个语言模型已经可以 cover九种方言,像四川话版《大话西游》经典名场面,效果是这样的:
(注:九种方言分别是四川话、粤语、吴语、东北话、河南话、陕西话、山东话、天津话、闽南语。)

△ 图片和音频均为 AI 生成
视频地址:
“巴适得板”、“悔得抠脚”、“女娃儿”……
这小味儿确实有点满级四川方言的感觉了,而且还把周星驰原配音的声色给保留了下来。
除了方言加持,这个国产 2B 模型还有一技之长——同一段语音可以用不同国家的语言来演绎!
例如这段原先是中文的《甄嬛传》滴血验亲的名片段,就秒变成了韩语版:

△ 图片和音频均为 AI 生成
视频地址:
不论是语气还是人声,都有点中文原版的那个味道了。
当然,泰语版和西语版,也是手拿把掐:

△ 图片和音频均为 AI 生成
视频地址:
不仅如此啊,这个语音模型是直接可以 cover三十门外语的那种。
来听一下 30 种不同风格的“你好”:

如此好玩,还免费开源的国产语音模型,到底是何许 AI 是也?
不卖关子,它正是面壁智能联合OpenBMB 开源社区、清华大学人机语音交互实验室新升级的VoxCPM 2。
整体看下来,除了多语种、多方言之外,VoxCPM 2 在音色设计、音色可控和高表现力方面也是较为亮眼。
不少歪果仁在 VoxCPM 2 发布之后就立马去尝了下鲜,纷纷表示“自家语言的效果针不戳!”
而且在音质方面,市面一般是 24000Hz,但 VoxCPM 2 这次直接拔高到了48000Hz(CD 音质)!
这下子,游戏、动画、影视、有声书等领域的人可以说是有福了。
开源的 VoxCPM 2,我们现在就可以在在线体验的网站上体验了(地址见文末):
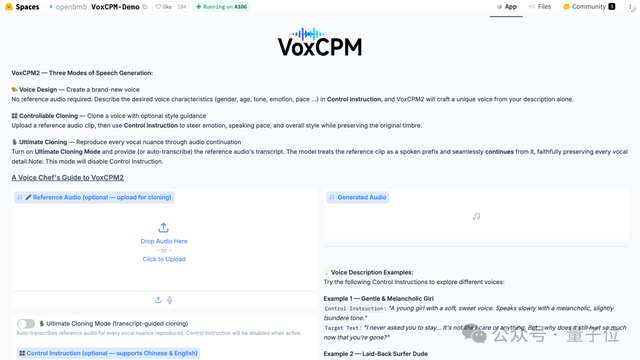
接下来,我们就一起手把手,搓一个东北话版的《火影忍者》。
首先在界面的左上角,我们上传一段宋小宝的原声片段,大概 20 秒左右:
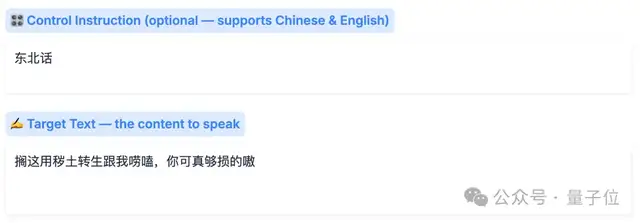
然后在它的下方,我们填一个“东北话”的指令,再把台词写进要合成的文本里,例如:
搁这儿用秽土转生跟我唠嗑,可真够损的奥。

接下来,我们只需要配上一小段视频,齐活儿:
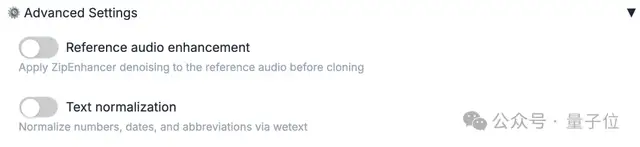
细心的小伙伴可能发现了,刚才宋小宝音频的 demo 里其实是有背景杂音的,但到视频里就没有了。
这其实是 VoxCPM 2 的参考音频降噪功能,只要勾选一下,声音就会变得清晰:
还有值得注意的是,视频里二代土影的声音,是没有上传任何参考音频的情况下生成。
然后如果想克隆声音的质量有保证,建议上传的参考音频尽量大于等于 5 秒;以及你还可以在”Control Instruction”里面添加提示词,改变参考声音的情绪和语速等等。
(但克隆声音的时候,是不能改变性别的哦~)
除此之外,还有 3 个小细节:
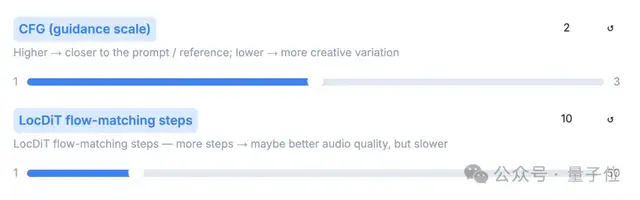
第一个是文本规范化,这是在你输入的台词里有日期、符号、阿拉伯数字等 AI 读不明白的内容时,你就可以点它,让 AI 读得规范起来。
第二个CFG Value,它的作用是用来控制 AI 的听话程度,数值越高就越听你的要求,反之,AI 会自由发挥。
第三个就是LocDiT,设置它的步数越高,音频效果就会越好,但生成的速度就会变慢。
除此之外,台词中间停顿的音效,现在可以用 [laughing](笑声)、[sigh](叹气)、[Uhm](嗯……)这些标签来控制:

总而言之,现在要玩儿逼真、有趣的声音,简直太简单了。
看到这里,肯定有不少的小伙伴要问了:
只有 2B 大小,还免费开源的语音模型,到底是怎么做到的?
来,咱们这就扒一波。
首先就是 VoxCPM 2 走了一条跟市面上大多数模型不太一样的路线——采用扩散自回归连续表征(Diffusion Autoregressive Continuous Representation)。
和市面上主流的 Token-based 传统方案不同的是,它是基于 Tokenizer-Free 的 TTS 系统来做的设计,通过端到端扩散自回归架构直接生成连续语音表征,实现了隐式语义 – 声学的解耦。
简单来说,传统方案在语音转换时极易出现信息损失,而这套技术能最大程度保留原始声音的声学细节、情感基调和方言特色。
这也就是它既能完美复刻周星驰配音的声色,又能把东北话、四川话说得地道入味的核心原因。
与此同时,这款模型的底气,还来自面壁智能深耕多年的高密度小模型技术壁垒。VoxCPM 2 完全基于面壁智能自研的 MiniCPM 基座打造,延续了系列模型“小身板、大能量”的特质。
此前 VoxCPM 系列就已经在 Hugging Face 斩获超千点赞、5.5k+ 下载量,这次升级更是把多语种、高保真、音色可控等核心能力拉到了行业新高度。
更难得的是,VoxCPM 2 不止开源了完整的模型权重,更提供了从一键上手到大规模部署的全套工具链,支持原生 Torch 推理、LoRA 及全参数微调,还适配了多端 UI 扩展,上手使用变得超简单。
最后回到国产这个点。
放眼全球范围内,目前除了基座大模型牢牢占据了开源领先地位,在小模型、端侧模型上,中国公司也在持续领先。
体验地址:
GtiHub 地址:
HuggingFace 地址:
从技术演进的角度来看,VoxCPM 2 的出现标志着开源语音合成技术正在进入一个全新的阶段。传统的端到端模型往往需要在参数量与生成质量之间做出权衡,而通过扩散模型与自回归架构的结合,开发者能够在保持模型轻量化的同时,显著提升语音的自然度与情感表现力。这对于资源受限的边缘计算场景尤为重要,意味着未来智能硬件、车载系统乃至个人终端都能搭载更具“人情味”的语音交互能力。
然而,技术的进步也伴随着挑战。高保真语音克隆能力的普及,使得深伪技术(Deepfake)的风险进一步降低。如何在推动技术开源的同时,建立有效的伦理规范与鉴伪机制,将是行业接下来需要共同面对的问题。对于开发者而言,合理利用此类工具进行创意内容生产,同时尊重声音版权与个人隐私,将是使用该技术的基本准则。总体而言,国产开源模型在全球化竞争中的表现,无疑为技术生态的多样性注入了强劲动力。