具身智能的技术路线之争从未停歇。世界模型与视觉语言动作模型(VLA)各执一词,前者强调对物理世界的模拟与预测,后者则倾向于端到端的感知决策一体化。今日,Physical Intelligence 发布的最新进展,似乎为这场争论投下了一枚重磅炸弹,也为行业带来了新的思考维度。
π0.7:具有涌现能力的可控模型
深度观察 | 具身智能前沿
今日凌晨,Physical Intelligence正式推出了全新的 VLA 模型π0.7。这一进展在机器人领域引起了不小的震动,尤其在泛化能力上取得了突破性验证。
π0.7 首次在机器人领域实证了Compositional Generalization(组合泛化)的有效性。这意味着在面对未见过的任务时,模型能够自主组合已掌握的原子技能,构建出新的解决方案。

这就好比一名篮球运动员,掌握了跳投和后仰动作后,面对新的防守策略,能自行组合出“后仰跳投”,而无需教练专门教授这一特定招式。
在演示环节,两个核心能力尤为引人注目:
任务泛化:即便机器人从未接触过空气炸锅,也能依据指令,协调机械臂动作完成烤红薯任务。
本体泛化:将在某款机械臂上习得的抓取策略,无缝迁移部署至另一台不同构型的机械臂上。
值得注意的是,Physical Intelligence 的研究团队表示,目前尚难以完全界定π0.7 的能力边界。他们在探索中发现,模型的表现常常超出预期。
切黄瓜、削皮、倒垃圾、烤红薯……多种任务皆可胜任。
正如 Physical Intelligence 研究员Ashwin Balakrishna所言:
过去我总能根据训练数据推测模型的能力范围,但这一次,我无法预测了。
π0.7 的核心洞察其实可以浓缩为一句话:多样化的数据需要多样化的 Prompt。这一看似简单的改进,却带来了深远的影响。
传统的 VLA 训练往往仅提供单一指令(如“清理冰箱”),信号维度有限。π0.7 则将 Prompt 扩展为四个层级:

这四层包括:任务指令(清理厨房)、子任务指令(打开冰箱)、子目标图像(下一秒预期画面)以及 Episode 元数据(数据质量评分、错误标记、执行速度等)。
有了这些丰富的上下文信息,模型能够有效区分训练数据中的优劣、快慢与对错。
这使得模型能够消化此前无法利用的数据类型。失败的推演、低质量的演示、其他机器人的片段、人类的第一视角视频,全部转化为有效信号。
换言之,多样数据本身并非障碍,关键在于模型是否理解其所学内容的性质。
π0.7 新增的 Prompt 层,正是为了让模型明确“这段数据的质量如何、采用了何种策略
至此,具身领域首次迎来了通才模型性能追平专才模型的涌现时刻。
Physical Intelligence 联创Chelsea Finn在相关讨论中提到一个有趣的对比:
大语言模型的后训练,以往指针对下游任务微调。机器人领域长期陷于此阶段,追求极致性能往往依赖特定任务微调。
π0.7 改变了这一现状:开箱即用,且性能超越了经过微调的专家模型。
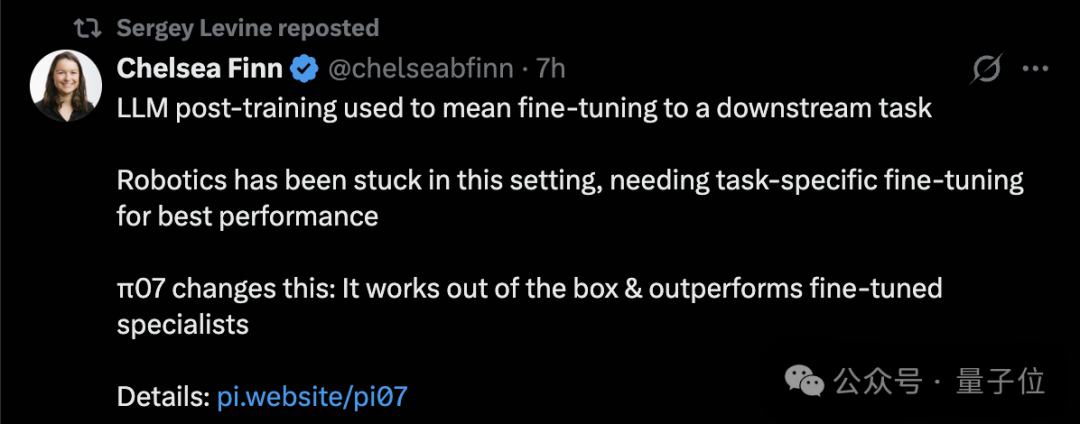
实验数据提供了有力支撑:
π0.7 未做任何专项训练,便在做咖啡、叠衣服、装箱三个复杂任务上,达到了π0.6 经过微调的专家模型水平。
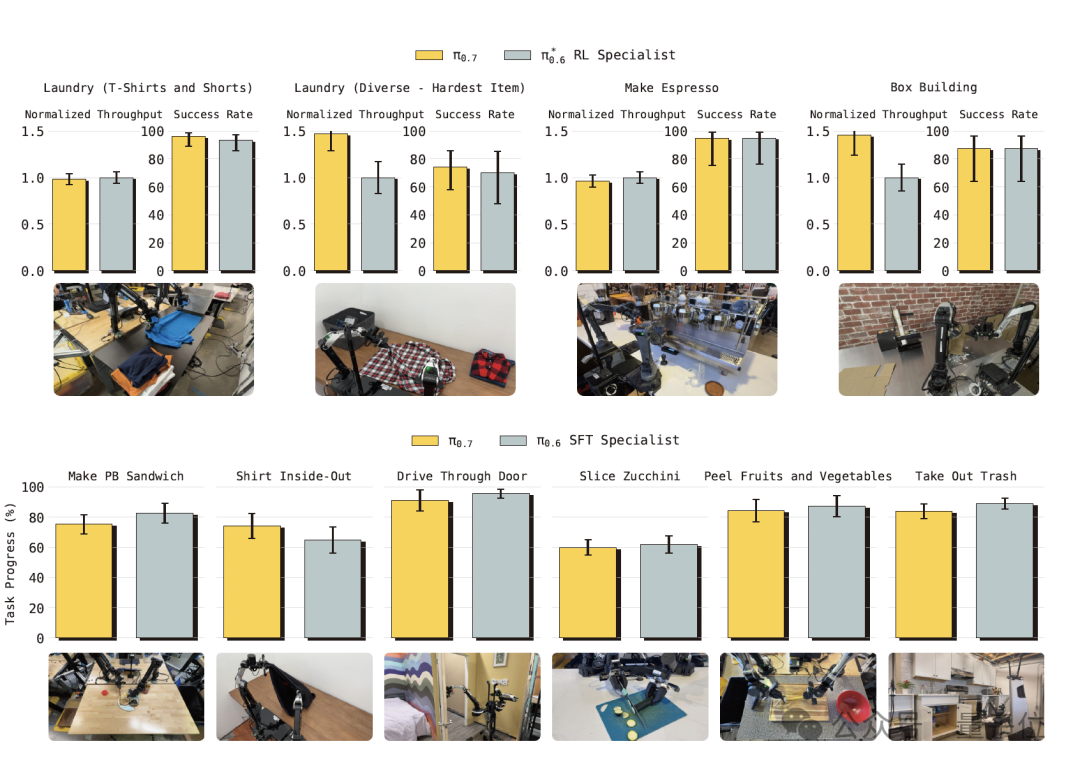
这里的专家模型包含两类:一是π*0.6 的 RL 专家模型,采用 RECAP 方法针对特定任务单独训练;二是π0.6 上的SFT 专家模型,针对每个任务单独微调。
更为显著的是,在叠衣服和装箱这两个高难度任务上,π0.7 单位时间内的完成次数甚至超过了 RL 专家模型。
可以说,一个未经专门训练的通才模型,击败了针对特定任务训练的专才模型。这也印证了 PI 一贯坚持的技术方向。
π0.7 的涌现能力主要体现在四个方面。
开箱即用的灵巧操作:做咖啡、叠衣服、剥蔬菜、削西葫芦、换垃圾袋。全程无需任务专项训练。
指令泛化:在 4 个未见过的厨房和 2 个未见过的卧室中,遵循 3-6 步开放指令完成任务。
甚至能理解“拿起那个最大盘子里的水果”、“拿起我用来喝汤的那个东西”等复杂的空间与语义指代。
跨本体泛化:在叠 T 恤等任务中,训练数据里并未包含任何 UR5e 机械臂的样本。
π0.7 不仅完成了任务,任务完成度达到 85.6%,与拥有平均 375 小时遥操作经验的 10 名顶级人类操作员的 90.9% 基本持平。
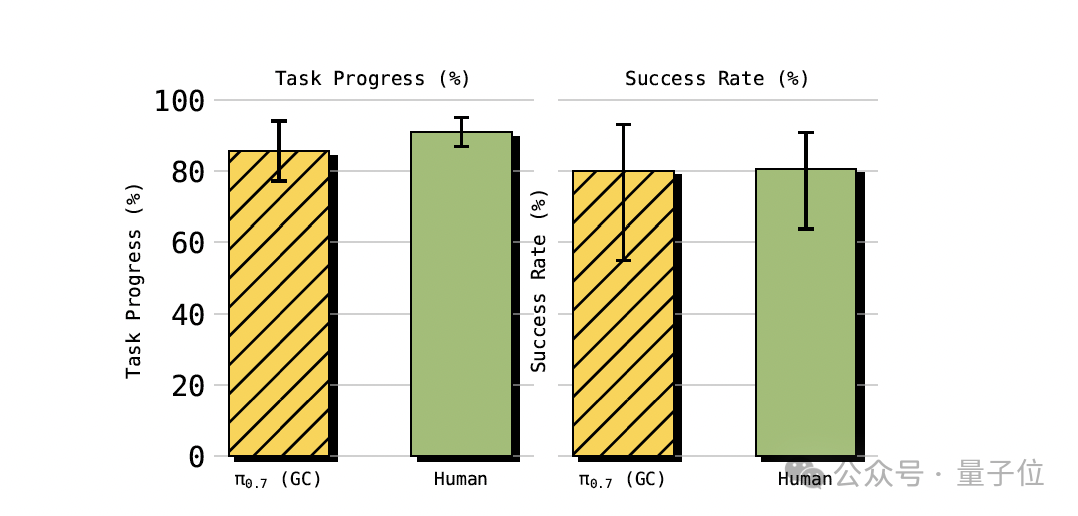
此外,π0.7 自主摸索出了与源机器人完全不同的抓取策略:
人类操作员在源机器人上使用倾斜夹爪贴住桌面抓取,而π0.7 在 UR5e 上采用了垂直抓取,因为这更适配 UR5e 较长的手臂运动学特性。
组合任务泛化:
用空气炸锅做红薯、烤贝果、按下按钮、用抹布擦耳机和尺子、拧旋钮和桌面风扇,这些任务在训练数据中均未出现过。

这并非简单的任务增量,而是机器人首次像大语言模型那样,从训练数据中涌现出新能力。
正如 Sergey Levine 所言:
一旦模型越过阈值,从“只能做收集过数据的事”转变为“开始重组出新事”,能力将随数据增长呈超线性提升。
论文中还揭示了一个反直觉的实验结果。
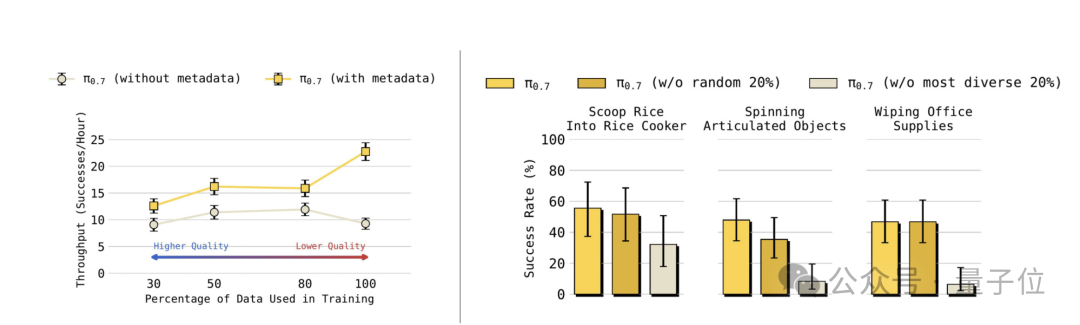
研究将叠衣服数据按质量分为四档:前 30%、前 50%、前 80%、全部数据。
随后训练两个版本的π0.7,一个加入元数据(标注质量、错误、速度),另一个不加。
结果颇具启示性。
不加元数据的版本,数据越多,性能越差——因为低质量数据干扰了模型。
加入元数据的版本,数据越多,性能越好——即便平均质量在下降。
这意味着具身领域过去几年致力于的“数据清洗”,可能是一个伪命题。
只要模型知晓每条数据的质量标签,它就能自主决定学习内容与筛选标准。
垃圾数据不再是废料,而是带有 quality=1/5 标签的有效信号。失败数据也无需丢弃,而是告知模型何种操作会导致失败的反面教材。
过去业界小心翼翼地挑选演示、删除失败案例、清洗数据。π0.7 表明,无需清洗,只需告诉模型哪些数据是“脏”的即可。
π0.7 是一个 5B 参数的模型,架构分为三部分。
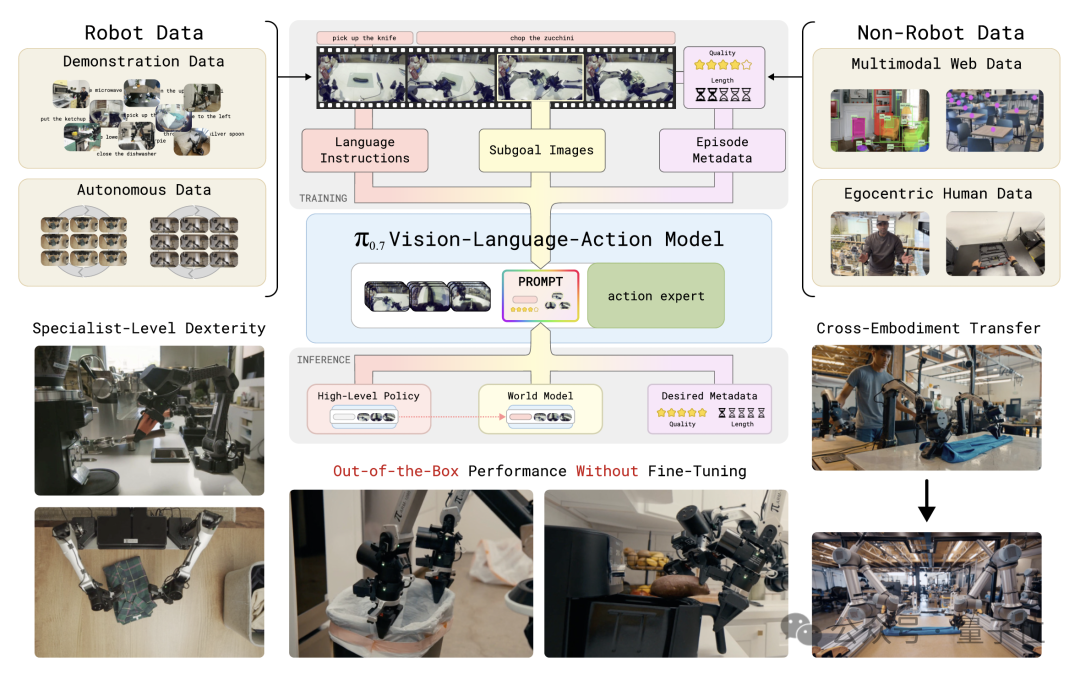
- VLM 骨干:4B 参数的 Gemma3,负责视觉与语言理解。
- Action Expert:860M 参数的 Transformer,利用 flow matching 生成连续动作块,支持 50Hz 高频控制。
- World Model:基于 14B 的 BAGEL 图像生成模型初始化,负责为π0.7 描绘未来几秒的预期画面。
在推理过程中,模型输入包含:4 路摄像头画面(前视 + 双腕部 + 可选后视)、每路 6 帧历史画面、机器人关节状态、任务指令、子任务指令、元数据,以及 World Model 实时生成的次目标图像。
输出为一段 50 步的动作块,实际执行 15 到 25 步,随后推演下一段。
此处或许有人会问,π0.7 内置了 World Model,是否意味着与世界模型派系融合了?
答案是一半一半。
世界模型派的核心在于让模型学会模拟物理演化:给定动作,预测世界变化。Policy 基于此预测进行决策。
π0.7 中的 World Model 并不执行此功能。它仅负责一件事:将任务指令翻译为成功那一帧的视觉画面。不预测动作后果,不模拟物理规律,不参与决策链路。
它是一个消歧器,而非规划器。
借用世界模型派的技术武器,完成了一件非世界模型派构想的任务。
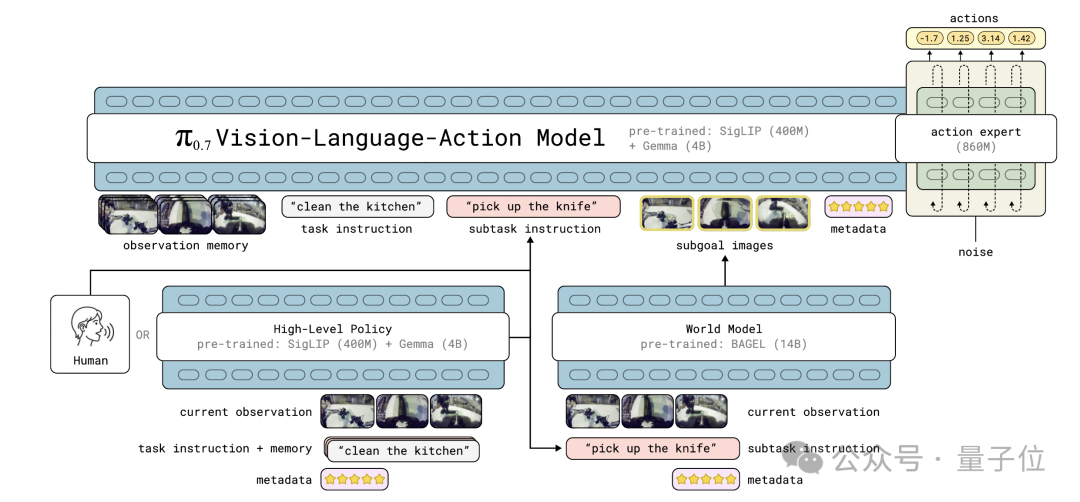
此外,π0.7 建立在两篇前作基础上,继承了π0.6 的架构底色,以及 MEM 的多尺度记忆编码器(短期视频记忆 + 长期语义记忆)。
训练上采用了知识隔离(Knowledge Insulation)策略:
VLM 骨干使用 FAST token 进行 next-token prediction 训练,Action Expert 的梯度不回传至 VLM。如此,VLM 从互联网习得的语义知识得以保护,免受机器人动作数据污染。
但架构并非π0.7 最重要的贡献,论文中明确指出:
我们的贡献并非提出新架构或模型设计,而是一套让 VLA 能够利用更多样化数据源的方法论。
在π0.7 问世之前,具身圈最受瞩目的仍是英伟达去年借助 Cosmos 掀起的世界模型风潮。
让机器人先学会想象未来,再去操作现在。
这一路线看似符合直觉,人类不正是如此行事?闭眼构想动作,再动手执行。
从 2025 年至今,这条路线吸引了最多的关注与投入。
今日,风向或许又将转变——VLA 强势回归!
谈及 VLA,Physical Intelligence 无疑最具发言权。
2023 年,PI 联创Karol Hausman、Sergey Levine、Chelsea Finn三人在 Google 研发 RT-2 时,便押注了一个判断。
VLM 可直接控制机器人,无需先学会想象世界。
这意味着,无需让模型预测下一帧画面、无需脑补物理规律、无需建立内部世界模拟器。
直接使用已见过互联网的 VLM,接入动作头,端到端训练即可。
从 RT-2 到π0.7,实质上仅历经两代 VLA 架构演进。
第一代是 RT-2,将机器人动作离散化为 token,融入 VLM 的 next-token prediction 中。
虽能动作,但控制精度有限,且自回归预测生成速度慢,难以匹配 50Hz 的高频连续控制。

第二代由π0 开启,为 VLM 接入专用的 Action Expert,利用 flow matching 直接生成连续动作块。

中间那些模型——π0.5 的开放世界泛化、π0.6 的 RL 自我练习、MEM 的多尺度记忆——
均未改动这一基座。皆是在 VLM+Action Expert+Flow Matching 这一结构上叠加能力。
π0.7 亦如此。架构上与π*0.6 无本质差别,其增量在于 Prompt 的多样性。
这便是论文中称“我们的贡献不是架构”的原因。
但,更有意思的是另一位关键人物。
Lucy Shi,斯坦福博士生,师从 Chelsea Finn,π0.7 的核心作者之一。

她在社交媒体上分享了一段坦诚的经历。
此前,她追随朱玉可、Jim Fan 在英伟达从事世界模型研究。

她的押注与 Karol 等人相反:
世界模型将是关键钥匙,在任务泛化上显著超越标准 VLA 方法。
起初,结果似乎支持这一假设。她获得了惊艳的组合泛化能力,机器人能遵循未见指令,完成训练数据中没有的任务,并从其他机器人和人类视频迁移。
但奇怪的事情发生了。
他们用来对比的 VLA 基线,一直在变强。
随着数据积累增多,VLA 越来越强,直到某一日,VLA 基线也开始展示组合泛化信号。
而且,VLA 的方法简单得多。
面对这一问题,Lucy 感到无奈:
当你的基线吃掉了你的研究假设,你能怎么办?你写一篇论文,去搞清楚基线为什么这么强。
那篇论文,便是π0.7。
从行业视角来看,π0.7 的出现标志着具身智能数据范式的重大转折。过去,数据质量被视为模型性能的上限,团队耗费大量精力进行数据清洗与筛选。π0.7 证明,通过元数据标注引入数据质量信息,模型自身具备了对低质量数据的免疫与利用能力。这不仅大幅降低了数据收集与处理的成本,更为大规模机器人学习打开了新的可能性。
未来,随着多模态大模型与机器人技术的进一步融合,我们或许将看到更多基于通用架构的具身智能体,它们不再依赖特定任务的微调,而是通过广泛的经验积累与元数据引导,实现真正的通用与泛化。这不仅是技术的进步,更是机器人迈向自主化、智能化的关键一步。






